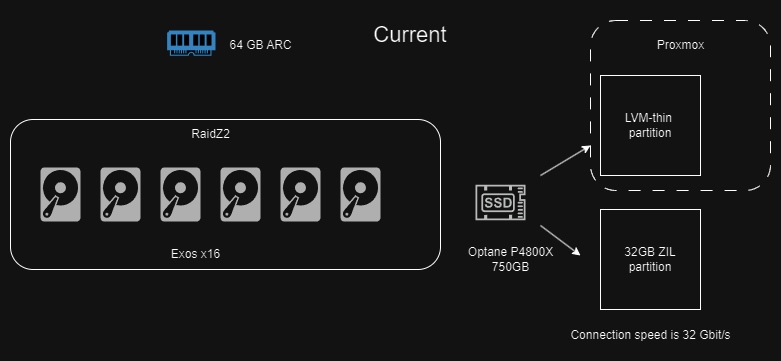
I run a virtualized truenas scale on proxmox. The boot disks for all my VM’s are on a pair of mirrored zfs nvme drives. For the truenas I has my pool layout as follow:
This is my backend storage. From steam games, to word docs, to movies, it has or will have it all.
The problems I was having with this layout is that:
While I am no where using up all my space in my z2 pool, if I ever want for space I would have to buy 6 drives in one go. As a homelaber, thats a tall order.
I run nextcloud and its db needs to be on somthing very fast. I got a crasy deal on an P4800X so I carved it into a SLOG and then a LVM-Thin pool for proxmox and different db’s I run. This has caused a weird disk layout that has a risk of data loss.
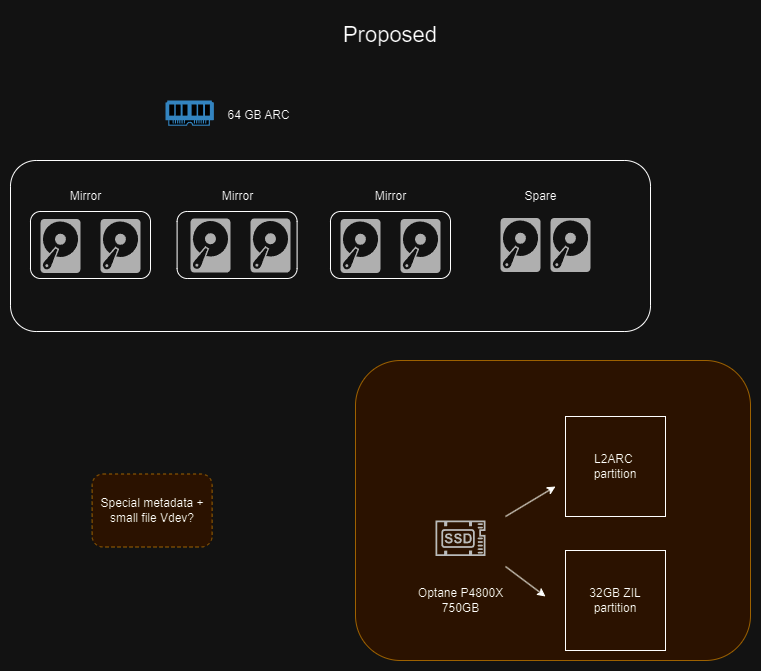
Shift my pool layout to mirrors with standby spares instead of raidz’s. This why I can scale up and down my storage via my needs. I also get more IO throughput. Change how I have my P4800X so be still a 32GB SLOG but the rest of the space be an L2ARC and move the db’s I had on the P4800X to the mirror nvme drives I have on proxmox. This would fix the possible problem of data loss while keeping the db’s somewhere fast and lots of IO.
The questions I have are:
Is this plan a good idea?
Would an SMD be useful for me? I dont think so and with it being another point of failure of a pool has me gun shy on it.
On the proxmox side of things, should I change my mirrored zfs vm pool to an LVM_Thin pool instead? I am worried about nvme wearout, especially if I start runing db’s there? I could be over reacting to this as in the past I did have some write amplification problems that I never really solved other than move as much as I could to the raidz2 pool. I am only at 8% on them but that was within the first few months before I moved things around. I could also just “suck it up” and get old enterprise u.2 and just chalk it up to “dont use consumer where enterprise should be used”
I have long been an advocate against RAIDZ, particularly for home lab, but not even there exclusively.
Mirrors are infinitely and easily scaled, and you get the performance benefit of having many more VDEVS which means IOPS will scale almost linearly with the amount of mirrors you have.
