20+ ports of 100 gigabit for $300!? what’s the catch?
Intel Omni Path, that’s the catch. It’s not infiniband. It’s not ethernet. It’s intels own thing. Like David S. Pumpkins.
It was ahead of its time in 2015. In 2023 it’s just almost, but not quite, e-waste. Barely.
Stewardship (and forward momentum for the technology) Rests with Cornelius
HP Enterprise moved a lot of this hardware it seems. The market is currently flooded with the stuff.
One seller has over 2000 colorchip 100gb PHYs alone right now.
Proxmox and Omni-Path
Intel Omnipath iis really meant for message passing (MPI) with very low latency. There isn’t a lot of the typical networking machinery… as a result things like IPoIB (IP over Infiniband) tend to use more CPU than you’d expect. The PHY layer, of course, don’t care. It’s not unusual to use packet sizes like 8kb, 16kb, 32kb (and not sizes that are more ethernet-frame like).
For CEPH/storage clustering and Virtual Machine migration, however, the ability to do live migrations at 10-12 gigabytes per second on hardware that costs less than 1% of what it did new… it can be tempting to give it a try.
And it can work, if you are willing to roll up your sleeves.
Wait, what?
Aside: There were a lot of armchair experts that almost talked me out of buying this gear to give ti a try because almost all the documentation talks about OP as a message passing interface. But super compuiters gotta network too, and it seemed like it would actually work. Others have asked about Omni Path on proxmox forums and other internet forums but no one actually tried it until now. And it’s fine, for a pretty liberal definition of fine. ![]() (Homelab fine, not commercial environment fine *1 without accepting the risks.)
(Homelab fine, not commercial environment fine *1 without accepting the risks.)
Step-by-step to get Intel Omnipath Working for Proxmox on Linux
First, Researchers Wrangle Red Hat; RPMs are Alien to Debian
… but we can fix that with alien which wrangles RPMs with apt-based package management.
Before that, though, the first problem is that most of the packages that you can download from intel have been DELETED. Fortunately there are packages from 2021 and 2022 available at the Cornelius site, if you register.
Debian, interestingly, does have some packages that are useful such as
I used alien to install minimal packages to get IP working; the full suite of packages for Message Passing and High Performance Compute DOES seem to work however!
Debian’s Version
Before adding anything from Intel or Cornelius, Proxmox/Debian looks like this:
root@node4:~# apt search Omni-Path
Sorting... Done
Full Text Search... Done
ibverbs-providers/oldstable 33.2-1 amd64
User space provider drivers for libibverbs
libopamgt-dev/oldstable 10.10.3.0.11-1 amd64
Development files for libopamgt0
libopamgt0/oldstable 10.10.3.0.11-1 amd64
Omni-Path fabric management API library
libopasadb-dev/oldstable 10.10.3.0.11-1 amd64
Development files for libopasadb1
libopasadb1/oldstable 10.10.3.0.11-1 amd64
Omni-Path dsap API library
opa-address-resolution/oldstable 10.10.3.0.11-1 amd64
Omni-Path fabric address resolution manager
opa-basic-tools/oldstable 10.10.3.0.11-1 amd64
Tools to manage an Omni-Path Architecture fabric
opa-fastfabric/oldstable 10.10.3.0.11-1 amd64
Management node tools for an Omni-Path Architecture fabric
opa-fm/oldstable 10.10.3.0.11-1 amd64
Intel Omni-Path Fabric Management Software
it is possible to simply install these packages:
root@node4:~# apt install opa-fm opa-fastfabric opa-basic-tools opa-address-resolution
after that it seems like it attempts to boot everything up for you:
ip a
...
7: ibp133s0: <BROADCAST,MULTICAST> mtu 10236 qdisc noop state DOWN group default qlen 256
link/infiniband 80:81:00:02:fe:80:00:00:00:00:00:00:00:11:75:01:01:71:59:8a brd 00:ff:ff:ff:ff:12:40:1b:80:01:00:00:00:00:00:00:ff:ff:ff:ff
Step By Step
if you see the ibp* interface, even after reboot you can proceed to the Promox gui. I’m assuming you also don’t have a Proxmox cluster setup, and the reason you shelled out for fabulously obsolete and nearly abandoned gear is because you want a fast cluster? So let’s set that up.
