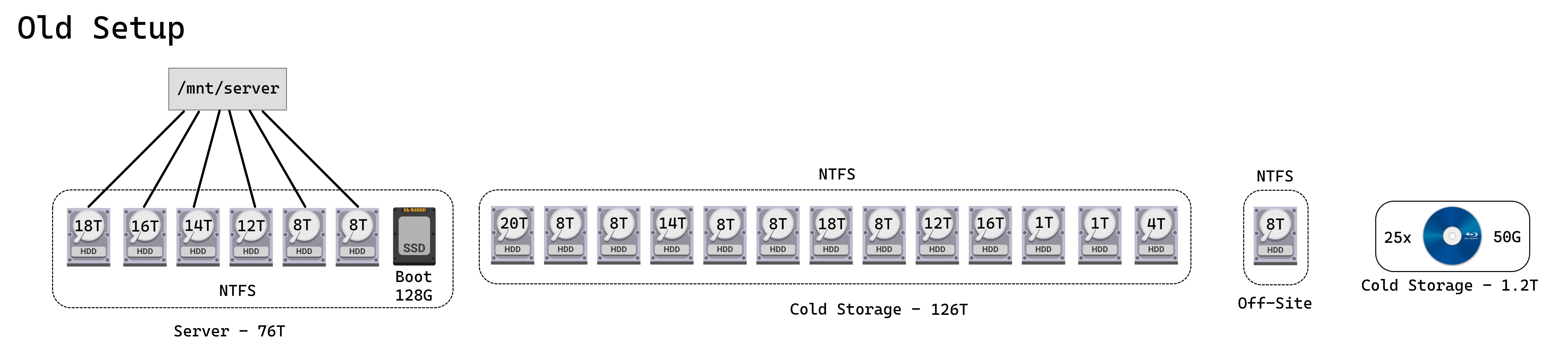
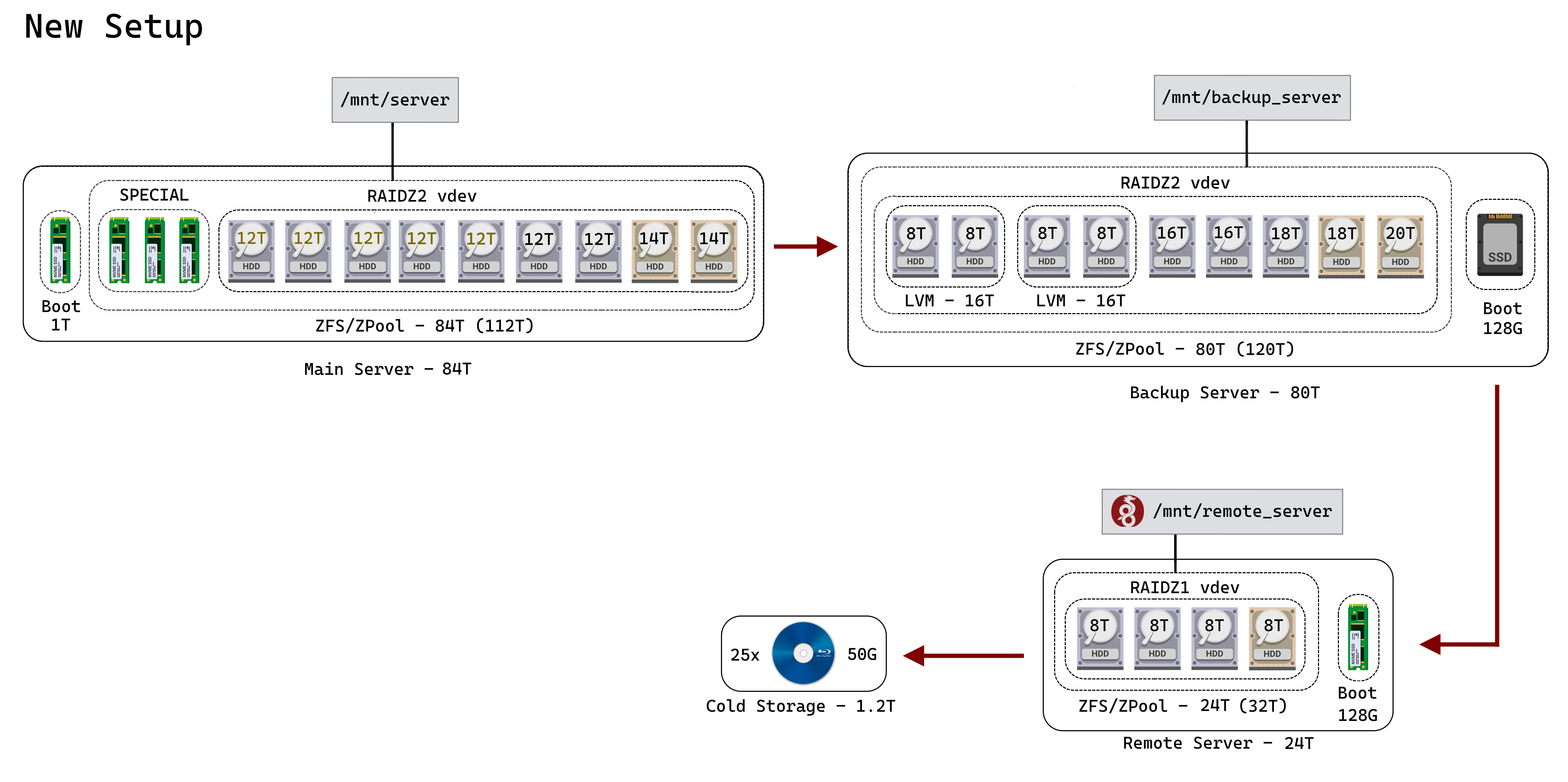
Just looking for some feedback before I make any purchases. I set up a local NAS for my family and me years ago, and didn’t put much thought into the setup or backup strategy. I’ve decided it’s reached the point where I just need to redo the whole thing.
* Gold text = A drive I’d need to purchase
* Gold drive = “lost” to redundancy (for illustration purposes)
The new server’s mostly the same size (given ZFS likes to have +10% space free), but I’ll be doing some spring cleaning too, so that won’t be an issue.
After spending some time researching the topic, I’ve come up with the following:
Main Server
The network device that everyone connects to
Uses ZFS (RAIDZ2)
+ Management can be done at the dataset level
+ Error detection / correction
+ Provides better redundancy
- Not easy to expand
- 4TB “lost” (can be partitioned for other things)
3-way mirror special
Matches pool redundancy
+ Faster metadata operations
- Another point of failure
⠀
Backup Server
A copy of the main server
Uses ZFS (RAIDZ2)
+ Faster backups with snapshots
- 8TB “lost” (can be partitioned for other things)
- Had to use LVM (possible performance loss and doubles the failure rate for those volumes. Acceptable for backups)
No longer cold storage
Allows for automated backups, as I’m clearly too lazy to do it manually :)
Provides live error detection / correction for backups
⠀
Remote Server
Off-site backup of anything that’d be next to impossible to recover
Comprised of all my SMR drives. Based on this, I’d rather keep them out of the main/backup server
Uses ZFS (RAIDZ1)
Overkill, but I hardly need 32TB here
+ Error detection / correction
+ Provides redundancy
+ Faster backups with snapshots
No longer cold storage
Same as above
Uses WireGuard to connect remotely
⠀
Cold Storage (Blu-ray)
Backup of family media currently on the cloud / discs / camcorder tapes / etc.
Thanks for having the patience to read all of this
Lots of thoughts went into this design and it shows.