Just to underscore the argument. If you grow too big for your britches at some point, you can get two disk shelves. Slot 1 in Shelf 1 and Slot 1 in Shelf 2 can be mirrored. Then you can lose an entire disk shelf without ever really even feeling it.
So yes
SMD= Special metadata Vdev? It depends, but sure. As long as you use mirrors for that VDEV and not just a single disk, why not? Of course, how much you will benefit depends on your data. Wendell has a script here somewhere that will give you a filesize historgram. Depending on the makeup of your data, that script will tell you how much benefit you’d see.
Don’t give this too much thought. Keep an eye on SMART for sure, but I highly doubt that the workload you’d throw at it in a Homelab or SOHO environment would wear out those drives before the rest of the system’s useful lifetime has expired.
Sidebar: Why not just use SCALE as your hypervisor? The deployment you’re describing would make more sense with CORE, but for SCALE it’s the same KVM that Proxmox uses. Just seems like a but of unnecessary overhead IMO. Nothing “wrong” with it, just less efficient than it could be otherwise.
Yeah, Special metadata Vdev. As I am still building out my data (home movies, shows, etc). I’ll get a better understanding on what I need. I know that I will have to rewrite the data for the SMD to take effect. I just dont want to do it now as its more cost, and another point of pool failure. Maybe in the future.
I went with scale as I did want to use it for its built in docker stuff but I never could get it to work right so I stopped trying and just made a docker mv. I have considered switching from scale to core but I am more at home with debian and as you said, it not wrong, but “driving a ferrari to go buy some milk”.
No actually, I was suggesting the other way around. Don’t bother spending the time switching to CORE. Ditch proxmox and just use SCALE as your hypervisor
It is generally a good idea to keep the same level of redundancy for all vdevs in a pool.
You currently probably have a pool with sufficient space for whatever you may attempt. There is really no reason to get fancy unless you want to until something starts going slow.
make a new pool for the new drives
This is generally a good idea if you are switching to a different drive type, ie ssd sata, or ssd nvme, or u.2. So you know that your archive pool isn’t fast enough for a use case, so you put that data set in a faster pool.
add a new vdev to an existing pool.
Your first pool has N+2 redundancy, but you can also add a simple mirror to that pool while leaving the existing vdev alone. As soon as you add the new vdev, more space will become available. If writes are slow, adding a mirror will nearly double your write speed.
You probably want to allocate a large chunk of your existing ssd as a l2arc, and make it persistent. That way after a reboot your SSD cache is pre-populated.
short-term this might work…but as soon as the mirror vdev is at cap and RaidZ vdev isn’t, you have both an imbalance and revert back to old write speed. And you can’t remove the mirror either.
And is generally a bad idea in any other case.
I’m a mirror guy myself and having mirrors is a great thing to have. 50% storage efficiency? Deal with it! Afterwards there are only benefits waiting.
If 2-way HDD mirrors are painful, imagine 3-way mirror on NVMe being almost mandatory on other storage systems
Mine is an optane for proxmox boot and VM virtual memory, not zfs.
Then I have a single large zfs ssd, with VM images on it, and misc documents.
Then I have a single large mechanical hdd twice the size of the ssd.
I do hourly snapshots on the ssd, then once a day I replicate the ssd to the hdd, keeping the snapshots.
When the hdd eventually starts to fill up I can purge old snapshots.
My personal data I am managing is less than 3TB, so this is reasonable.
The OP was concerned that since he had made his initial array a 6 drive raidZ2, all of his future additions to the pool would also have to be in sets of 6 drive raidz2. I was just indicating that he could add a mirrors to the pool, or any set of drives with some redundancy. While it is possible to add individual drives, HDDs are fairly unreliable, and that is not advised.
For some of my thoughts on using mirrors or higher sets of redundancy on a production zfs server… (overkill for this user):
My thoughts on dedupe:
I think I need to make my own thread with my brain dumps.
Friends don’t let friends use dedup. I never recommend it.
Why are you using dedup? Mostly because of space saving…HDDs are dirt cheap, DRAM isnt. And even with very good dedup ratios (>5.0-10.0) it’s hardly worth it.
We get faster dedup soon…so the performance argument becomes stronger. I’m not convinced yet. But I’d like to see a dedup that is efficient.
Or sit and wait for RAIDZ Expansion…looks like it’s coming very soon.
That’s the essence of it. Just plug in two new drives and click that button. Or remove them as needed. Simple and flexible.