Log into a node and make sure it is showing here:
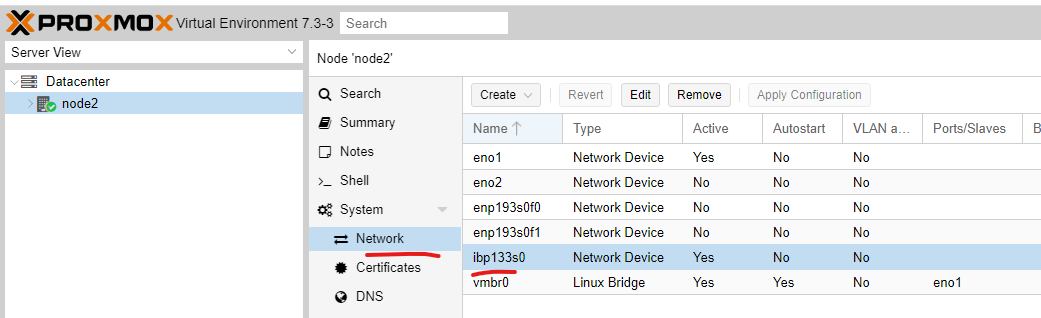
Then configure it with an IP on a subnet that won’t be used for anything but the private Omni Path network. As you plan in your mind know that ONLY Omni Path stuff will be connected to this. (Because of the packet sizes/MTU and differences between OP and everything else don’t be tempted to get fancy with bridges etc).
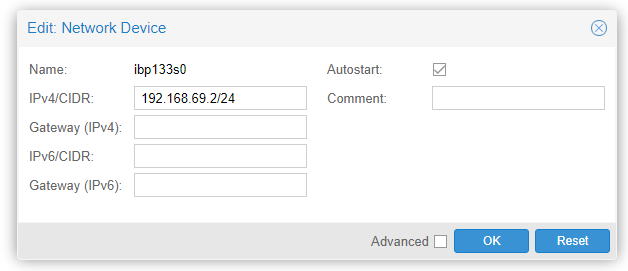
You should tick ‘advanced’ and set the MTU to 10200 as well for the Omni-Path “infiniband” network * (it makes it 2044 not 10200 but we’ll talk more about that in a bit)
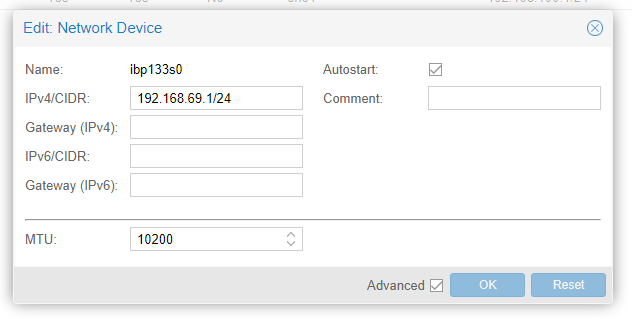
Do the same process on the other nodes and assign unique IPs to each one
From here go to Datacenter > create Cluster and be sure the cluster network is your Intel Omni-Path network.
Paste in the information from “cluster information” on the node you created the cluster on for the other nodes in the cluster. My cluster has 4 nodes total. Plus a separate storage node, also on Omni Path (Probably the only 45 drives chassis on Omnipath in the world!)
