I am writing due to a recent problem that I encountered mostly by accident. Specifically I decided to run HD Sentinel, in order to see whether there was any change in my HDD’s condition. To my surprise I realized that one of my HDD’s (WD10EZEX), also the most recent one (~550 days powered on), had 90 bad sectors that as far as HD Sentinels status message, “The contents of these sectors were moved to the spare area”.
First off, would you trust this disk any more for data storage? Or shall I abandon it?
Secondly, the last few days I upgraded my OS (fresh installation) from ubuntu 16.04 to 18.04 (on my SSD), with full disk encryption on it enabled. Although, as I 've already stated, there is no OS installation involvement on the HDD that the bad sectors exist, I am worried whether the OS might damage the disk, because the last few days since the OS fresh installation, I am witnessing OS hiccups and total freeze for about 10secs, almost every day.
Have you any similar experiences or anything that you can suggest, in order not any further damage occur to any of my spare disks? Should I be worried from these OS freezes? Moreover, is there anything that I can try to diagnose/troubleshoot them or even to record them with to system logs?
Thank you in advance and sorry for the long post.
P.S. Last time I run HD Sentinel (about 2-3months ago), there were no problems detected, with 100% health on all my disks. Now, the above mentioned HDD has 28% health and my SSD 99%.
When a sector goes bad the controller will mark it as such and realocate the data stored there.
When a drive reports that there are bad sectors outside of this process that means that the drive should be tossed because the controller has no more padding to reallocate data.
Before doing so, give it a check with the badblocks utility. This is available on any linux live distro. Simply boot into in and select your drive and run the following command in a terminal:
sudo badblocks -nsv /dev/sdX
Where the X is the drive.
So if you do a command to list all the HDD’s in your system it should look something like this:
luke@Jupiter:~$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 2.7T 0 disk
└─sda1 8:1 0 2.7T 0 part /mnt/Games
sdb 8:16 0 2.7T 0 disk
└─sdb1 8:17 0 2.7T 0 part
sdc 8:32 0 238.5G 0 disk
├─sdc1 8:33 0 300M 0 part
├─sdc2 8:34 0 100M 0 part /boot/efi
├─sdc3 8:35 0 128M 0 part
├─sdc4 8:36 0 237.5G 0 part
└─sdc5 8:37 0 470M 0 part
sdd 8:48 0 238.5G 0 disk
├─sdd1 8:49 0 512M 0 part
└─sdd2 8:50 0 238G 0 part /
The /dev/sdXY X = drive Y = partition
So for example I want to check my Games drive, I would do
sudo badblocks -nsv /dev/sda
Not it will check every sector and will take several hours to run. So be prepared.
Have you checked with things other than HD Sentinel?
Here and here and maybe even here are some things to try to confirm HD Sentinel’s results and maybe give you more insights on the exact condition of the WD10EZEX you’ve got.
Yea if you’ve got OS freezes, I’d be a tad bit worried.
Was the SSD which has the OS install having trouble before the upgrade? Is there anything tied to the HDD that would contribute to the hiccups?
You could look into this if you have to save stuff from the bad sectors.
If my links seem untrustworthy maybe just stick with the official Ubuntu docs here
dont be too alarmed finding a couple bad sectors. its not uncommon to find bad sectors even on a new disk
earlier hdd’s had issues with finding a lot them on new drives due to inconsistencies in the oxide density! (too low content of iron) and the sector would fail magnetically,
to counteract this many drives were equipped with firmware to mark bad sectors and move data (smartdrive) or the hdd came shipped with software to manage it for you.
quality controls are very rigid with drive manufacturers and tests are done under various conditions but they cannot cover all possible conditions.
if the sentinel or smart feature of your hdd is displaying failure soon is wise to back up your files immediately and replace the drive.
a good practice is server redundancy if the drives are failing you can seamlessly switch to the backup server while the other is down for repairs
Thanks guys for your information and troubleshooting.