The existing drives are not qualified in any more ways than simply capacity. While this is a perfectly fine way of looking at them in your current setup, it should be noted that for best practice only drives of the same model should be pooled together. The slowest/lowest quality drive determines the overall speed/quality of the pool. E.g. don’t pool 5400Umin and 7200Umin drives together, try to avoid drives from different generations (e.g. 128MB and 256MB cache drives), try to avoid pooling drives from different manufacturers.
The second thing to look out for (and you didn’t elaborate on it) is the type of drive CMR vs. SMR. SMR drives are not designed for pooled/RAID setup. Depending on your mix of CMR vs SMR drives your setup may change.
The third thing to look out for is the type of m.2 drives (SSD) to use as special devices. Please don’t select consumer grade nand drives, they may wear out quicker than your hdds.
Let’s look at your proposed setup:
Adding LVM pooled 8T drives to a 16T raidz vdev (in your backup server) is a big no-no. Let’s find a different way to effectively use these 8T drives. Do you realize that ZFS supports pools with multiple vdevs?
Your proposed setup moves from a “no redundancy” to “enterprise-class” redundancy (RAIDZ2) in a single vdev. There is nothing wrong with this.
A single drive redundancy allows for a single failed drive to be replaced before data is lost. Enterprises use two-drive redundancy partly because their servers are stored off location in hard-to-access data centers, where a higher level of redundancy is warranted. You clearly were ok without any redundancy up to this point, why the need for raidz2? Even in case of a complete pool failure you still have a backup and an offsite archive… just food for thought.
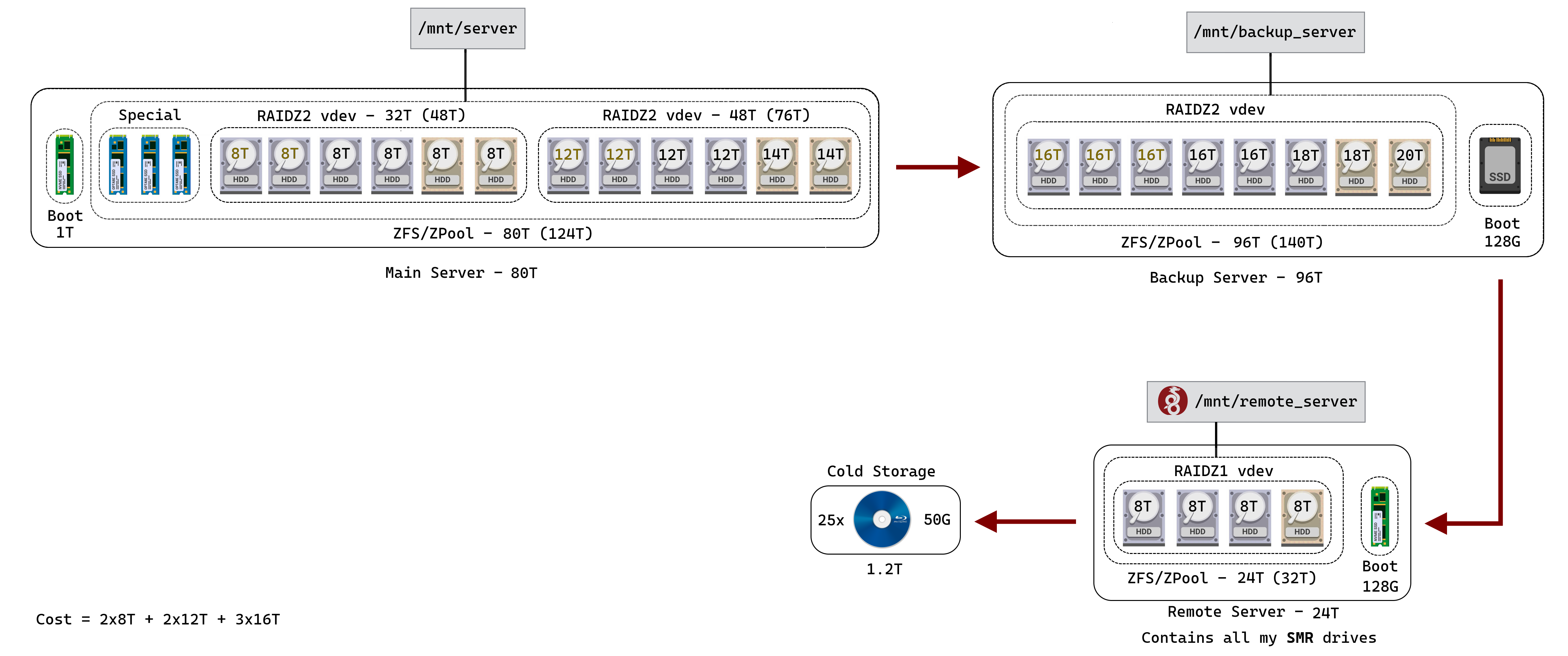
Given that you notice that pooling drives of different capacity is less than ideal you could consider creating pools with multiple raid1 vdevs in order to created vdevs of identical drives. E.g. you could design storage for the main server either as
Raidz1 4x 12T + raidz1 5x 14T (86T usable): don’t waste capacity you paid for, buy higher capacity drives, (hopefully) form vdevs of identical drives. Or as
Raidz1 4x 8T + raidz1 5x14T (88T usable: pull existing 8T drives from backup into main server, buy higher capacity drives, form vdevs of identical drives. (backup server: mirror 2x 12T + mirror 2x 16T + raidz 5x 18T (100T usable); pool existing drives, buy higher capacity hdds. Mix of mirror and raidz vdevs not ideal, but worth considering in a backup build. Note that this proposes a higher usable capacity for the backup. This would allow storing a history of changes on the backup in form of increasing snapshots - akin to a time machine.
