I feel so powerful
sigh
QoS section of the 2960X switch configuration guide. I’m auditing QoS on the network since we switched from phones that can use Cisco AutoQOS to SIP/SFB/Teams devices. QoS rules need to be different.

Need to go through our devices end to end. On all sites. Switches and routers. 4500s and 2960Xs have different QoS command-set. Yay. 
These things got rolled out during work from home, circumventing regular change management, pushed through by the CIO without my review or approval. And now we have call quality issues. Shock horror!
3 Likes
Lol, see you next year.
2 Likes
mount -vv -t nfs4 -o sec=krb5 knfs.example.com:/mnt/new /mnt/clientmnt/
mount.nfs4: timeout set for Tue Sep 1 22:26:23 2020
mount.nfs4: trying text-based options 'sec=krb5,vers=4.1,addr=192.168.9.24,clientaddr=192.168.9.21'
knfs.example.com:/mnt/new on /mnt/clientmnt type nfs4 (rw,relatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=krb5,clientaddr=192.168.9.21,local_lock=none,addr=192.168.9.24)
1 Like
I don’t think it’s going to be quite as bad as that.
We actually have a mix of devices, but everything seems to be tagging its traffic via DSCP markings before it hits the switch. So that’s a start, at least. Well, except for the SFB pool itself. SFB doesn’t set QoS on its traffic by default. Nice. The MS QoS documentation for it is hot garbage. In theory I think it is a powershell one liner to turn it on if you’re running the default ports, but the SFB 2019 doc doesn’t state that and the old docs for it use different port ranges…
However the switch ports aren’t trusting markings by end user devices (only trust device Cisco phone - and we aren’t running Cisco handsets at the moment so switch says no), and now we’re doing a lot more stuff over the wan.
So I think my strategy will only need to be
- make the switch trust the COS/DSCP markings from the end devices
- make sure anything COS marked gets re-marked with DSCP so it can cross subnets through a router (COS markings get lost as they’re layer 2)
- make sure that the routing devices re-mark and priority queue the important traffic as required
- make sure that the policy maps on all the Cisco stuff are adjusted to either just reference the DSCP marking and/or classify the relevant SFB ports as important and priority queue them
- repeat for the 30-40 sites we have
- ignore anything non-cisco router/switch or otherwise retarded and say “not supported”
Given we’re mostly not bandwidth starved at all I think I’ll get 95% of the way there by ensuring priority queues are running and forwarding ef tagged traffic ahead of everything else in the queue. We have plenty of bandwidth.
edit:
Oh did I mention, I don’t have a test lab for this? Bit hard getting a lab of SFB, 1000 users, mis-matched Cisco gear, a bunch of wan links, etc.

1 Like
Anyone here use Consul?
For the longest time I thought HashiCorp was an overhyped marketing train. Sometimes I still think that.
But Consul is 100% worth its weight in adamantium. Our deployments have becoming significantly easier because of this, and we have a self service tool to manage and create keys for applications or services.
Absolutely vital in today’s world of DevOooops, SRE, Self-Service, PaaS, etc.
1000% recommend.
I have a client that is going permanent WFH and they’re asking me about forwarding an office number to several employees. This is not something I’m familiar with at all. What are my options?
Ideally, I’d want something that can be used on laptop and smartphone.
Looking at Ring Central currently.
After getting stockholm syndrome for Terraform, I looked at Consul and decided I didn’t want to get involved in another toxic software relationship.
I like all my toxicity to be in wetware.
Given a choice, I’d take Consul over Terraform. But I don’t have to make that choice, so I use both  I also use Vault.
I also use Vault.
I think this is more relevant for the Dev Mega Thread, but this is too good to not share.
Local Kubernetes development/deployment that doesn’t require spinning up 19 virtual machines or using the running diarrhea that is Minikube.
2 Likes
does each ESXi host need 2 physical NIC connections to properly setup HA/DRS? or would my single 10G connection on each be ok?
EDIT: digging around , i think i see problems as to why my vmotion may be so slow.
