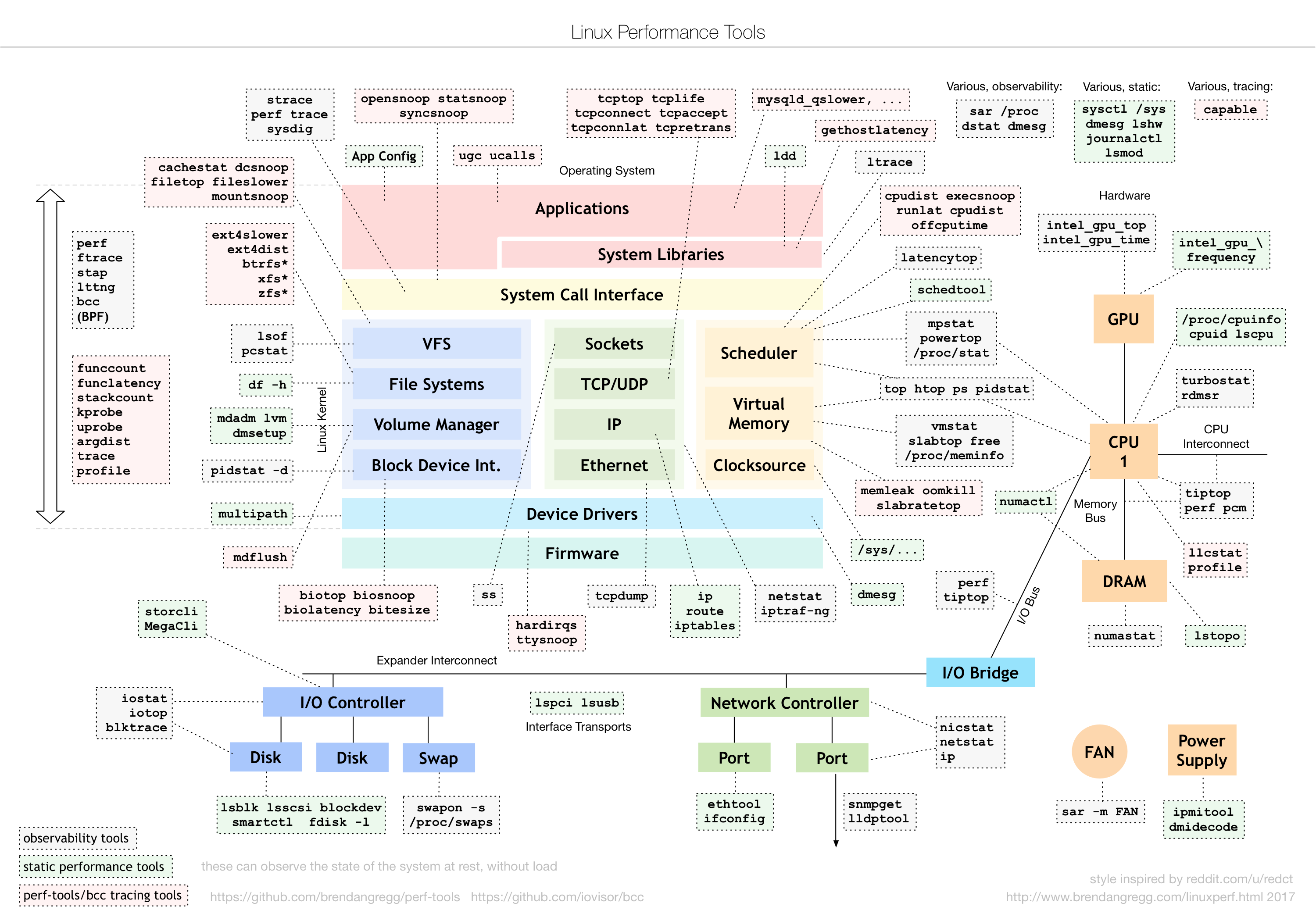
Hiya,
I’m trying to learn Linux by throwing myself off the deep end and I finally am starting to really struggle with how to resolve an issue. I am trying to build myself a Proxmox server with a zfs storage pool and I think I’ve narrowed down the i/o errors to the backplane or HBA I’m using but I have no idea how to proceed.
The server is built in a silverstone RM21-308 with a SAS 9207-8i Host Bus Adapter flashed in IT mode to connect the backplane.
The issue started when I tried to move my media collection onto it from another server, during the move it would get enough read and write errors to fault a disk and continue in a degraded state. I’ve since learned how to properly set the pool up like forcing ashift=12 and setting disks by id but the error isn’t resolved.
What i’m getting currently is this message every once in a while when I initialize my zpool and it upticks the i/o error counter in zpool status. I’ve also set initialize to write only 0s.
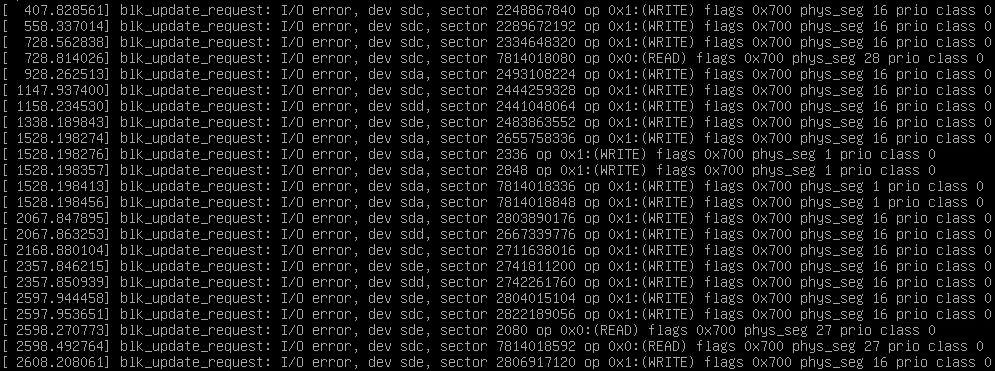
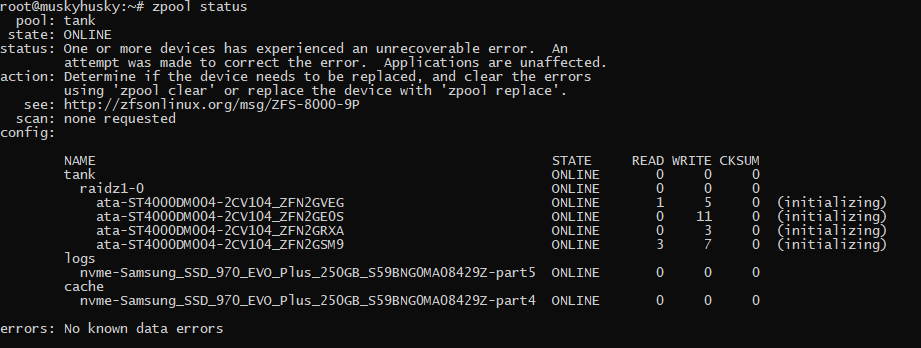
I’ve been thinking that I could train myself to become a computer systems engineer but this is really triggering my impostor syndrome while all three of my servers are in a vulnerable state or broken.