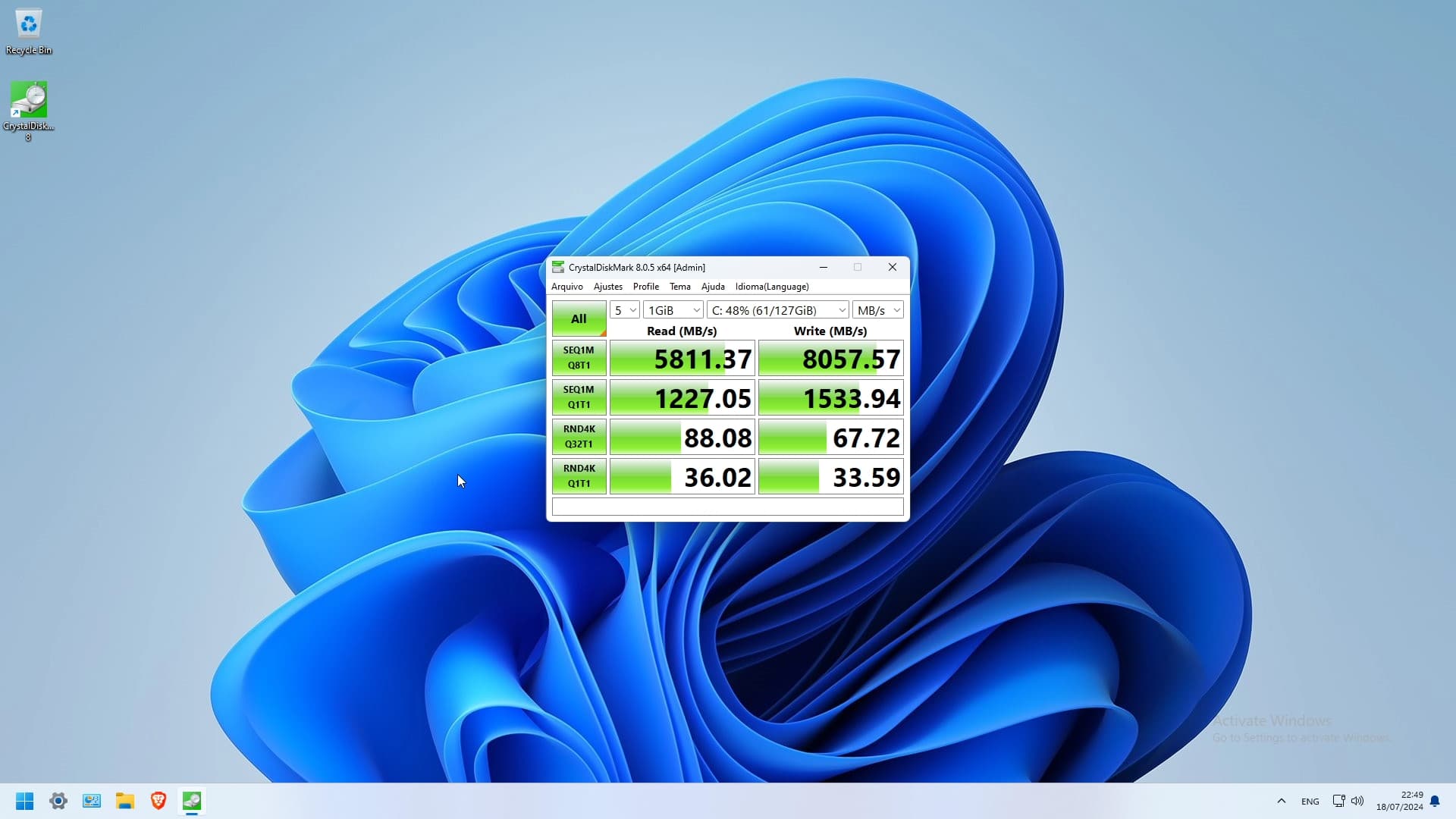
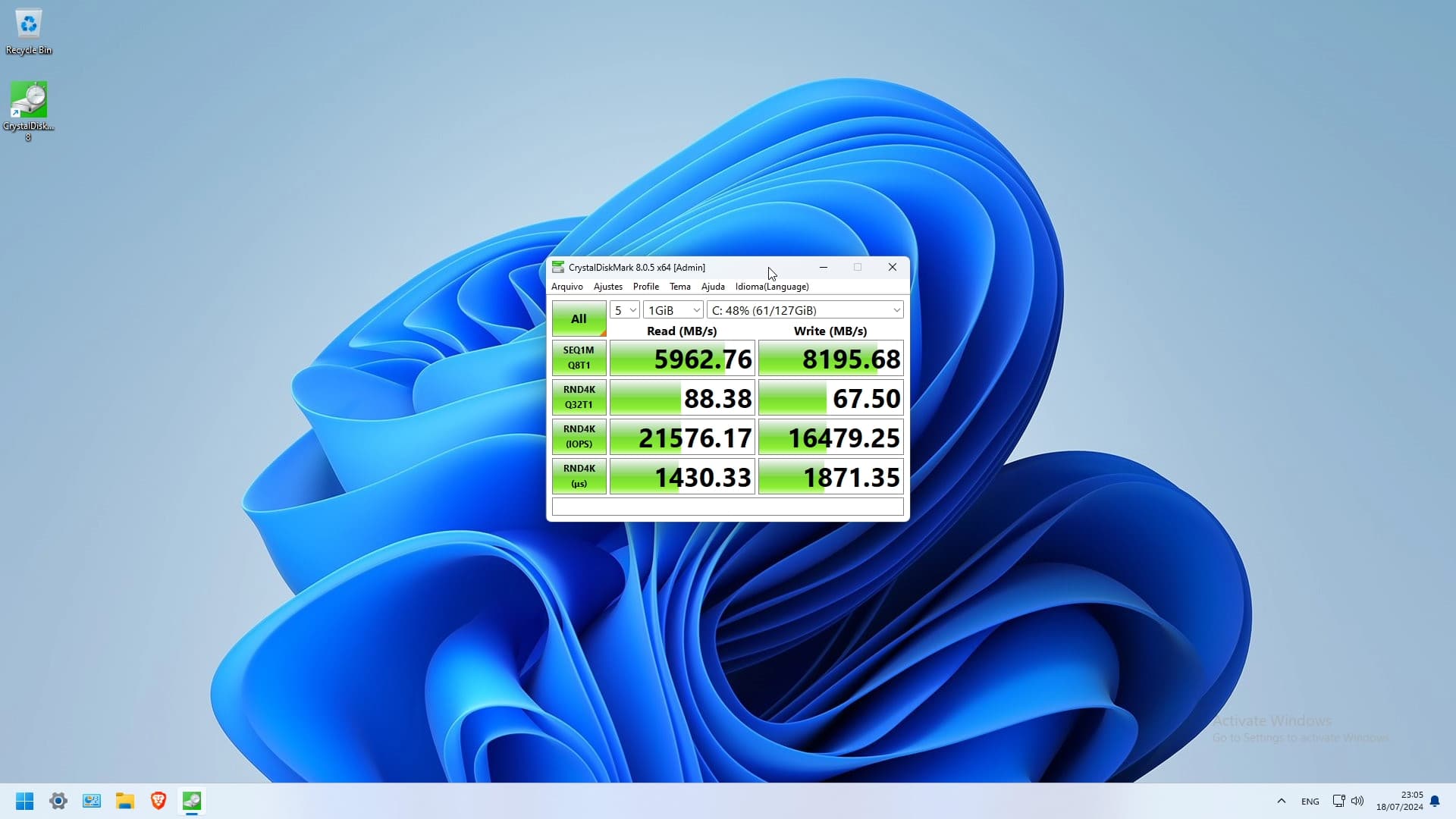
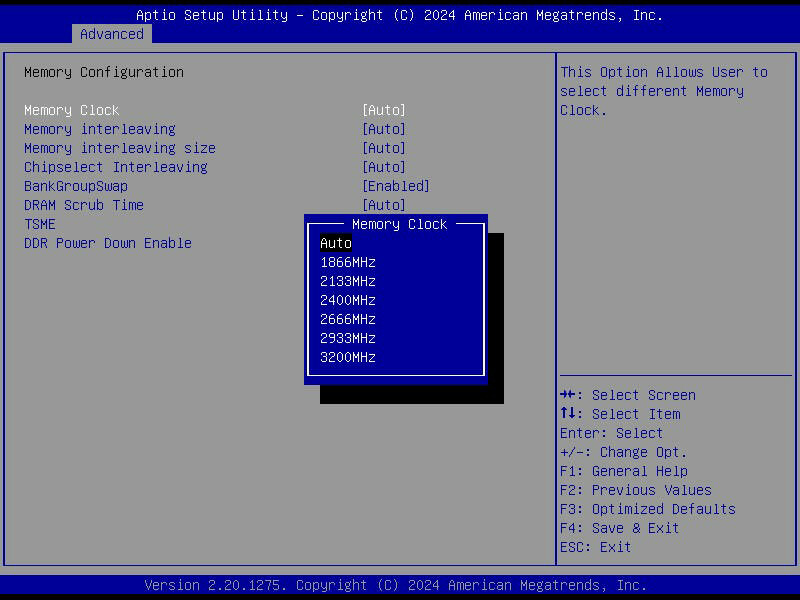
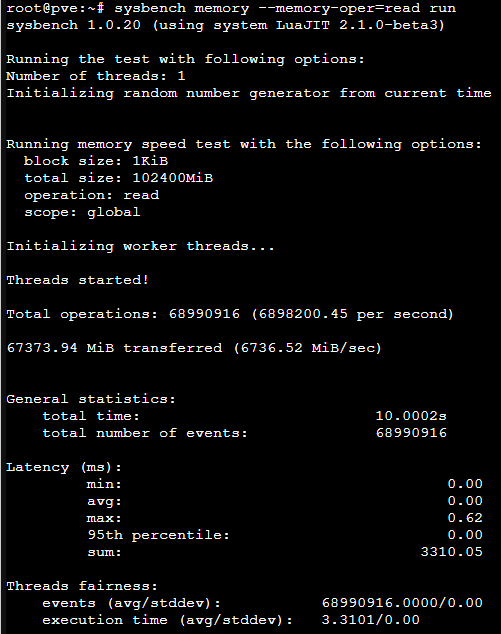
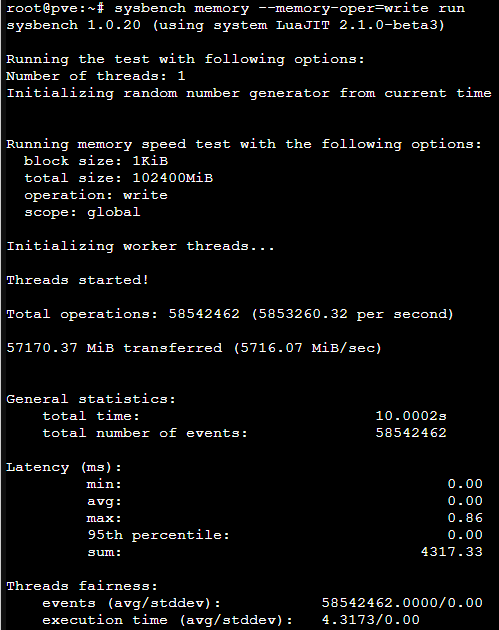
Seeing as we know almost nothing about the VM configuration I will just give some general pointers.
-
Any RAID 0 (RAID 10 is a RAID 1 of RAID 0) is going to destroy Q1T1 performance on NAND or Optane. Adding a RAID layer between the system and the drives significantly increases latency and overhead. Hence why, in the forum thread you linked about NVME RAID, Wendell came to the conclusion that “even if everything is working right, ZFS is “slow” compared to NVMe.”
-
Since you mentioned ZFS, it seems unlikely you are using PCIe passthrough to get your storage to your VM. QCOW2 and other VM disk image formats add a significant amount of latency and overhead to guest disk access. This is a compounding effect, on top of the slow ZFS RAID, further reducing performance.
-
The default disk cache mode for QCOW2 images is “none,” unless you have already changed this default in your hypervisor. This means guest disk IO is bypassing the host page cache; that is to say you are getting none of the benefits of caching to DRAM, in terms of latency or bandwidth. Since you seem to value redundancy, you may not want to use caching. But using “writeback” may increase performance.