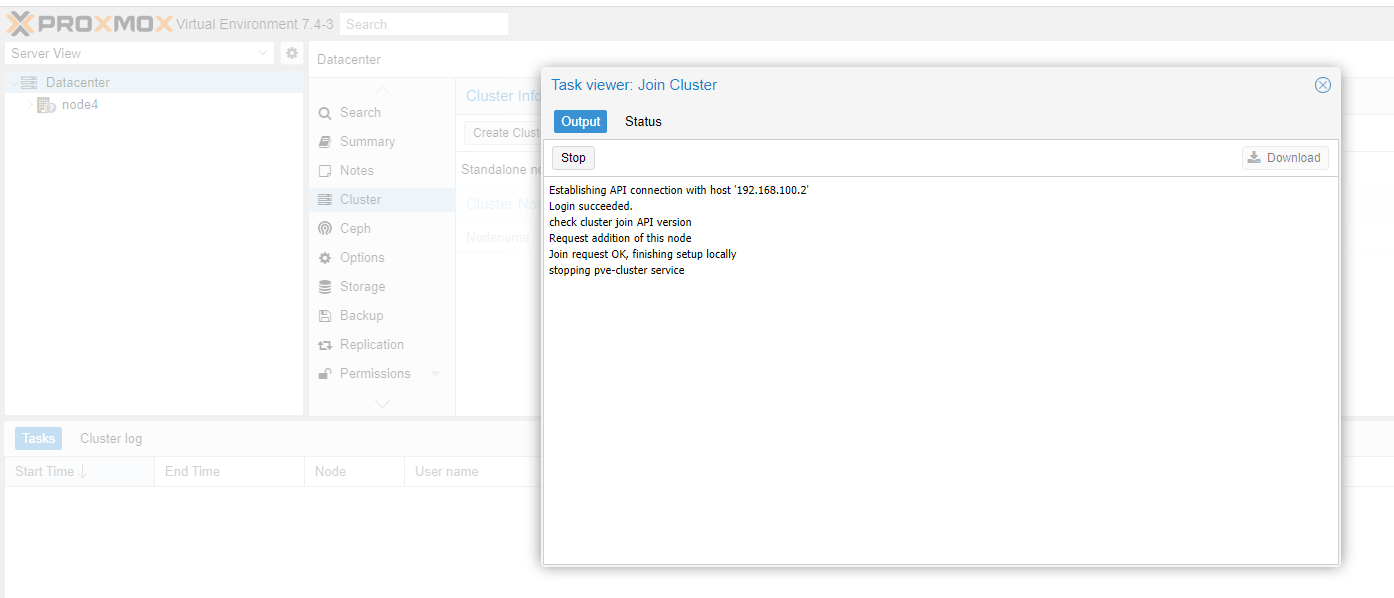
Don’t forget to go to cluster options and set it to use the 100gbs network for migrations. Also, it is probably a good idea to allow insecure migrations, which is breathtakingly faster.
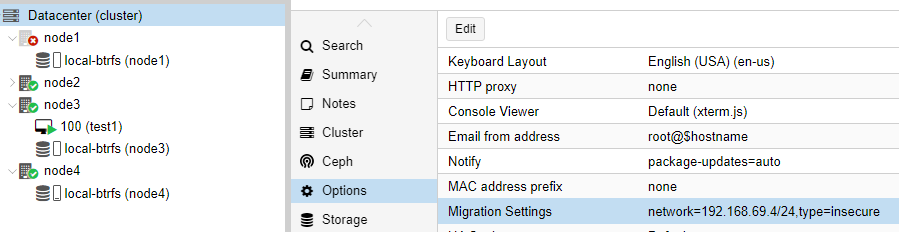
Nothing naughty to listen in on your Omni Path network traffic anyway, right? Lulz
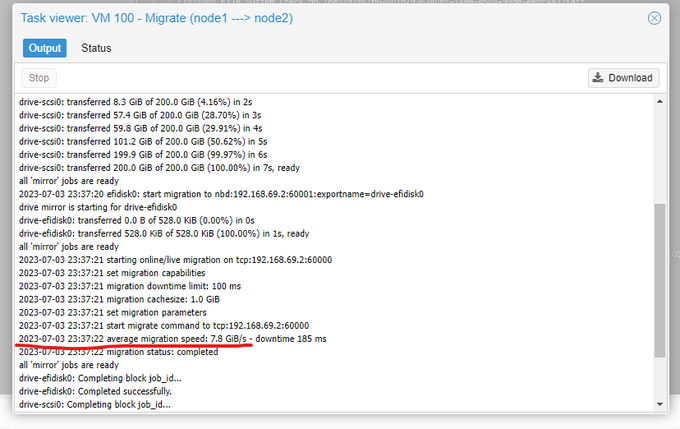
Benchmarking
Much to my surprise, it is possible to use tools like IPerf and achieve well over 10 gigabytes/second, and with less than 300 nanoseconds latency. Holy smokes!
By default the mtu us 2k; set 8k or larger.
ip link set dev ibp133s0 mtu 10236
for example
Understand though that even though dmesg says things like
[ 7.030465] sctp: Hash tables configured (bind 1024/1024)
[ 12.366070] hfi1 0000:85:00.0: opap133s0: MTU change on vl 1 from 10240 to 0
[ 12.366073] hfi1 0000:85:00.0: opap133s0: MTU change on vl 2 from 10240 to 0
[ 12.366076] hfi1 0000:85:00.0: opap133s0: MTU change on vl 3 from 10240 to 0
[ 12.366078] hfi1 0000:85:00.0: opap133s0: MTU change on vl 4 from 10240 to 0
[ 12.366079] hfi1 0000:85:00.0: opap133s0: MTU change on vl 5 from 10240 to 0
[ 12.366081] hfi1 0000:85:00.0: opap133s0: MTU change on vl 6 from 10240 to 0
[ 12.366083] hfi1 0000:85:00.0: opap133s0: MTU change on vl 7 from 10240 to 0
(this is telling us about the hardware packet queues, there are a bunch of them) this says our packet size is 10240 “infiniband” actually has 3 classes of MTU (usually).
