Splitting off the discussion about s6 from the neoflex thread. This thread is dedicated to everything s6.
Explaining a bit on @PhaseLockedLoop’s request, I mentioned that s6-rc takes daemon-tools up to 11.
daemon-tools and runit are pretty similar in nature. So is s6-linux-init.
I’d suggest you read all the link bellow, because I can’t explain all the things as good, but I’ll do a high-level overview.
links
s6: why another supervision suite
s6: an overview
s6-linux-init - tools for a Linux init system
s6-linux-init: why?
s6-rc - a service manager for s6
https://skarnet.org/software/s6-rc/why.htmll
skarnet.org: a word about systemd
The general idea under linux (and most unixes) is that you have 3 layers to the OS start-up process.
- init
- pid 1 (the process that starts the userland up)
- service supervisor
The init part can be handled by anything, init can even be a shell script. This is the piece of code that the kernel first loads up and tasked with the early system initialization. The init can be short-lived and exec into something else after its done its early tasks. This is where s6-linux-init lives. I won’t get into much details here. The only thing I’ll mention is that s6-linux-init launches the s6-svscan process, the PID 1 of an s6-based OS.
The PID 1 is the process that is tasked to handle all long-lived system processes (daemons) and restart them if they die. This is the task of “s6” or s6-svscan. Other tools that would live here after being launched by the init are runit or daemon-tools. The PID 1 is also the place where all orphaned processes go to (and get reaped), but I won’t get into that.
So think of PID 1 like a daemon-lord that constantly spawns daemons after they die. That’s its sole purpose. This must be minimal, be able to handle OOM scenarios and has to be very stable. If PID 1 dies, your whole system crashes.
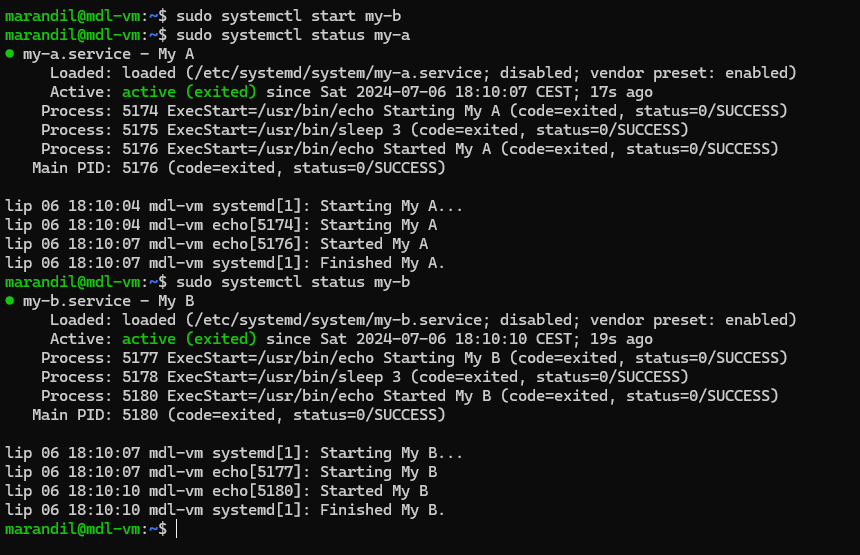
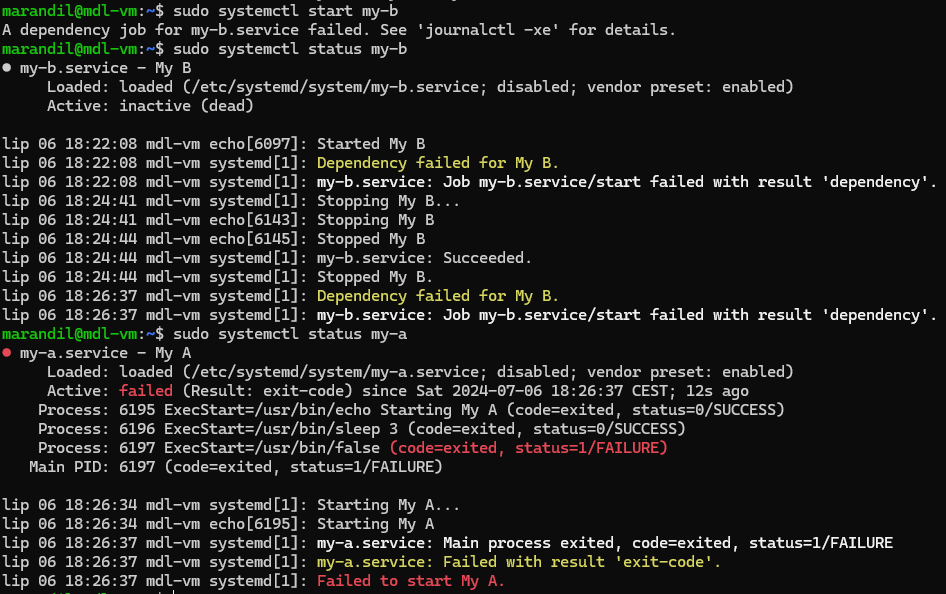
Where the new concept comes into play is the service supervision and dependencies (and that’s s6-rc). It’s not exactly a “new” concept, OpenRC is a service supervisor, but it’s a very serialized one. Sysvinit also had a service supervisor that nobody used. Systemd does service supervision too (via the unit files).
