Seeking a review and advice from storage architects, gurus, nuts, etc. I’d like feedback on my approach, areas I could improve on, other options, or any potential pitfalls, gotchas or “landmines” to avoid. Also, available is the “This Won’t Work” reply, which won’t hurt my feelings - I’ll just go back to the drawing board.
I, also, present this case for those who are interested in working/learning about real life challenges that people in the field I work in face. Perhaps, this will add value to the community by exposing people to these challenges and possibly sparking interest in this career/area of the job.
I work for a software company. We have a new application we’re rolling out. It’s a cloud based application, which we host in house on our internal cloud. We are successfully moving through the process of application delivery at a good rate.
We’ve successfully built a POC cloud infrastructure. The application is going to be demoed soon. When this is done we’ll be in a position get more $$$ to continue building out.
A component of the continuous development and improvement is an extremely available and scalable storage infrastructure. I have an architecture in mind, but have a few areas where I need to get advice.
REQUIREMENTS:
In general, the storage infrastructure needs to be scalable, highly available and extremely resilient. Also, keeping in mind simplicity is a goal, too.
This means it must be easily horizontally scalable and replicated to multiples sites/regions. The data it will be hosting doesn’t need to be presented to instances in the runtime environment or “application collections” as directly attached storage/block level storage. In other words, the set of data this area of the application uses, needs to be persistent (obviously), but doesn’t need the I/O speed of directly attached storage.
Therefore, it’s probably best to present the data and storage as some kind File Level Storage (shared storage) or by http API. The replicated data, also, doesn’t necessarily need to be instantly available to all regions/sites, but should be quick.
PROPOSAL:
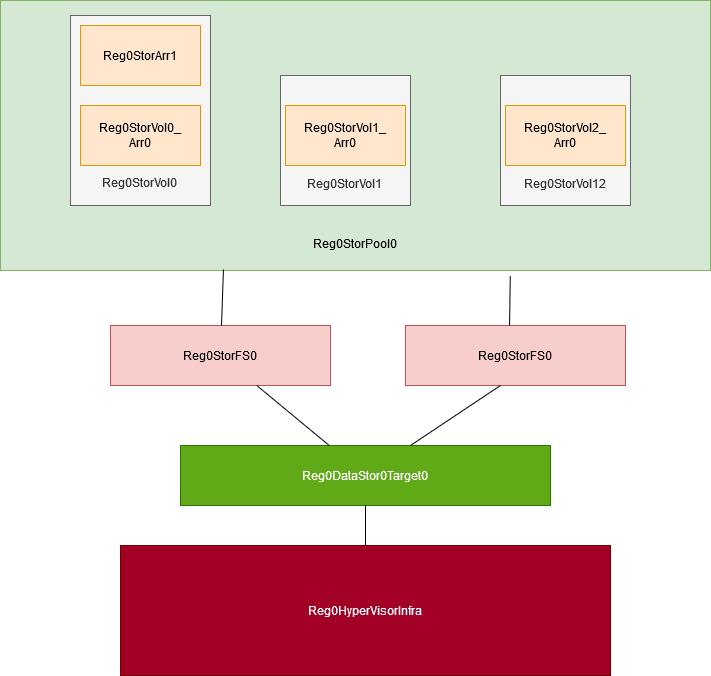
Therefore, it’s sufficient to say I need a highly scalable and resilient backend data storage target layer that can be pooled together into logical units. For the sake of simplicity, these pooled logical units should then be presented as volumes and directly attached storage to a centralized system, which then can present the file shares/http API to the application runtime environment (the application runtime layer.)
Starting from the “highest level” the best way to achieve regional replication, given the nature and requirements of the data storage demands, would be object storage. Therefore, in the blueprint above, the “Reg0DataStor0Target0” would be some system(s) running something like Ceph, Gluster, or Swift. This would also be the “Data Presentation Layer”. Other sites, would need to be setup similarly to handle the replication.
Moving up the ladder, there are two FiberChannel Switches that connect to a pool of storage array JBODs. From my understanding of Swift, JBODs can be used and are preferred rather than RAID. This is good because it allows for simple horizontal salability by cutting out having to configure RAID.
The JBOD arrays in the storage pools are targets for initiators on the “Data Presentation Layer” aka the Reg0DataStor0Target0. They are connected by FC.
As demand for storage on this infrastructure grows more JBOD arrays are added to the pool and presented to the Data Presentation Layer, which then logically adds the “volumes” and increases it’s amount of data available to the downstream application runtime environment.
In turn, storage configuration moves “up” the stack, away from the storage arrays, and into the Data Presentation Layer. This seems to be a benefit because it centralizes the management of the data to the Data Presentation Layer and out of the “Infrastructure” realm.
As more sites and regions are added to this infrastructure, the number of replicas increases, which increases resiliency, reliability, and should increase availability and increase network efficiency for clients who use the application based on where they are geographically located.
Areas of Unknown:
I think I’ll need to use some kind of Logical Volume Management on the Data Presentation Layer (ie Reg0DataStor0Target0). That way, as JBOD arrays are attached to this device, the volumes could be added to the pool and the pool be dynamically resized, without downtime. I’m not sure if CEPH, Gluster or Swift can do this or if I’ll need to use another tools like LVM to achieve this.
Thank you in advance to the community for any feedback.
Most respectfully,
cotton