The 4xu.2 is meant for use with a muxing backplane. 1-2 nvme +24 spinning rust. So you can have fast and slow tier storage
2 Likes
It is (Had to restart due to disaster recovery tests)
It’s weird, I hear quite a few complaints, but my OPNsense boxes have always been really well-behaved. I’m sure your issue is valid, I’m just usually not that lucky.
If it hadn’t just had a major release, I would be able to post similar uptimes.
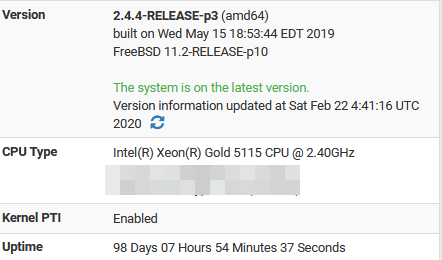
Curious why you blurred out cpu details?
1 Like
Lol when they had that BSD thread I think my uptime was over a hundred days.
I only need to reboot my router like 2 or 3 times a year.
1 Like
OPSec. Not “my” CPU, no details. Paranoid? Maybe. But after seeing targeted attacks after HW details became available: Better safe than sorry.
It was something like that before the reboot. Doing disaster recovery about once a year, so highest uptime is usually upwards of 200 days. If there are no patches in the meantime. That is why I almost always recommend pfsense. The good experience with it.
2 Likes
Yeah mine are only rebooted for upgrades.
1 Like
Ok I was just concerned.
Since I use the SG-3100 a quick Google reveals all the specs so I don’t hardly bother.
Lol I wonder how long my Linux boxes would last if I wasn’t constantly tinkering with them.
2 Likes
At my old job there was this really old IBM workstation that ran AIX version 3 and it had an uptime of 18 years before it died.
I wish I got a picture.
1 Like
Yeah, I wonder too sometimes. Maybe I set one up on old HW without network and check it once a year to see how it is doing 
2 Likes
Anyone know of a way to download AWS IAM policy documents either from SDK or CLI?
Looking to modify managed policies in a tool.
The Gentoo box I was using prior to moving the firewalling stuff off of it hit 228 days once. It has an uptime of 93.4% over the past (almost) decade (started keeping track in September 2010). Do note that I used to shut it down when going on holiday which put quite the dent in the percentage 
Not sure if it then got rebooted for a kernel upgrade or due to a power failure. But I honestly see no reason why it wouldn’t just keep running if nothing breaks, and given how the thing’s been running fine for like 10 years now, well…
Yes if one of the subcommands returned the litteral policy document and not meta data about the document.
Hm, sorry, couldn’t find anything else. There’s the reason I failed my AWS cert last year
i can’t get some of my VMs to see my unraid server. can i add a forward DNS entry on the AD server for the unRaid server? would that even help since they can ping the unraid? it’s only a simple file share.
You can add whatever dns records you want to AD so just give your unraid an A record.
Thought I’d give you all a glimpse into my day to day. Those in the industry can cringe with me. Those who aren’t there quite yet can possibly glean some knowledge. I’m not going to give too much insight into our environments because it’s internal stuff, but here’s what you need to know:
All our instances are on a firewalled network that is only accessible via a bastion instance. Bastion gives access through ssh proxy commands to everything else.
Without further adieu, the incident report:
Incident report 2020-02-27.1: 220-qa Kafka node 2 in failure condition.
Initial concern logged at 13:55 PST, 2020-02-26, devops team not notified.
Pinged for investigation at 11:30 PST, Initial response at 11:33 PST.
Initial investigation finds Kafka finding unknown directory “data” in it’s log dir, “/mnt/data”
Further investigation finds that /mnt, /mnt/data and /mnt/data/data all have the same directory structure. Developers have been trying to get the instance back up for 12 hours now. Assume kafka has been started with wrong configuration.
Proposed solution 1: delete /mnt/data/data and re-apply kafka ansible script to ensure config consistency.
Proposed solution 1 attempted and failed. “Cannot delete: /mnt/data/data (Device or resource busy)” 
Additional investigation needed.
Okay, check that the vdisk still exists:
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
nvme0n1 259:1 0 8G 0 disk
└─nvme0n1p1 259:2 0 8G 0 part /
nvme1n1 259:0 0 500G 0 disk /mnt
good, check mounts to ensure there is no incorrect flags:
$ mount | grep /mnt
/dev/nvme1n1 on /mnt type xfs (rw,relatime,seclabel,attr2,inode64,noquota)
/dev/nvme1n1 on /mnt/data type xfs (rw,relatime,seclabel,attr2,inode64,noquota)
Well then. That shouldn’t be like that…
Investigate fstab:
UUID=[redacted] / xfs defaults 0 0
/dev/nvme1n1 /mnt xfs defaults,nofail 0 2
Okay, looks like someone didn’t know where the fs needed to be mounted.
Solution: umount -R /mnt && mount -a, attempt to start kafka.
Kafka now running.
ZooKeeper not detecting node kafka2.
found nodes: [1,3]
Initial investigation finds that zookeeper is not detecting kafka node 2.
Kafka 2 assumed up but not in good state. Logfiles find:
ERROR [Log partition=[redacted]-10, dir=/mnt/data] Could not find offset index file corresponding to log file /mnt/data/[redacted]-10/00000000000000000001.log, recovering segment and rebuilding index files... (kafka.log.Log)
ERROR [KafkaServer id=2] Fatal error during KafkaServer shutdown. (kafka.server.KafkaServer)
java.lang.IllegalStateException: Kafka server is still starting up, cannot shut down!
Proposed Solution: Stop kafka, clean kafka data directory, start kafka, rebuild data from other replicas.
Directory cleaned, service started.
Current Status: replicas being rebuilt.
Time To Resolution: 22 hours, 44 minutes (since taking over: 1 hour, 13 minutes)
Relevant XKCD:

Additional non-critical concerns to note:
- kafka instance not accessible through bastion. Must proxy bastion -> manager -> kafka. This is not in line with terraform, other environments or previous policy.
5 Likes
Who the fuck mounts all of their hard drives in the same directory with the same name. How did it take a day to figure out that was the issue and resolve it? Was the ticket just sitting on the board for 12 hours because people were scared to take it and be responsible for the issues that may come after investigation?
Sorry this sh*t gets me angery.
1 Like