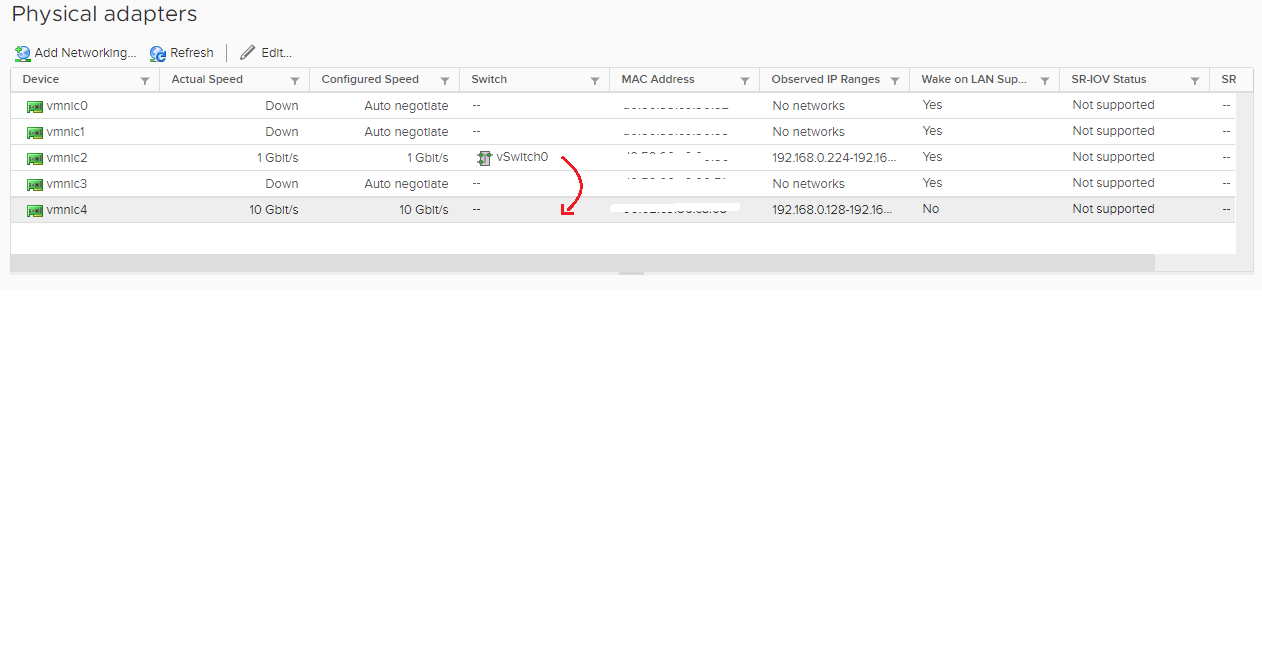
this ain’t right
The vmbr or vSwitch are virtual network devices.
What you are supposed to do is configure multiple physical adapters in fail-over and then assign those underneath the virtual switch for redundancy.
I use Proxmox but that process should be the same.
1 Like
No, you can do HA across one physical NIC, but you’d really want more so your Vmotion/other traffic doesn’t interfere with iSCSI/NFS/regular VM traffic.
The way I set up my boxes (in UCS chassis) are like this:
- 2x 10 GbE physical NICs bound to a single vSwitch in active/active config
- above are trunks (into UCS chassis fabric)
- UCS chassis fabric has LACP ether channel to physical switch
- virtual networks / vmkernel ports set up on VLANs on that single virtual switch
Assuming not using call manager? Also forwarding is a bit of a pita pretty sure if i remember it uses two line (1 in and then 1 to hairpin out)
well i’m out of 10G ports on the switch as i only have 4x 10G ports. i have 1g NICs. would management just to go over 1g and vmotion and vm network traffic over 10G?
that way some stuff could be separated? maybe i might get a small 10G switch in the future.
EDIT: the entire network is a single layer2+ switch and an untangle router.
