A couple months ago I started doing some Strix Halo testing w/ LLMs on some pre-production hardware. Recently in some of my spare time I’ve built a harness and ran more rigorous sweeps w/ the latest drivers (Linux 16.15.5+), latest ROCm (TheRock 7.0 nightlies), and llama.cpp. I also focused on a number of the new MoE architectures, as that’s really where these big-memory (but limited MBW) APUs will shine.
All testing was done on pre-production Framework Desktop systems with an AMD Ryzen Max+ 395 (Strix Halo)/128GB LPDDR5x-8000 configuration. (Thanks Nirav, Alexandru, and co!)
Exact testing/system details are in the results folders, but roughly these are running:
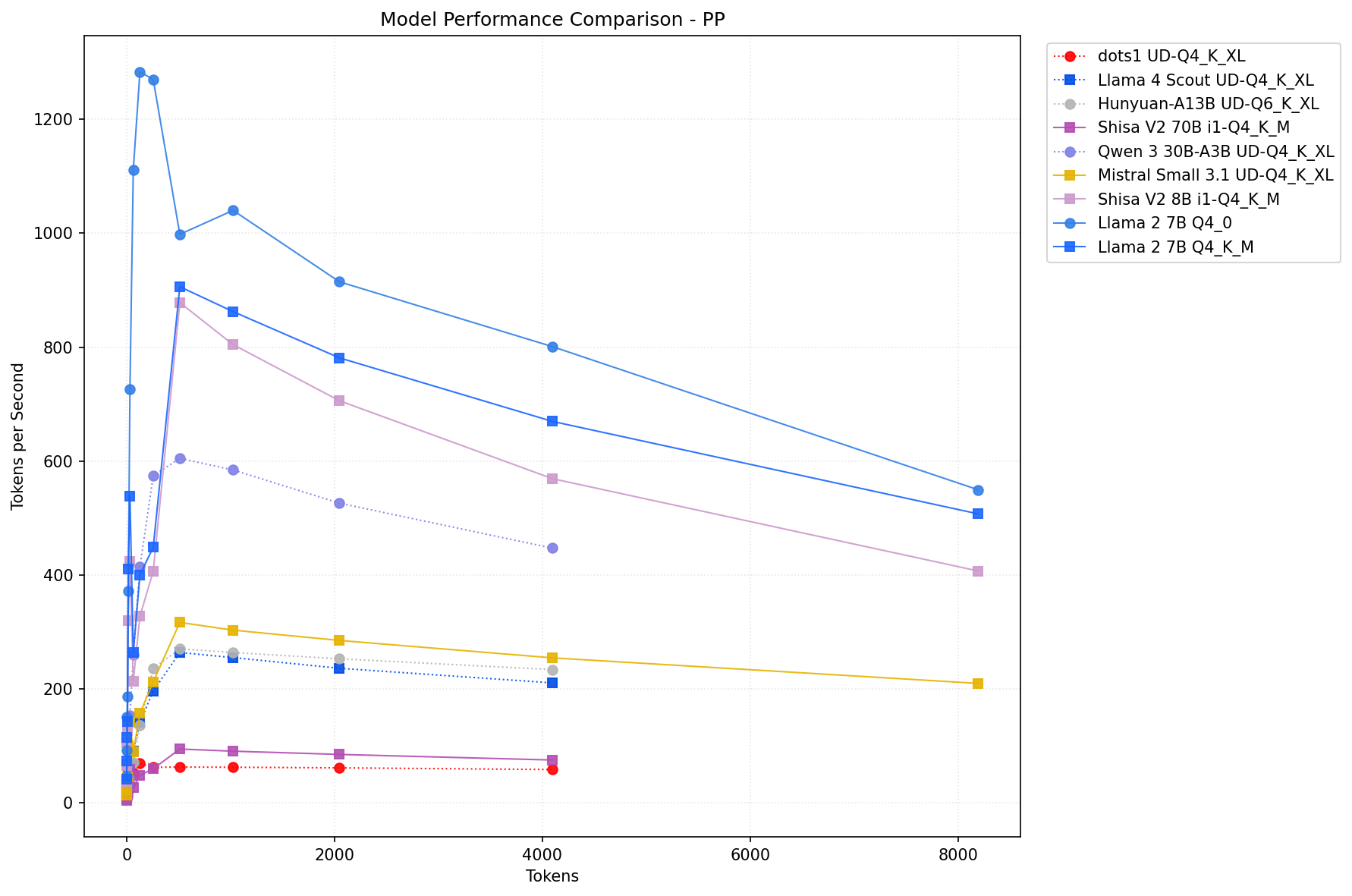
