Which is negligible. With today’s prices per TB, I personally wouldn’t bother adding complexity, sacrificing performance or buying new SSD just to save 20 Bucks. Aside from using memory worth a multitude of that to make dedup happen at all. This is why people don’t use dedup → opportunity cost higher than gains.
If you want to do it “for Science”, then consider using a special vdev to store your dedup table and tune zfs parameters so dedup table doesn’t dominate your ARC.
There is no compression on storage spaces? Compression ratio ranges from 1.0 to 5.0 depending on what kind of data you got. If its all highly compressed media files or zip folders, transparent compression is barely worth the cpu cycles.
Database, text files, OS files…those are prime real estate for compression and usually go >2.0
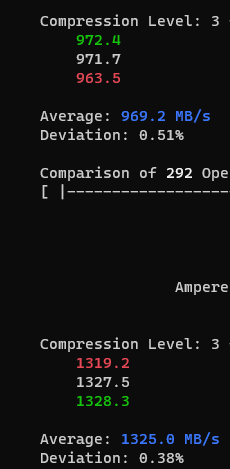
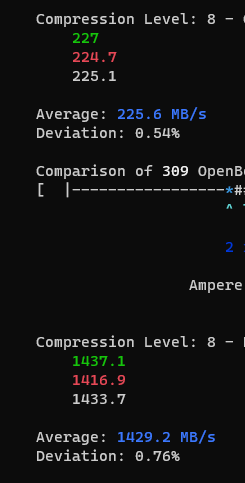
I recommend using zstd. Level 3 is default, but over the last 2 years I realized that my Zen3 CPU can compress zstd-5 and zstd-7 by the Gigabytes per second and I moved most archive-ish datasets to higher compression.
Even with a shitty CPU, lz4 compression is a no-brainer. I can’t think of a machine outside of dual core laptops that would want to disable this for power saving.
All of us like more storage and less space dedicated to redundancy. But if you want fault tolerance and integrity, there is no other option. And ZFS can’t repair stuff if damaged. So whats the point of migration then?
You may get a warning from TrueNAS or whatever software you’re using, but that will work. Data gets striped across all top level vdevs, making it a de-facto RAID0 config. With the disadvantages mentioned above.
No. Because there is metadata and filesystems (very nature of CoW) fragment over time and exponentially so when they approach capacity limits. Recommendation is to not let the pool run >80% of capacity because performance goes downhill very fast. And I’m not talking about write amplification and wasted space yet which will be thing with fixed blocksize ZVOLs.
7.5TB is a naive way of thinking about storage.
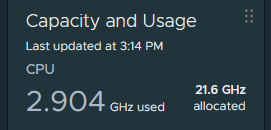
Keyword here is cache. HDDs won’t deliver performance no matter how much you have in whatever config. ARC will make performance happen along with L2ARC for reads and SLOG for sync writes. More ARC is more better.
I’m running with 30GB dirty_data_max and sync=disabled and writes are just wire speed (10GBe in my case) for all intents and purposes. Memory is life 
Memory impact for 500G of L2ARC is trivial for an ARC size of 40GB.
If you need Sync, SLOG is the most efficient use of storage ever. And performance is fairly important to you. Making Sync writes basically async is like 10000% faster writes. Otherwise set sync=disabled to let your memory be the SLOG.
To sum things up and my recommendation:
Don’t use dedup.
Create a pool with the two drives each being a stripe vdev (single). Partition the SSD (better: use namespaces) with 16GB going as a SLOG and the rest as L2ARC and enable persistent L2ARC.
Works.