For “connected” hosts the MTU can be as high as 65k; by default for “unconnected” hosts the max size is 2044. If you check ifconfig it’ll still show 2044 as the max packet size.
If you’re chasing the performance unicorn, you’ll have to install more stuff to get it working. first
cat /sys/class/net/ib133s0/mode
root@node1:~# cat /sys/class/net/ibp133s0/mode
datagram
root@node1:~#
show datagram mode; we need ipoibmodemtu in order to set connected mode (in order to set a larger mtu). Technically Omni-Path differs here from Infiniband in that it really is fine up to 10k, but you have to hack your kernel source to enable that . . . (I don’t wanna be the omni path kernel maintainer for off-label use cases; pls no)
I couldn’t find anyone maintaining a ipoibmodemtu package for Debian, though.
iperf ftw
Make sure your CPU frequency governor is set to performance.
The tradeoff here though is high cpu utilization. The 8-core EPYC 72F3 I was using in one system was pegged for I/O ~ only 40 gigabit.
These cards are really meant for low-latency MPI and not really IP.
Theoretically you could build the fastest lowest latency SAN from this technology. But the software for that was never really finished. I mean at a low level it is… but the performance here is both amazing and terrible, depending on what your goals are.
I like a 300 nanosecond ping. But at what cost!!!
I think I saw someone doing CUDA jobs over Omni Path! PCIe devices! But I couldn’t find any docs or details on that. Too bad…
I found this document from Kernel folks useful.
… technically this is talking about Infiniband, not Omni-Path…but at the linux kernel level some of the kernel modules sort of seem to bridge that gap. At least, when I loaded the modules I got:

Kernel Versions
Don’t be tempted to update to a 6.x kernel! Usually it is trouble free, expecially with newer Epyc Milan or Genoa processors. Heck Sapphire Rapids based CPUs also see huge performance benefit. Unfortunately, I think there is some bitrot in the kernel baseline infiniband code that affects us using older hardware.
apt install pve-kernel-5.19 pve-headers-5.19
This was one of only a few versions that had both stable infiniband networking code as well as stable no-soft-lock live migrations.
Hardware Setup
I am using 10 Intel HPA 101 PCIe x16 adapters (1x100gb interface), $1.00 each ColorChip 100gb PHY (crossover cables would be totally fine! But these were even cheaper!!) and a single Opal 14 24/48 port Omni Path switch.
Be aware that a 48 port omnipath switch is really only 24 ports; the other 24 ports will only run single lane/25 gig.
Can you cross the streams?
So if you don’t have an Omni-Path switch it is possible to use a crossover either with the colorchip PHY adapters or (the right) copper crossover cable. This mode is essentially plug-n-play for IP over “IB”
What about ethernet mode? Can I use these as a 100gbe into a 100gbe switch and not an Omni Path Switch?
Rumor has it these cards support an ethernet mode. I couldn’t get it to work with a Dell S5212F-ON 100gbe switch (using the SONiC OS) despite trying every combination of FEC and other negotiation settings.
Omni Path is not Ethernet… it is not 100gbe. I suspect if you did get it to work that it would be pretty high cpu utilization because of the way these cards are architected, though.
There is some other Broken Stuff Too
Libraries notes;
temps note;
IOMMU note; can be bad for passthrough.
Any kernel v6 or newer seems Oops a lot with infiniband, so that probably won’t work for you.
Older kernels have a soft lockup bug where live migration can hang the guests on Epyc systems. It’s not 100% stable. This is more to do with infiniband code than Omni-Path, I think.
Someone reported this bug a while ago, but since no one uses it, it’s not getting a lot of attention. It looks to be easy to fix though; I might take a crack at it later (or perhaps someone here in the community could). At any rate stick with the 5.x kernels now.
If you have the migration soft-lock bug, then there is probably a 5.x kernel you can find to fix that. For now stay away from PVE 6.x kernels.