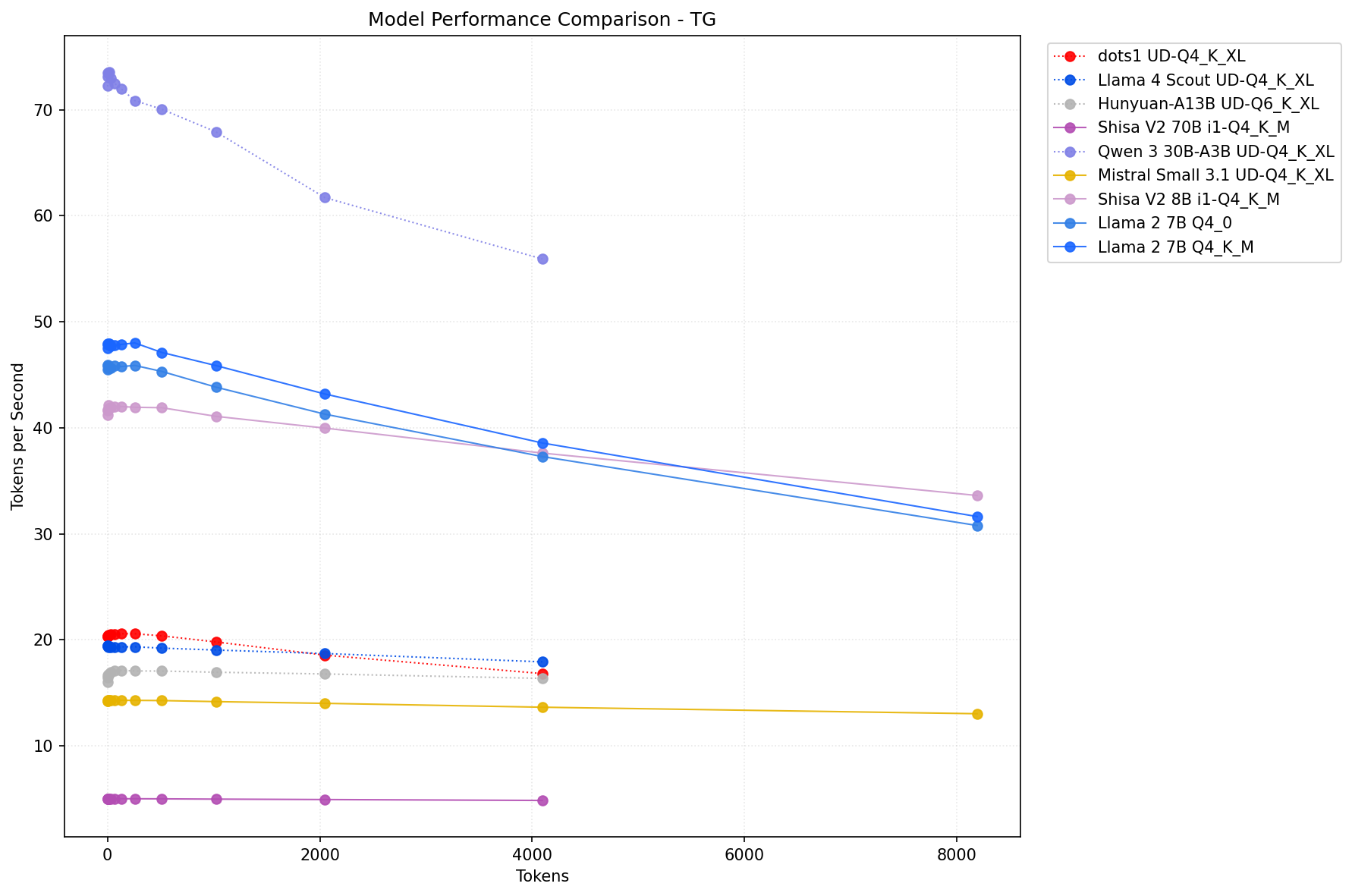
The best overall backend and flags were chosen for each model family tested. You can see that often times the best backend for prefill vs token generation differ. Full results for each model (including the pp/tg graphs for different context lengths for all tested backend variations) are available for review in their respective folders as which backend is the best performing will depend on your exact use-case.
There’s a lot of performance still on the table when it comes to pp especially. Since these results should be close to optimal for when they were tested, I might add dates to the table (adding kernel, ROCm, and llama.cpp build#'s might be a bit much).