These are just two alternatives that should be looked at in the context of the additional data about your existing hdds.
Thanks for the advice! Both the main and backup server use CMR drives with the following specs:
Capacity (TB)
RPM
Cache (MB)
20/18
7200
512
16
7200
256
14
5400
512
12
5400
256
8
5400
128
I don’t think mixing cache will be a significant issue for my use case given what I can find online, but I’ll keep the RPM in mind.
I mentioned in the remote section that the remote server hosts all my SMR drives. I really only need 8-16T, but that’s what I get for not doing my research…
I chose RAIDZ2 partly because a lot of folks online seem to dislike RAIDZ1 for larger drives, but I have no data to definitively say it’s unworkable, and folks still argue over it so idk. I erred on the side of caution I suppose.
Though my main reason for RAIDZ2 stems from the fact that I may be away for weeks at a time, so replacing a dead drive won’t happen quickly. I could try and coach someone on how to replace the dead drives remotely I suppose, but I’d feel more comfortable with the better redundancy. At least with a low amount of vdevs I feel it’s worth the cost. It gets a bit exorbitant after that.
That’s also why I minimized the vdevs to 1/pool in the first draft, since it costs me 2 drives a vdev. This makes it difficult to create a vdev for each size in an effort to reduce lost space. Keeping costs low ain’t happening with multiple copies of this amount of data anyway, but a man can dream.
What are your thoughts on these setups if I were to maintain RAIDZ2?:
Well that’s because resilver time is VERY long and it get even longer the more TB/drive there is. If you have all drives busy (parity RAID resilver is probably the most taxing workload for a HDD) 24/7 for days, you don’t want to take any chances of another drive failure resulting in losing the entire pool. That’s why people like Z2 and Z3. And you can’t repair corrupt data if there is no redundancy (which is the case during resilver of a Z1).
And do not use SMR drives for any RAIDZ-configuration. I’ve heard reports of resilver lasting weeks on small pools. RaidZ (parity RAID config in general) is slow with random reads and writes anyway. Having “dysfunctional” hardware on top of it is a big no-no.
Performance and Reliability always cost storage efficiency. Multiple vdevs also boost performance (each vdev is a stripe, so you end up with basically a RAID 50-like config.
