tldr: “zpool upgrade” failed and now I can’t get to the data in my main ZFS pool.
Despite my better judgement, I ran "zpool upgrade. “zpool status” kept giving me the same status that I needed to run “zpool upgrade” on my main ZFS pool. I did so, and immediately started getting some pretty major errors.
I’ve been fighting this for a few hours now, and I’m still terrified I lost all of my data.
So far:
I can boot just fine into Proxmox if the 5 drives of the ZFS pool aren’t physically inserted.
Inserting the drives causes no errors. “zpool import ZFSPool1” fails, hangs, and causes issues in Proxmox. It starts throwing “task zpool:126913 blocked for more than XXX seconds” errors every 2 minutes. ps aux doesn’t find a task ID 126913.
“zpool import -N ZFSPool1” works perfectly, but doesn’t mount any datasets (what the -N option does) - but it DOES show the datasets.
“zpool import -nF ZFSPool1” to repair the pool ALSO starts throwing those same “task zpool:126913 blocked for more than XXX seconds” or “task txg_sync” errors.
I’m terrified I’ve lost my data again. It’s all replaceable (everything irreplaceable is safely backed up) but would take a LOT of time to regather everything.
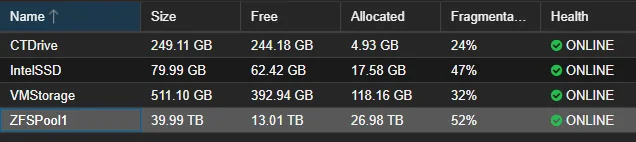
The main glimmer of hope I have is that, upon import with the “-N” option shows the pool, the data, and the data usage. I just can’t touch it from Proxmox.
Proxmox “sees” my big ZFS Pool (ZFSPool1)
Errors coming up on the server’s console