I am going to post bellow more specific info about my issue:
badblocks -sv /dev/sda
Checking blocks 0 to 976761526
Checking for bad blocks (read-only test): done
Pass completed, 0 bad blocks found. (0/0/0 errors)
Those OS hiccups were never a thing back when I was using Ubuntu 16.04 nor with Windows 7. Now almost every day within Ubuntu 18.04 there come up.
Furthermore, maybe I should note that I was mainly using that disk for storage and as a vm pool for Virtualbox.
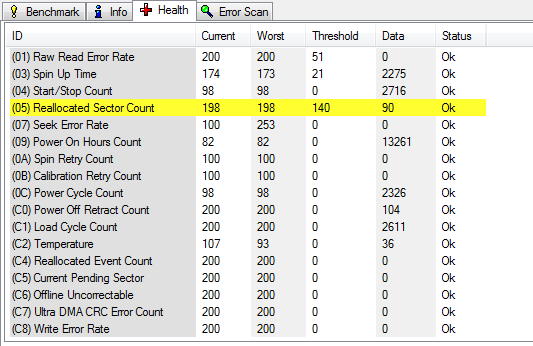
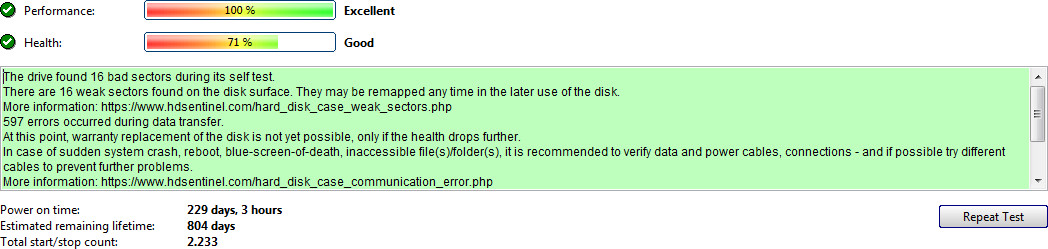
Edit: Some info from HD Sentinel
Estimated Remaining Lifetime : 99 days
Health :
28 % (Acceptable)
Performance :
100 % (Excellent)
There are 90 bad sectors on the disk surface. The contents of these sectors were moved to the spare area.
At this point, warranty replacement of the disk is not yet possible, only if the health drops further.
It is recommended to examine the log of the disk regularly. All new problems found will be logged there.
It is recommended to backup often to prevent data loss.
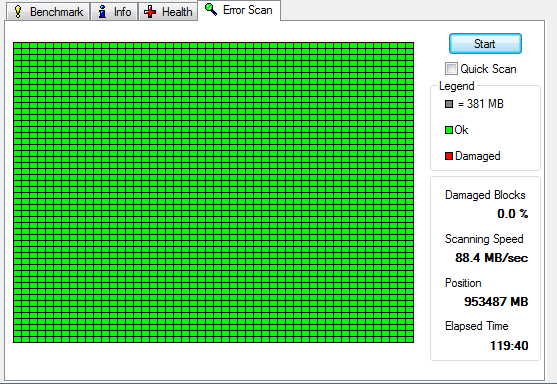
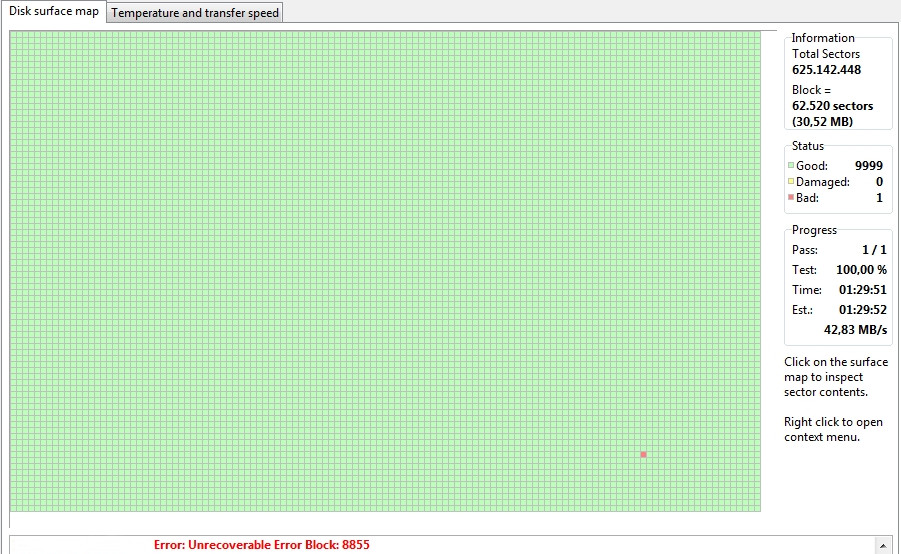
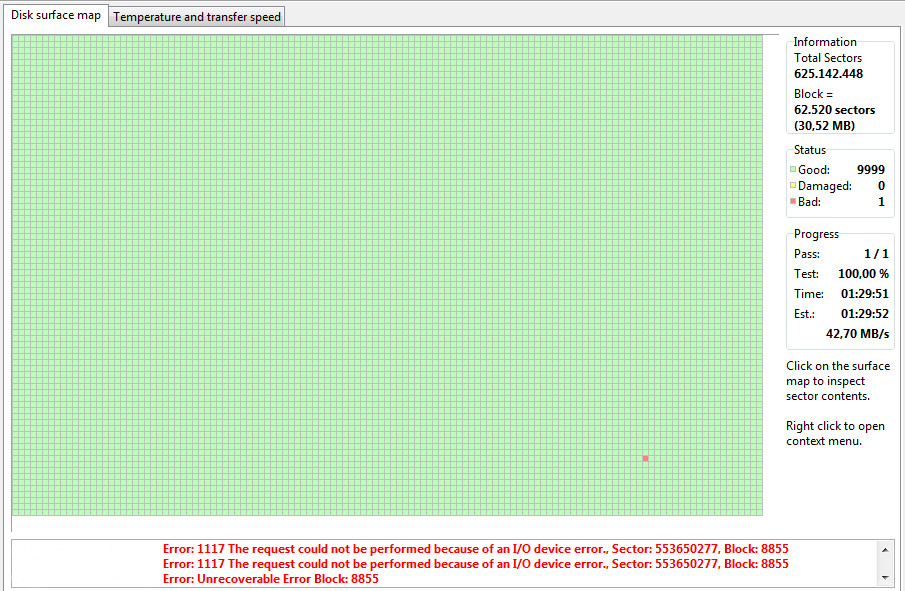
To make matters even worse, I also started to check for bad sectors in my laptop’s disk, just to realize that it also illustrated some maybe even more serious problems. At that point, I would like to mention that before checking the condition of the following disk’s, I did run the following command, in order to zero fill the whole disk:
dd if=/dev/zero of=/dev/sda bs=4096