Assymetrical vdevs aren’t that bad. If one vdev is slower, it gets less data proportional to its capacity. So you can mix and match 5400 and 7200 RPM drives via seperate vdevs in the same pool without problems.
Don’t create multiple pools. It’s inefficient and is double the work for administration. Gets even worse after realizing that you need double the L2ARC/LOG/special devices for two pools.
There is this cool feature called “spare”. Hot disk ready to take its place within the pool if anything happens. No need to be home as long as you have some extra drive already plugged it. If the stars allign, a potential resilver will just finish right before you return home.
And I highly recommend using some L2ARC/log/special devices to speed up the pool. RaidZ is slow and HDDs hate random read/writes.
I worked at ix systems for a few weeks before automating myself out of the position. They often were annoyed by people allocating a large slog, not realizing how it worked.
Your slog device should never be larger than the ram you have allocated to your san, if you are unsure, make your slog have a maximum size of the physical ram installed in the machine. Since most people’s device that they allocated for a slog is larger than the slog partition needs to be, allocate the rest of the device as your l2arc.
If it is too slow, give it more ram until that gets to be more expensive than the alternatives.
One of their customers with several petabytes managed by one high availability computer system had a 16GB slog.
Knowing what sync and async writes are and how ZFS can handle them is far from being common sense. Overprovisioning your SLOG down to like 16GB is best practice. More if you tweak your txg timeout and dirty data tunables. For home usage, I recommend sync=disabled and save yourself the trouble of getting into all this and saving a (possibly expensive) drive in the process.
ZFS’s extended vdev types (log,l2arc,special) provide ways to overcome technical shortcomings of main storage devices (assumed to be spinning rust).
These are low performance for small recordsizes and low performance in case of concurrency.
SSDs, and especially Optane, are well suited for any of these roles.
In my home servers I am exploiting the capability of servicing increasingly large queue depths without performance penalty compared to HDDs.
I simply partition my Optane device and assign a few gigs as Log device, some more as L2ARC, and most as special device (always in a mirrored config) taking advantage of all of ZFS capabilities without the need for additional drives.
I like the thought of sync=disabled for its simplicity. I don’t observe a lot of sync calls and may switch to this in the future.
Exactly, And the only time there may be a read event is following an unexpected power loss.
When a read event occurs, it looks in ram, then it looks in the l2arc, then it looks on disk. If reads are slow, get more ram. At any given year, dram continues to be 100 times faster than an SSD, and about 10,000 times faster than a spinning disk.
Your array can be engineered so that spinning disk is not the bottleneck, network is, which reduces the need for a large l2arc. If it was accessed recently, it is coming out of ram not l2arc.
If your truenas VM is performing badly, give it 24GB of ram instead of 8GB of ram. In 2016, on FreeBSD, zfs would use up to half of installed ram, on linux it would use up to 8GB, though both could be overridden. If you have a physical machine, or a VM providing a NAS service, balance it so that it claims sufficient resources.
I’ll also look into maybe having a hot spare in the main server like @Exard3k mentioned. Jason Rose from jro.io recommended it with 10+ drives, and given the lag time between failure and replacement, it could be a decent idea. Luckily they can be added after a pool is created, so it’s not something I necessarily need to consider now (same goes for a L2ARC/SLOG).
SMR
The remote server contains all my SMR drives, as once it’s set up, it’ll be sparingly written to. I went with RAIDZ1 since this article suggests it’s on par with mirroring at 4 discs, but there might be other things I’m not considering. Should I go with a mirrored setup instead? The capacity’s not too important since it’s more than I need, but the SMR drives had to go somewhere :(. The focus is really for error detection/correction rather than redundancy, since resilvering will be crazy regardless of this decision.
Optane
For the special vdev, would the Optane P1600X 58GB work well enough for just metadata, or should I bump it up to the 118GB? It’s hard to find rough estimates for how big the special vdev should be, but I’ve seen mention of ~1GB / 10T (recordsize=1MB).