-
I don’t know if Proxmox automatically sets up VM thread pinning, but this will also contribute to better guest IO performance. Your 32 core Epyc processor likely contains four CCDs; that is to say, four clusters of 8 CPUs. These clusters each have two “local” memory controllers, even though DRAM access filters through the IO die. In your BIOS, enable NPS=4 to expose these NUMA domains to your OS. You can read more about Epyc NUMA topology on ServeTheHome.
-
To my knowledge, Proxmox does not automatically set up hugepage backing for VMs. IO operations and PCIe passthrough-type peripheral communications benefit greatly from allocating the VM a contiguous memory area by using hugepages. These hugepages should be in the same NUMA domain as the cores you pin for best performance, because there is overhead associated with “hopping” across NUMA boundaries to access non-local memory. For example, if you allocate eight cores on CCD2 (essentially the whole CCD), make sure to create your hugepage backing on NUMA node 2 (or whatever it may be), and remind KVM to only allocate hugepages to this VM from NUMA node 2.
There is a lot of setup involved with extracting performance from KVM, which is generally what Proxmox uses. Above, I have identified half a dozen factors which may be contributing to your low IO performance.
Setting any of this up in Proxmox will require some Googling on your part. But since it seems to use KVM, I’ll explain some of the setup.
Here’s an example of properly set up thread pinning and hugepage backing in a VM. The KVM XML file definition is shown below.
The <memoryBacking> line tells KVM to use the <hugepages/> I have allocated. The <numatune> command tells KVM to allocate hugepages on a specific NUMA node <memory mode="strict" nodeset="1"/>.
The numbering in the cpuset commands seems nonsensical, but this is how virsh identifies CPUs in my two socket, four NUMA node system.
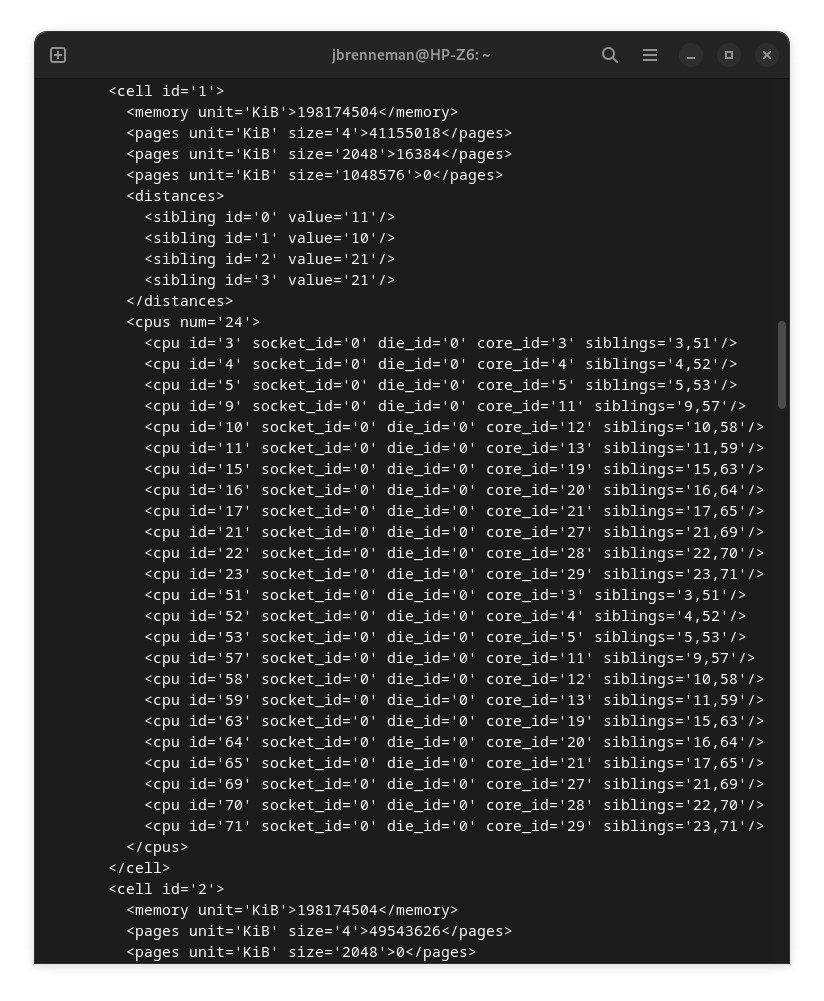
Running sudo virsh capabilities from a terminal will identify cores and their thread siblings, by NUMA node.