In the beginning (after the above command), the disk’s state was as it is shown in the following pics.
To sum up, by the continuous use/testing of the disk’s surface, and after some whole disk 0 fill commands, I realize the continuous decline of hdd’s condition.
What are your thoughts and suggestions for that matter also?
Thank you in advance for your time and also I would like to apologize for the long post, but as you can see I am very frustrated about the hdd’s reliability these days.
the thing witth bad sectors is there is actual physical damage to the oxide coating on the disk often enough that it affects the retentive ability to maintain its magnetic field.
head crashes cause the damage usually by jarring and the head briefly slams against the platter.
programs like chkdsk, testdisk and others locate the damaged areas and mark its location in the drives index file, then when writing to the disk the drive skips the damaged area and doesn’t write to it.
when enough flagged sectors accrue then the drives capabilities start to be compromised
smart drive programs give you plenty of warning when a drive might fail and you should have sufficient time to back your data up
as far as writing over bad sectors what good can it do for damaged surface of the disk?
Ive had to pack hdd’s in ice packs to recover data and then its an iffy chance.
once the data is backed up re partition and format the drive to erase any data then scrap it!
(If you are worried about possible recovery use a bulk tape eraser then take a sledgehammer to the drive)
{kind=link}
{kind=link}
{kind=link}
{kind=link}