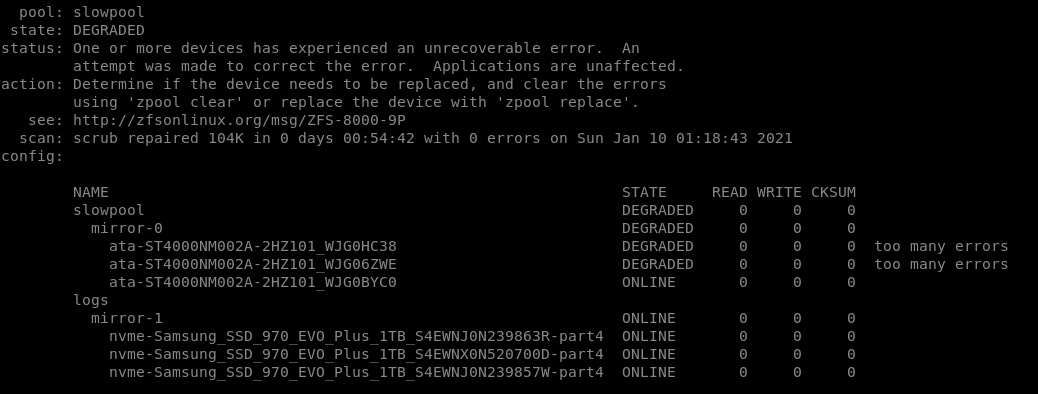
What has me baffled is the fact that two of the HDDs have a “too many errors” status message, yet there are no read, write, or checksum errors listed in the command output. Checking the status of the two offending drives with smartctl, they both pass the self-assessment test.
This is not the first time these warnings have appeared either. Last time I read the article whose URL is listed in the status output (ie this one) and simply cleared the drives using zpool clear.
Now that the warnings are back however, I am feeling much less sanguine about things. Should I just run out and buy another two HDDs, or is there something else going on here?
Full disclosure - I believe this problem may be caused by the fact that these two drives lost power at some point several months ago when I was messing about inside my PC and one of the PSU power cables became loose - a situation that was promptly fixed as soon as I realised what had happened.
The first thing to find out is which drive maybe the offender. It looks like its two of your SATA drives. See if they are throwing smart errors on each.
From there maybe we can help shed lights on the issue. Something I do to drives beginning to show errors is I do run a smart sector check. Sometimes this can relocate sectors and fix things all buy itself… Use the extended test.
But first find out what the errors actually are.
For future reference you should script this check to run regularly. Output it to a status log or rsyslog server and have it alert you to errors. A basic script just to check can be like mine
#!/bin/zsh
# ZFS Pool Check and SmartCTL readout script
# Make sure you install the smartctl package first! (zypper in smartctl)
echo 'Checking for root priveledges'
if sudo true
then
true
echo 'Ran as root check complete'
else
echo 'Re-run this script with superuser priveledges'
exit 1
fi
echo 'Running smartctl health check'
for DISK in /dev/sd[a-z] /dev/sd[a-z][a-z]
do
if [[ ! -e $DISK ]]; then continue ; fi
echo -n "$DISK "
smart=$(
sudo smartctl -H $DISK 2>/dev/null |
grep '^SMART overall' |
awk '{ print $6 }'
)
[[ "$smart" == "" ]] && smart='unavailable'
echo "$smart"
done
echo 'Running zpool status output'
zpool status -v
echo 'Complete'
The three spinners are Seagate 3.5" 4TB Enterprise Capacity (Exos) SATA 6Gb/s, 7.2K RPM, 256M, 512e/4kN drives, model no. ST4000NM002A. These were purchased in May of last year and have been on 24/7 since then.
I do not suspect dual drive failure then. Especially with smart pass.
Smart can lie sometimes, but ehhhh… Seems far fetched here.
What you can do is grep your kernel messages for errors on block devices. See if that gives some insight. Additionally, swapping devices and ports around would be an interesting experiment if you have access to the machine. My suspicion is that you may have a bad cable or two and it causes occasional errors on the drive that is a non-data related error that zfs may be detecting. I’m not entirely sure why the degraded status is popping up without an error count.
Yeah, that is what had me perplexed as well. Because the machine is sitting right next to me, will try plugging the two drives into different SATA ports and see what happens. I will need to clear the two drives in ZFS, and then its a matter of seeing if/when the degraded error reappears. Might happen straight away, might not.
EDIT
I have plugged all three spinners into different SATA ports using a different set of cables, and cleared the errors. Will keep an eye on it over the next few days and let you know what happens. Fingers crossed.
Check: are these SMR drives (they look like 4TB?)? If so, I’d be backing up the pool as a priority (and limit writes to it!), as the reason they failed may have been due to incompatibility with ZFS (i.e., ZFS has timed out and declared the drive dead while they were doing a re-shingling operation).
if this is the case, the remaining drive may well also fail. Would also explain the sudden double drive failure.
So its now been 48 hours and there are no errors or other untoward messages from the pool, so it definitely appears the HDDs are fine and that it was an issue with either the motherboard SATA controller or the SATA cables.
I could spend time figuring out which one, but at this stage I am going to heed the “If it ain’t broke, don’t fix it” adage, and will address this issue in the future if/when when I need to throw more HDDs into Hex.