You running VLANs anywhere? What storage are you using? Are you saying 4x 10gig on the hosts, or is that the limit of your switch?
vMotion will work over 56k modem apparently (recall somewhere at VMware tested it way back) but you want it happening over 10 gig if possible. HA itself is just an election process where the hosts sort out who’s up and who is the HA master; HA doesn’t need much bandwidth at all (and will even work if your vCenter is down). It’s vMotion that consumes a lot - that and any network storage you have.
HA is pretty dumb and nothing to do with vMotion really. Literally all it does is communicate host to host to monitor that hosts are running and fire a failed host’s VMs up on the host where they will fit according to the HA block size.
DRS doesn’t use traffic much either, again it’s just a monitoring setup to check load on each host. It then kicks off vMotion to do the work if required.
When I said above you needed multiple NICs, that’s so that any specific host to host communication won’t flood your single NIC.
Every vSphere I’ve configured so far I’ve just used one vSwitch with multiple VLANs on it, with multiple ethernet adapters in active-active config for it, but they’ve always had same speed NICs in them.
If you have a mix of 1G and 10G, I’d split the 1G adapters off to a different vSwitch and run your management (and possibly user access - especially if you can team 1G adapters as most users will only have 1G or less in their box and unlikely any significant number will hit it at full speed concurrently) over that.
If you’re running network storage (iSCSI/NFS), get that on 10G along with vMotion as a priority and split user access, management, etc. off on the 1G vSwitch.
Storage and vMotion really, really benefit from 10G, and in the case of storage it isn’t just throughput, it’s also latency - the line/signalling/clock rate on a 1G interface is particularly limiting for iSCSI especially. Every iSCSI command needs to go over the network and there’s only so many ethernet frames per second…
User access? outside of file copies, most end users won’t see any difference between 1G and 10G. Hell, outside of file copies, most of my users see barely any difference between 1G and 100M
Also, is this home-lab/small office or something larger?
1 Like
24 port switch with 4x 10G SFP ports i run 4 servers and one more i haven’t fired up yet as i don’t want to melt the outlet.
2 ESXi servers with dual port 10G NICs (they also each have a several 1g ports)
1 ESXi NUC to host AD/DNS and VCSA 1G NIC only (easy to keep up on UPS during power outages)
1 unRaid with dual port 10G NIC and several 1G ports.
save for 1 esxi host i slapped in 10G connection and called it good. maybe i should a 1G connection to both ESXi servers and put managment/HA over the 1G?
i didn’t want to dedicate vmotion to ONLY the 10G and nothing else. i’d loose speed from local server to server data store and my unraid. the unraid gets going over 1Gbps when the caching kicks in.
sounds like i need to get the esxi server connected via the 1G as well. THEN i need to learn how to setup the ports and vswitches ???
EDIT: i’d called it a leveraged home lab. i use to host stuff. like game servers, TS3, and soon nextcloud since my unraid is pushing 50tb. i also have nvidia GRID and 3D accelrated VMs.
Im calling BS
Ive seen vmotion fail on a 10Gb link, the VM in question was a busy 1-2TB database, but after about 8-10 hours “moving”, it killed the vmotion and powered off the VM.
Was pretty pissed about it powering the VM off.
…
that happened back on version 6.0
I’d hope they would have fixed whatever caused it by now?
Hmmm maybe memory hazy and it wasn’t vMotion. I do remember seeing a post (maybe on yellow bricks) regarding transfer of a VM over 56k modem (for shits and giggles, not production) by one of the Vmware developers.
Who knows how big it was though - maybe a copy of DOS
This would have been a LONG time ago - circa ESXi 3 days or earlier.
That sounds like there was some sort of (not normal) issue.
Vmotion doesn’t normally kill/power down VMs if Vmotion fails, or if you cancel it.
I’d be pointing fingers at a bug, storage issue or the network shit the bed at some point halfway through which ended up killing the source VM (which in turn killed the vMotion, rather than vMotion killing the VM). In 10+ years of running vSphere, I’ve never had it do anything like that.
Storage was xio on both sides.
Had to be a VMware bug