I’m using Windows Server 2022 Standard, so it’s the basic Storage Spaces. The server in question is a Supermicro 221H-TN24R (dual Intel Xeon), but I can also recreate this same issue on different model servers such as the Supermicro 2114S-WN24RT (single AMD EPYC). I’m using enterprise Kioxia and Micron U.3 NVMe drives in these arrays…
I have three separate arrays setup on these servers:
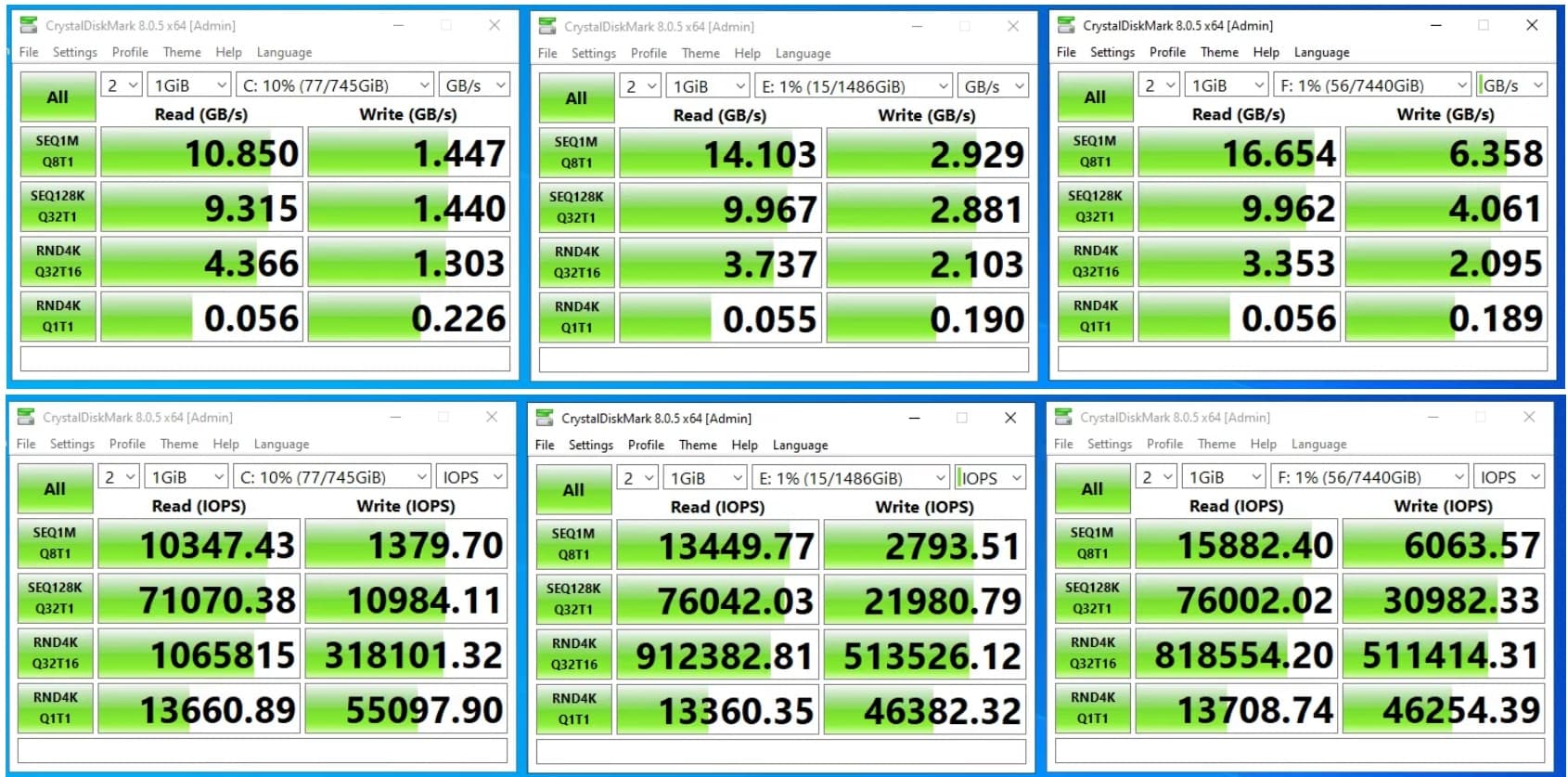
Array1/C:) 2 x 800GB in a mirror configuration
Array2/E:) 4 x 1.6TB in a mirror configuration with column setting of 2 for a single stripe
Array3/F:) 10 x 1.6TB in a mirror configuration with a column setting of 5 for multiple stripes
All arrays were configured with default interleave size (256KB), formatted to ReFS (4KB allocation). The single only change is the columns.
CrystalDiskMark tests, with the NVMe SSD option selected, show improvements of performance between Array1 and Array2 in write IOPS and write GB/s for the most part, but small or even worse performance on Array2 with random reads and only slightly better on sequential reads.
But the real surprise is between Array2 and Array3. Despite many more columns/stripes, Array3 barely has any improvement in performance (if not worse) over Array2 in all read GB/s and IOPS, and no improvement in random write GB/s and IOPS.
Shouldn’t there be quite a large gap between Array2 and Array3 in performance across all metrics? These aren’t in a parity setup, they are striped-mirrors, much like a RAID-10, so I don’t think I’m running into the issue with interleave and allocation sizes that plague Storage Spaces when using the parity option.
Screenshot of results attached.