I see that your main server can now hold 12 drives as opposed to 11 in the last iteration.
This is where we should discuss case/chassis and expansion capabilities (if any). I assume you have a case/chassis and a motherboard/CPU in mind for this build?
If not, the first question is about rackmount or not. Housing 12+ 3.5" drives in a computer case is pushing it. It’s common to find rackmount chassis for 12 3.5" drives in as small as a 2U form factor; you can get chassis with 15, 24 and 36 drive bays in 4U format at higher but reasonable cost; everything beyond that is highly enterprise and very expensive.
The number of drives fitting into the case/chassis determines if you can add spare(s).
In my experience SMR drives fail in RAID or RAIDZ configurations. They simply cannot handle the stress. Put them into the mirrored config and they will be ok.
Well, you’re starting from a humble setup. The extra vdevs in ZFS are designed to overcome the shortcomings of HDDs. Configuring log, l2arc, special vdevs will support work loads that HDDs don’t handle well.
Most consumers look at HDD specs and see 200+MB/s speeds and expect to experience those in day-to-day operations. In truth these are only reached in a highly specific workload of low concurrency (queue depth) and large recordsize (>128kb).
If you invest in SSDs especially as special devices ZFS allows you to configure your datasets in such a way that HDDs are most likely to operate in their sweet spot.
This means you configure the Optanes to store all data blocks with less than and up to 64k and let the rest spill over to the HDDs. This works spectacularly well for media files (videos, pictures, music) which is what most home labbers want to store oodles of.
Software archives, other datasets may have different characteristics. Consider an email archive where there are 10k-100k email files, typical size of a few kB. This would flow with few exceptions onto the special devices.
How much space you need for your special device configuration absolutely depends on your use of the pool.
Considering your outlay for new drives I don’t see a reason not to go for 118GB Optanes. If one thing is certain, then it’s that your data needs will grow over time. I’d consider 2x 960GB Optane 905s (they come with m.2 to u.2 adapters) instead of 3x Optane 1600X. Although more expensive, these will likely outlast every bit of the main server you’re considering today.
Such a setup will improve the performance from your current speed capped by the capabilities of a single drive to a setup that will saturate 10gb networks.
The drawback is the obvious higher cost for the server, and the additional followup cost because you’ll want to upgrade your network to 10gb Many here have gone through that process …
Maybe this is an overly ambitious pipe dream for today. In this case I’d consider 2x 118GB Optanes for today configured for metadata caching only as special device, depending on your workload you should consider turning off sync or reserving small partitions on the Optanes as mirrored log devices. The smaller Optanes will likely suffice, too. But I don’t know since this is dependent on your content.
Metadata content grows with the number of files, not their size. Wendell’s recommendation of 0.3% of total pool storage (or your 1GB/1TB heuristic) is practical because most people know their storage capacity, but misleading.
You don’t need Optane. I went with old 250GB SATA SSDs until I upgraded to standard m.2 NVMe drives. Everything faster than HDD will do fine. Most metadata is kept in ARC/L2ARC anyway. The interesting part about special vdev is that you can allocate all small files to it. That’s why I have 2x1TB as a mirror in my pool. Millions of small files add up and if you can save your HDDs from reading and writing those little buggers, they’ll be happy.
1G per 10T is about right. Scales linearly with the recordsize. Calculate with 32-128k which is the most common size unless you know you’re running 4-16k zvols and datasets worth TBs of data. You can’t get smaller NVMe than 500GB nowadays and they will be plenty. P1600x is just too small of a capacity outside of using it as a SLOG. My special sits at 230GB allocated in a pool filled with 20TB and small blocks set to 64k. I got everything from video over game files to 16k blocksize zvols, truely mixed kind of data across the board.
Is most of your data “archival” or “read once in a while” such that you wouldn’t necessarily care about individual file throughput much?
You may want to look into snapraid and mergerfs if your data fits that shape.