Interesting results. Would it be possible to test some even larger MoE models, like the DeepSeek-R1-0528 quant intended for AM5+GPU (which technically does not fit without overhanging into SSD), or maybe a smaller quant of Qwen3-235B-A22B?
Given the sudden interest on very large open-weight models, I wonder if it just had its thunder stolen for not offering a 256GB variant, if that would not throw the prices even further out of all sense, and if it is electrically possible at all.
But to be fair, at the time the design goals of the chip was probably issued, the SOTA of open-weight LLM was likely either GPT-2 or maybe llama-65B, with people clambering through AI Dungeon 3’s UI to have a taste of GPT-3.
Really nice to see that performance has been improving since your last round of benchmarks.
Once again, thanks so much for doing all of those tests! I get really happy every time I see any post of yours here, even before opening up the actual content haha
The GPU used is RDNA3, and even then, 6 month post-release, the gfx1151 kernels continue to underperform gfx1100, so tbt, I don’t think AMD has given all that much thought to local LLMs in general, much less on trends w/ mega MoEs… (hell, it seems to me, until last year they somehow believed they didn’t need any AI workstation cards/strategy at all? )
I agree they’ve lucked a bit into the zeitgeist (Strix Halo basically was just a Mac Pro chip competitor right?) I believe Medusa Halo, if it has 256GB / 384-bit bus / UDNA as rumored is a much more compelling product, but if you want to run large MoEs and have $2K burning a hole in your pocket right now, I think you’re much better off scrounging a cheap/used EPYC system, and using a cheap Blackwell GPU for the processing/shared experts.
To me, a mobile - or at least mobile-targeted - SoC offering more (theoretical) memory bandwidth if not compute than even same-generation HEDT parts is already not quite the natural state of affairs. If the next generation would push it even further, I’d be more interested to see what they’d do with their next desktop platform. An electrically 256-bit + ECC + 40-lane PCIe socket shared by parts offering 128- or 256-bit memory bus width, with or without ECC, and 12-40 PCIe lanes, seemed not impossible. Even more interesting might be what they do with the 64GB/chiplet bandwidth bottleneck, if just to make that 384-bit interface more worthwhile beyond graphics and iGPU compute.
Right now though, if you don’t actually have $2k burning a hole in your pocket or the room & goodwill for a decommissioned server just to deploy these humongous open-weight models locally for whatever purpose, I think cramming an existing DDR5 desktop setup with as much memory as would fit might be the better value proposition, even if you would then also pay for that in memory bandwidth where DDR5-4800 is apparently already a small win in silicon lottery terms.
And - disregarding that the 5090 is “cheap” when compared to the PRO 6000 - until there is a “cheap” Blackwell GPU with at least 24GB of VRAM, there’s not much it might offer over the previous generation offerings in terms of fitting the shared layers without damaging model capabilities and with useful context length, at least right now.
My random thoughts on those looking to build cheap dedicated local LLM hardware:
I think financially atm, it doesn’t make sense for almost anyone to shop for dedicated hardware unless they are doing it as a hobby (eg, take any budget you have and you would almost always be better off paying per token, using free credits/services, or renting GPUs per hour would be better bang/buck) or they plan on running batch inference or training 24/7 (but cost in your electricity cost and the difference may still not be worht it)
If you are looking to buy cheap, there are actually a huge range of options if you’re willing to buy used - eg, when I was shopping I saw tons of EPYC 9334 QS’s on eBay for like $500 - you could get two, slap them on a dual socket 9004/9005 board and just start adding memory; going EPYC is way cheaper than HEDT and not that much more expensive than high end desktop and you get way more PCIe lanes…
There’s usually a tradeoff for how much you want to fight software and how much you want to pay. RTX 3090 is still IMO the goat for price/perf/ootb ease of use, but there are a lot of options on the pita/price curve. That being said, with the upcoming W9700 and Pro B60, a few new options that might be worth looking at more VRAM
For the new big MoEs you don’t need a 5090 btw - you just need to be able to fit usually like 10B or less of shared experts and to handle processing (you get a big boost on pp even w/ 0 layers loaded on GPU memory) - ideally something compatible w/ k-transformers which I think does the best job w/ CPU/GPU interleaving atm
I have some llama.cpp RPC results for those that want to seem some raw numbers and info there: strix-halo-testing/rpc-test at main · lhl/strix-halo-testing · GitHub - IMO using RPC for clustering doesn’t make much sense in practice since basically any model that doesn’t fit on 1 machine (maybe 2) runs too slow anyway, and as mentioned above your bang/buck w/ EPYC is way better, but since people were curious…
I have some updated models, numbers, and perf, including getting 5-10% better pp perf using a tuned profile, and some surprising differences on AMDVLK vs RADV Vulkan depending on OS/build: strix-halo-testing/llm-bench at main · lhl/strix-halo-testing · GitHub - if you have a Strix Halo and are looking for free perf, you’ll want to look at this.
