Working on a little project here and looking for some pointers if anyone can help. Trying to figure out a way to crawl a website and find every page that has a hyperlink to a specific domain. The goal here is to remove every instance of the link from the site. I have access to burp suite free but having some trouble finding any how-tos or training.
linux:
lynx -dump -listonly | grep "search_term" > list.txt
output:
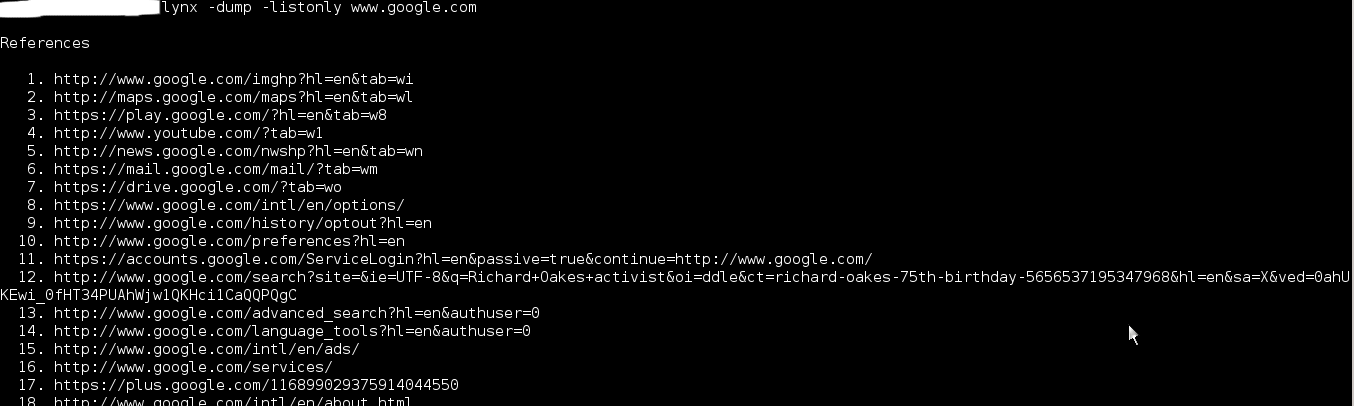
without -lisstonly:
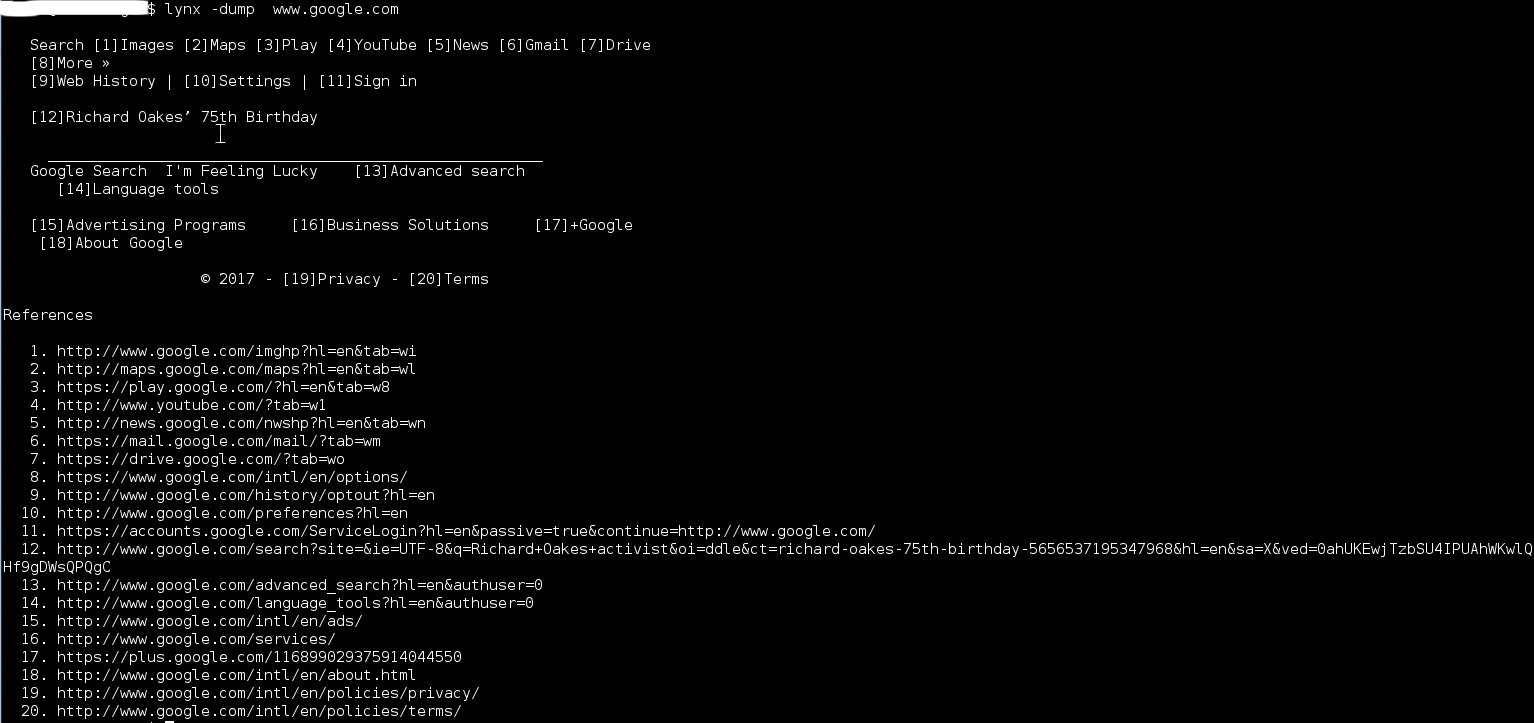
commands:
lynx -text only web browser
-dump dump output to standard output and exit
-listonly only show links
links.txt -redirects stout to a file
links are numbered so you can find them in the web page that is outputted
lynx can be installed on linux subsystem for windows.
Will this crawl the entire site or just list the links on one page?
just the specified page. ill look into it more as there is a -crawl option
lynx will not do what you want.
this script probably will .
note: never run a script that you do not understand what it does.