ZFS is a really good filesystem, but it’s hugely complex and not very flexible nor very cost efficient if all you need is e.g. a 100TB mostly write-once/read-many movie archive.
Tailoring this to your use case does take some scripting, … (moving data in/out of tiered storage) but it’s easier to grow overall volume than it is to grow ZFS pools.
Also, if you want “high availability” and ceph is too complex for you, there’s various other options.
@jode Good advice! The plan is to use my existing server (10 drives max) as the backup server, and repurpose my mini-PC and 5-bay DAS as the remote server. I’ve been looking into a rackmount build with the following equipment, but am of course open to suggestions (prices are from Amazon, but may be cheaper elsewhere):
Chassis ($230)
Rosewill 4U RSV-L4500U
supports 15 3.5" drives
Motherboard ($120)
MSI Pro B550M-VC WIFI
Supports 128 GB of DDR4 Memory (for future proofing)
4 PCIe x16 Slots (1 CPU, 3 Chipset)
Slot 1 (CPU) = 4 NVMe to PCIe card (depends on how it can be bifurcated. Probably won’t get all 4)
Slot 2 = HBA (supports 8 HDDs without an expander)
Slot 3 = 10Gb NIC (Not needed for now, just good to know I have room for one if anything changes)
8x SATA 6Gb/s (supports the remainder of my HDDs)
2x M.2 slots (1 CPU (OS drive), 1 Chipset)
CPU ($100)
AMD Ryzen 5 4600G
Cheapest compatible CPU with an iGPU. The only downside is no PCIe 4.0, but I’ve survived on PCIe 2.0 up until now . The 5600G is only $30 more, but this is already overkill compared to my old setup
Every other component is simple enough. My old setup used a J3455B-ITX motherboard/CPU combo, and while slow and a little broken in some places, it has served me well so far, and will continue to be of service in the backup server.
@Exard3k In that case I’ll consider getting some Firecuda 530s. They’re PCIe 4.0, with twice the typical TBW ratings (though I’ve heard not to take those as gospel), and reviews seem decent.
@risk I’ve had a look at mergerFS/snapRAID before (given my mixed drive sizes), but I like the extra features and more hands-off approach offered by ZFS. I also don’t expect to be expanding my storage for quite some time, so it’s not a massive issue for me. Besides, the complexity is part of the fun!
Alrighty folks, I had to change the motherboard, but I’ve been reading the manuals very carefully now, so I think I’ve got it this time. This is only the 2nd computer I’ve built, so I didn’t realize PCIe slot size ≠ PCIe lane size. The Pro B550M-VC WIFI is physically x16x16x16x16, but only has x16x1x1x1 lanes which is no good.
Slot 2 = 10Gb NIC (Not needed for now, just good to know I have room for one if anything changes)
Another configuration option is to use the Synology E10M20-T1 10Gbe & NVMe combo in the CPU x16 slot. It’s switched, so no need to mess with bifurcation.
Alot to take in, i am working on a setup similar but in a dell poweredge XC730xd-14 bay, 2- SFF in rear, and 12-LFF mix of drives. With this info i am now going to change my mix of small and lrge hd’s to this for my home server.
1- 14tb exos with 5- 8tb contellation dell drives in a raidz1 pool, then mirror the same into another raidz1 pool for redundancy. The boot drive is a 128gb innodisk SATA-DOM. I have 2 pcie 8X adapters for biforcation. But the optanes that I have on hand are only 32gb eac. Should buy others or use these, till they can be updated for the special mirror R1.
Also 2 rear SFF drives are nvme ssd adapter caddies for 2- 1tb gen 3 NVME for the metadata.
Asa a newb in this realm of server builds am I following close enough to what has been said so far. 54tb is more than ill ever need for storage, and streaming. My backup is a r440-10bay SFF, with 8- 2tb NVME 2.5” drives in a zfs raidz1. A 64gb SATA-DOM boot, another pair of 1tb NVME gen3 on the same type of pcle 8X adapter for metadata, no special. Yet!