So what the heck’s a service supervision? For that, I’ll have to first come back to PID 1 and explain more about daemon-tools style tools.
So in a traditional daemon-tools-based OS, you have no dependency, all services are started in parallel by PID 1. Services can be scripts and you can handle some checks in the scripts to verify if a certain process is alive before you go into the main service, or sleep if it is not, but sleep is not a good way of handling dependencies.
So if you have sshd that depends on the networking service and they are both started in parallel by PID 1, then sshd will die at least once, until networking is up and then sshd will be up. The PID 1 ensures it gets started every time it dies. This puts strain on your CPU and wastes cycles.
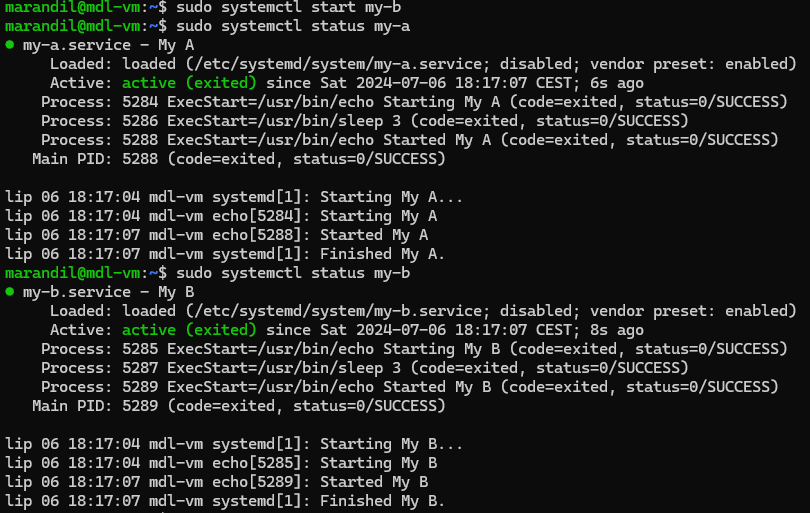
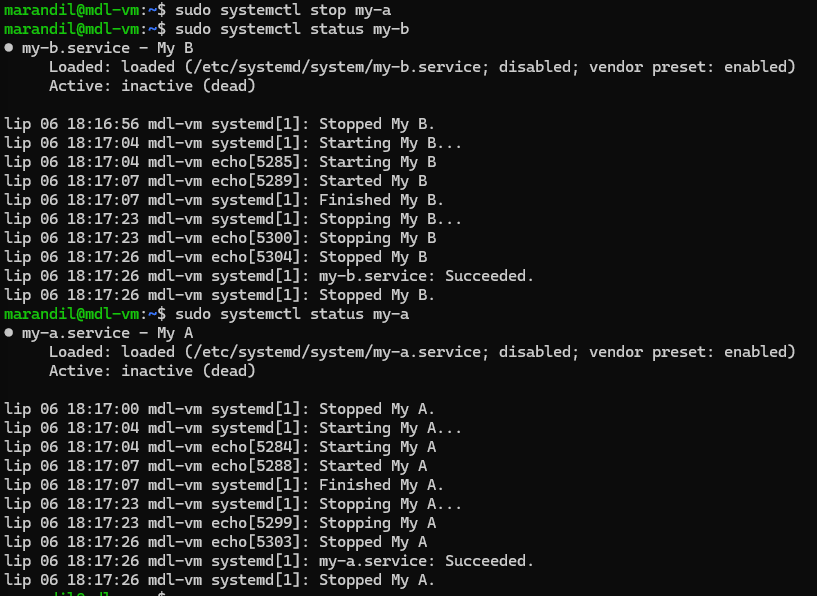
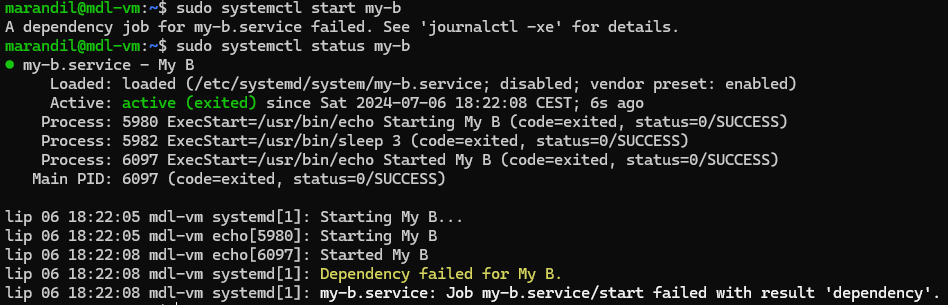
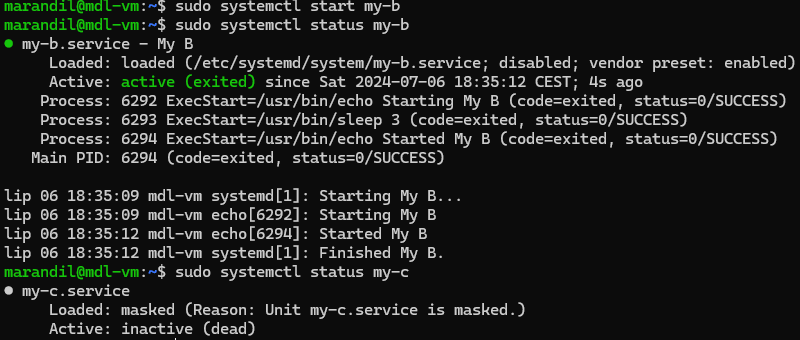
To fix this, you have to be able to tell PID 1 to only start services if their dependencies are met. So s6-rc is the one handling that. Everything starts off with a “down” file, meaning everything has to be down.
