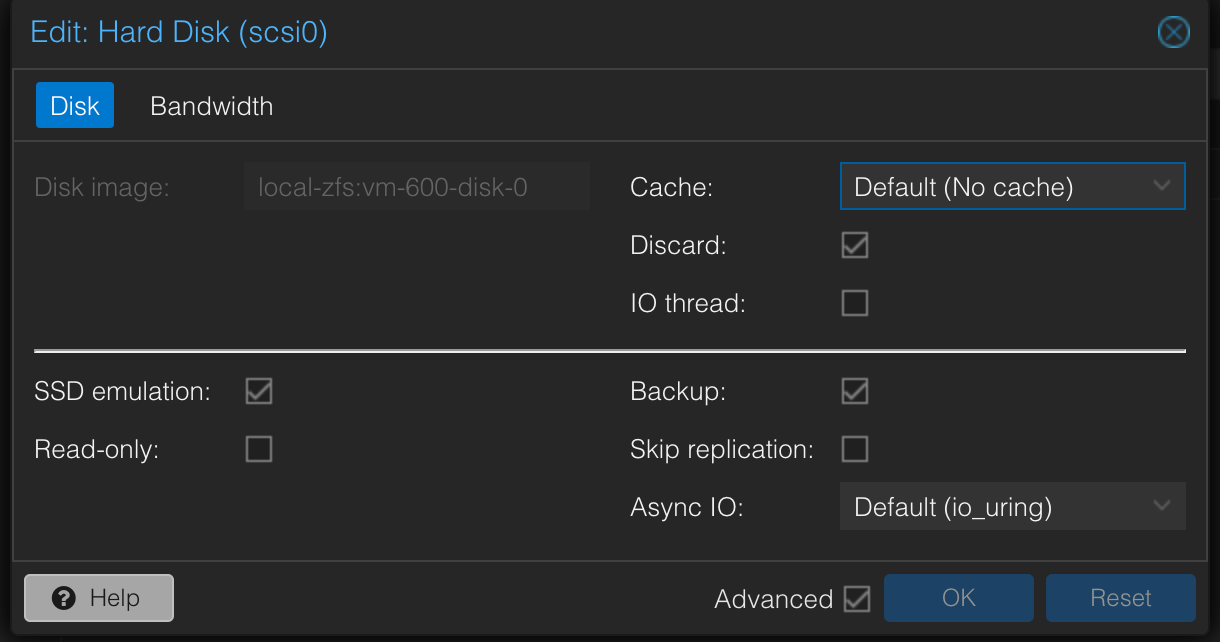
A few months ago I migrated from a single proxmox instal to a mirrored array using a supermicro pcie dual slot nvme card 9my motherboard doesn’t have native physical nvme support), and ever since, I have noticed very slow VM perofmrnace. This is a homelab, so it isn’t “really” an issue, but even just apt upgrade on simple ubuntu server VM’s takes a while, and if I kick a bunch off at once, things really slow down. This was not an issue at all when I was using a single nvme drive and not using ZFS.
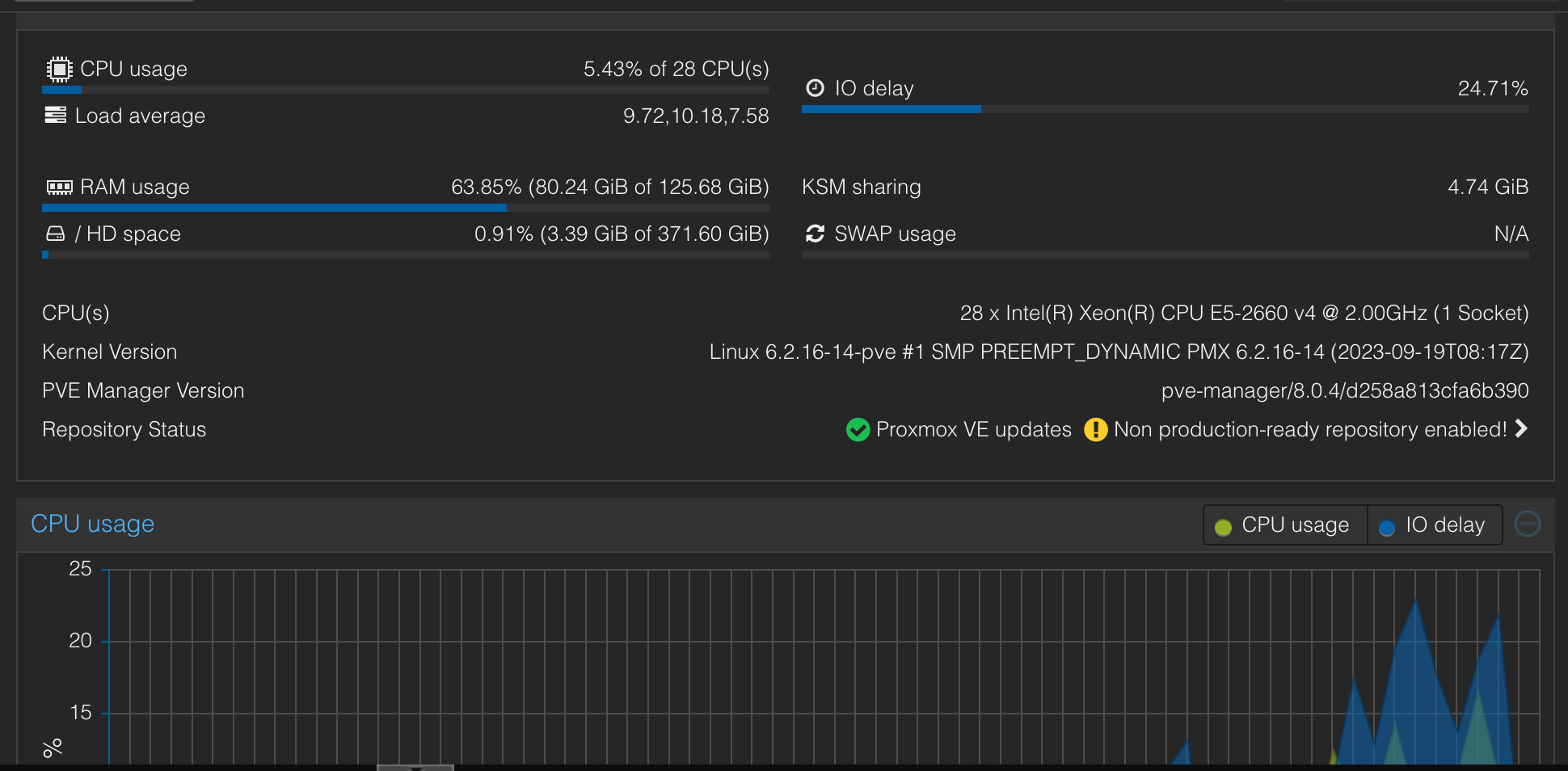
I do notice really high io delay, and being almost entirely a noob, I assume this is related? I store my VM’s on the same array as the boot drives, and have reduced ZFS’s RAM usage manually since it was eating up all my systems RAM for no real reason (again, this is a homelab, I really don’t need ARC acceleration on a pair of NVMe drives that do almost not raeding and writting anyways…). I believe I set ARC to either 4 or 8 GB, which should be plenty…
The screenshot below was while I was running apt update on 3 ubuntu server VM’s. Any ideas why or what is causing this? Its certainly not the end of the world, but it is a bit annoying as this machine should not be slow at anything I throw at it.