The above output shows the core IDs for NUMA node 1 on my system.
I allocate the hugepages to NUMA node 1 on each boot with the following command.
sudo echo 16384 > /sys/devices/system/node/node1/hugepages/hugepages-2048kB/nr_hugepages && sudo mkdir /dev/hugepages2M && sudo mount -t hugetlbfs -o pagesize=2M none /dev/hugepages2M && sudo systemctl restart libvirtd
This allocates 16384 two megabyte hugepages, to give 32GB of memory to my VM. You may also choose to use 1GB hugepages. The command then mounts them with hugetlbfs so they can be identified by KVM. Finally, the command restarts libvirtd so that the newly allocated pages are identified.
You must first set up hugepages in your Grub configuration file, for instance, before they can be allocated. Google how to do this with Proxmox.
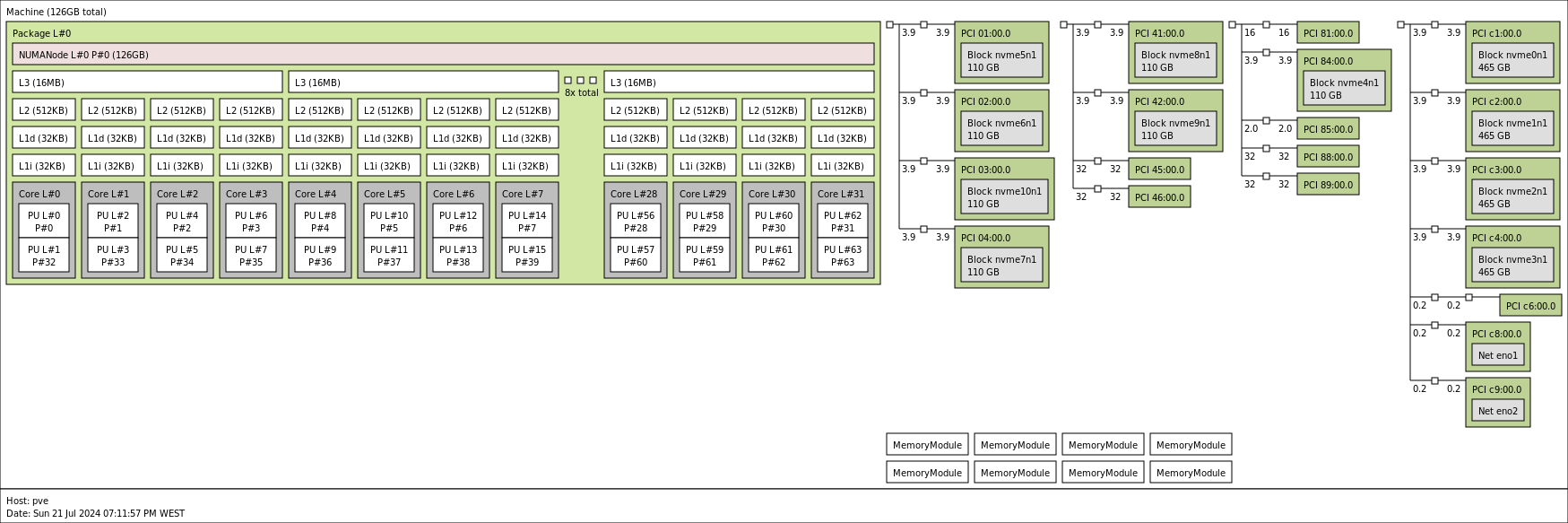
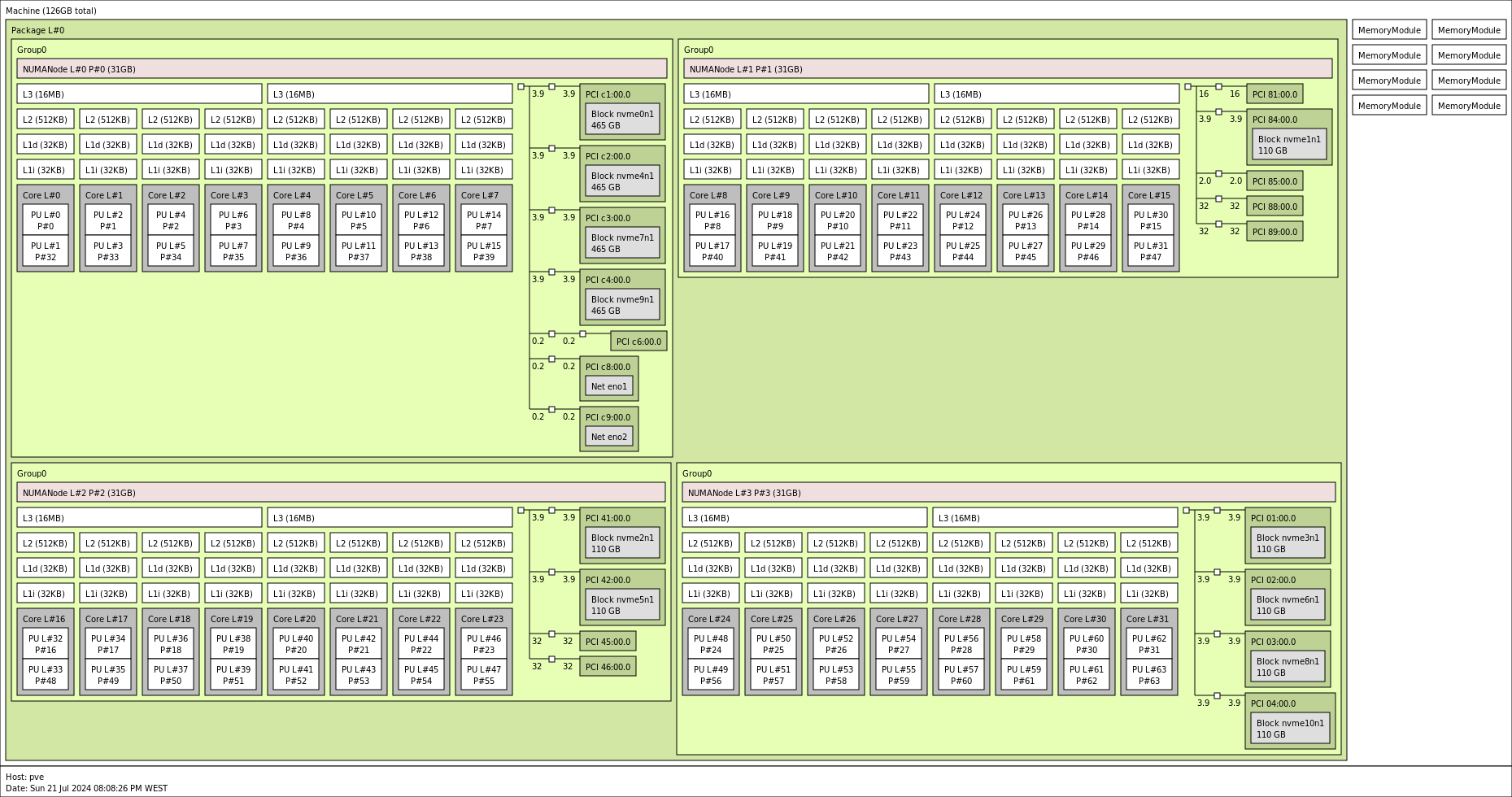
Which node you choose to allocate hugepages to depends on where you want to allocate cores, and which NUMA node other hardware for your VM is local to. You can install the lstopo or hwloc package on most Linux distributions to get more information about this. Run lstopo to get the output shown below.
In this example, the GPU passed to my VM is on NUMA node 1, which is why I allocate cores and hugepages there.
Hugepages and thread pinning will increase the IO performance of any KVM guest. However, you are still running into the fundamental slowness of ZFS and virtual disk media (QCOW2), so your Q1T1 gains may be minimal.