The only thing that sv-svscan (PID 1) starts, is the s6-rc service with an argument to start a bundle of services (by default it’s called “default” and it’s what the kernel passes to it - just like you have the “default” runlevel in openrc or runit). Then, s6-rc checks its database for how all the services should start up. It first sees services with no dependencies, like udev, so it removes the “down” file from s6-svscan and thus, udev is started. Once s6-rc confirms udev is up (and not in some weird “starting” state non-sense), then it checks what services depend on udev.
In this case, file system mounting and loading kernel modules depends on udev. But FS also depend on some kernel modules, like zfs or btrfs modules. So s6-rc removes the down file from s6-svscan for the modprobe service. Once this has finished, it removes the “down” file from the FS service, to start mounting the file system.
Traditional PID 1s, like runit and openrc, handle this in runlevels. You must first script your way after the init (init launches “runlevel 1”) to get all your things started up in serial, udev → modprobe → fs and so on. Then the actual PID 1 begins (runlevel 2) which starts everything up (either in serial in openrc or in parallel in runit). For runit, since it’s simpler to explain, it just starts launching everything at once, some things crash, they get started again and eventually you end up with a properly started system.
Does this sound insane to you? Well, it is, but it works. But s6-rc (and systemd) have dependency resolution to prevent things from ever crashing from their dependencies not being up.
So s6-rc kinda removes the need for runlevels in general. After the init starts PID 1, which starts the service supervisor, everything is handled automatically and starts as soon as possible if their dependencies are met.
Systemd solved this issue a long time ago and it’s why it became the de-facto standard on linux. But the way it was done is insane (PID 1 in systemd is huge and wouldn’t really call it stable and the service supervision side is also complicated and poorly thought out - why you’d have an “after” if your service doesn’t explicitly depend on a service? and why you’d have a “requires” if you’re going to start both services in parallel anyway, unless you also use the “after” service definition?).
But as most of you can attest, systemd is heavy and it’s non-portable (can’t run on non-glibc libc libraries and it’s hard to port to different cpu architectures, although most of that work was already done). I’m not here to bash on systemd, we can make another thread for that. This was just as example of how s6 improves on it.
The s6-linux-init is light and only launches the s6-svscan (PID 1) and then the service supervisor begins working on system initialization. And if s6-rc crashes (although chances are very unlikely), PID 1 will just revive it.
The reason I got into s6 was because I needed serious supervision on rebooting linux servers (now that I actually shutdown most of my lab, although I plan to keep stuff up longer once I get some homeprod stuff going). My example, which I complained on my blog on the forum was iscsi.
When the system started, all I had to do was do a process where networking started, followed by iscsid service, followed by a one-shot script that did iscsi-login, followed by mounting a file system, followed by starting VMs or containers. This worked using some service status checks and a sleep loop and for the login script, an infinite after sleep (to make PID 1 believe the “service” is up).
It worked for what it’s worth, but on shutdown, I had no fixed dependency resolution, meaning that everything got killed at the same time, but some services might die earlier than others. If iscsid dies before iscsi-logout, then that’s a problem, we have a hung iscsi connection (that thankfully the freebsd target always handled beautifully). If the file system dies before containers and VMs are shut down first, you get FS corruption (say, a VM was writing something to disk, but got interrupted in the middle by a FS getting unmounted).
That’s how I got a new appreciation for systemd actually (and I don’t mind anymore that nixos uses it, although I wish I could learn how to make the flakes use s6, there’s already “vpsAdminOS” that runs on runit and nix, somehow). I was contemplating whether to switch to nixos on my container box, or stick to something lighter (to allocate as many resources to containers, as I’m running everything on arm sbcs).
Any questions, appreciations or frustrations you have for s6, put them in this thread.