For those keeping track, 3 months ago back in May, pp512 for lllama2-7b-q4_0 was 884 tok/s in Vulkan. Today it’s 1294 tok/s, almost a +50% increase. That’s not bad!
(What is bad is that basically every single model has a different optimal backend, and most of them have different optimal backends for pp (handling context) vs tg (new text)).
@lhl Would you telling me if your bang for buck comments still apply if we’re paying Europe/UK prices for electricity? Secondly I do concede that it’s likely cheaper just paying for Claude code or the like, but I want my own stuff and not have to worry of limits.
My use case will be building apps for Windows, Linux and macOS, mostly in compiled languages.
I think you’re going to need to do calculate that for yourself. Look for some looking for power usage (I believe Jeff Geerling has some measurements for idle etc) numbers. and figure out your usage duty (remember, the power is only going to hit the limits when you’re actively inferencing), and the multiply that out for each system. Any strong LLM (preferably w/ a code intepreter and web access) should be able to help you model it out.
BTW, if you’re concerned about privacy, you can look at API providers like AWS Bedrock, MS Azure, or GCP as they have fairly stringent data privacy/GPDR-following. You can also either rent GPUs from an EU neocloud (Nebius, CUDO, etc) or use one of the more privacy-oriented endpoint providers like Chutes.ai as two other options.
I feel like if I were doing work, gpt-oss-120b would probably be adequate quality but IMO for a reasoning model 15-20 tok/s (speed it drops down to once you get a lot of tokens going is too slow. qwen3-coder-30b-a3b is faster but it’s ultimately still a small model.
It’s quite of a handy backend server that utilize NPU (Strix Point +), GPU (seems like CUDA and ROCm if your GPU support) and CPU. The software is developed by AMD engineers on their free time.
It’s intended to provide a backend for other AI based applications. Plus, of course it has a LLM inteface for us to chat on right out of the box, with models optimized for specific hardware cases (NPU, GPU and CPU).
It’s much easier to use it on Windows (yea, sad face) and NPU option is only available there (extra sad faces).
Don’t want to derail the thread, but maybe there’s a short answer
I’m wondering what kind of setup you have in mind for something like this? I have a 5995wx that I can fully dedicate to AI inference or repurpose it and buy something new/used. My goal is to run qwen3-coder-480 MoE with a big context and get 10-20 tok/s when the performance is fully degraded.
This is super interesting, I thought llama.cpp was better for CPU/GPU inferencing but looking more into k-transformers it seems llama.cpp could still be better for dense models but this other one for MoE which is what I use the most nowadays. Do you know if there are optimize rules for some of the newer MoE models out there? I was only able to find it for Mixtral-8x22b and qwen2-57b-a14b
I’ll check that out thanks!, I didn’t look for deepseekR1, I guess I thought it was too big to even try. I did look for qwen3 235b and llama4 and couldn’t find anything.
I don’t benchmark, but on my GMKtec Evo-X2 minicomputer with AMD Ryzen AI Max+ 395 and 128 GB RAM, I run Ubuntu 25.10, and use LM Studio for LLM stuff, with the AMD Vulkan and ROCm versions of the app/drivers or whatever installed from LLM. Tonight I tried the new NVIDIA Nemotron-3-Nano.GGUF, and it ran the following prompt at 45 token/sec, with 0.29 secs to first output, and a ton of equations in the output. Very impressive, to me at least!
“how difficult should it be to make a time travel machine? Examine the feasibility of time travel using a small blackhole, same golfball sized, who’s output is perpendicular to all 3 spatial planes, and 180 degrees back and 180 degrees forward in the time plane. Stipulate that we capture this primordial black hole in a lab powered by antimatter fusion reactors. Further stipulate the PBH is a Planck-scale remnant that is composed of exotic matter which is why it didn’t break down, which is why we caught it. The PBH would be made of negative energy from the early universe, when the laws of physics were temporarily inverted, of which it is thought that is why the JWST sees red-shifted globular clusters as extremely long bodies that don’t follow normal physics.”