I was experiencing this issue
[ 15.866734] ------------[ cut here ]------------
[ 15.866737] memcpy: detected field-spanning write (size 80) of single field "&wqe->wr" at drivers/infiniband/sw/rdmavt/qp.c:2043 (size 40)
[ 15.866777] WARNING: CPU: 48 PID: 959 at drivers/infiniband/sw/rdmavt/qp.c:2043 rvt_post_send+0x691/0x900 [rdmavt]
[ 15.866799] Modules linked in: ebtable_filter ebtables ip_set ip6table_raw iptable_raw ip6table_filter ip6_tables iptable_filter bpfilter sctp ip6_udp_tunnel udp_tunnel nf_tables softdog bonding tls nfnetlink_log nfnetlink opa_vnic rpcrdma ib_umad rdma_ucm ib_ipoib ipmi_ssif intel_rapl_msr intel_rapl_common amd64_edac edac_mce_amd kvm_amd kvm irqbypass crct10dif_pclmul polyval_clmulni polyval_generic ghash_clmulni_intel sha512_ssse3 aesni_intel crypto_simd cryptd rapl wmi_bmof pcspkr efi_pstore hfi1 ast rdmavt drm_shmem_helper ib_uverbs drm_kms_helper ccp syscopyarea sysfillrect k10temp ptdma sysimgblt acpi_ipmi ipmi_si ipmi_devintf ipmi_msghandler mac_hid zfs(PO) zunicode(PO) zzstd(O) zlua(O) zavl(PO) icp(PO) zcommon(PO) znvpair(PO) spl(O) vhost_net vhost vhost_iotlb tap ib_iser rdma_cm iw_cm ib_cm ib_core iscsi_tcp libiscsi_tcp libiscsi scsi_transport_iscsi drm sunrpc ip_tables x_tables autofs4 btrfs blake2b_generic xor raid6_pq libcrc32c simplefb crc32_pclmul ixgbe xhci_pci
[ 15.866879] xhci_pci_renesas xfrm_algo ahci nvme mdio libahci igb xhci_hcd i2c_algo_bit i2c_piix4 nvme_core dca nvme_common wmi
[ 15.866894] CPU: 48 PID: 959 Comm: kworker/u257:0 Tainted: P O 6.2.11-2-pve #1
[ 15.866899] Hardware name: GIGABYTE H242-Z11-00/MZ12-HD0-00, BIOS M11 05/30/2022
[ 15.866901] Workqueue: ib-comp-unb-wq ib_cq_poll_work [ib_core]
[ 15.866936] RIP: 0010:rvt_post_send+0x691/0x900 [rdmavt]
[ 15.866950] Code: a8 01 0f 85 9e fd ff ff b9 28 00 00 00 48 c7 c2 c0 c8 23 c1 48 89 de 48 c7 c7 00 c9 23 c1 c6 05 55 d8 00 00 01 e8 0f 0d 0a d1 <0f> 0b e9 75 fd ff ff 49 8b 75 28 49 8b 7d 50 44 89 5d b8 0f b6 56
[ 15.866953] RSP: 0018:ffff990202debb30 EFLAGS: 00010082
[ 15.866956] RAX: 0000000000000000 RBX: 0000000000000050 RCX: ffff8bbbadc20548
[ 15.866958] RDX: 00000000ffffffd8 RSI: 0000000000000027 RDI: ffff8bbbadc20540
[ 15.866960] RBP: ffff990202debbd0 R08: 0000000000000003 R09: 0000000000000001
[ 15.866962] R10: 0000000000ffff0a R11: 0000000000000080 R12: ffff8b7d423da898
[ 15.866963] R13: ffff9902068dd000 R14: ffff8b7d9970d000 R15: ffff8b7db1910000
[ 15.866965] FS: 0000000000000000(0000) GS:ffff8bbbadc00000(0000) knlGS:0000000000000000
[ 15.866968] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
[ 15.866969] CR2: 000055e01119f160 CR3: 0000002dec810001 CR4: 0000000000770ee0
[ 15.866972] PKRU: 55555554
[ 15.866973] Call Trace:
So again, this is not a production-stable idiot-proof plug-n-play setup.
I am impressed by how many people said it won’t work on other forums, though. In that respect, it basically was plug and play. Who knows, with more enthusiasts using this it might be a little more stable? ![]()
Common Physical Problems
Fiber PHY adapters are meant for shor tor long haul. The long haul ones can’t turn themselves down enough to not burn out the receiver on the far end. You may need fiber attenuators; I don’t recommend using the short fiber patch cables and colorchip PHY as I have; copper crossover for short distances would be a much better choice.
Omni Path can also be a bit flaky. I get messages like:
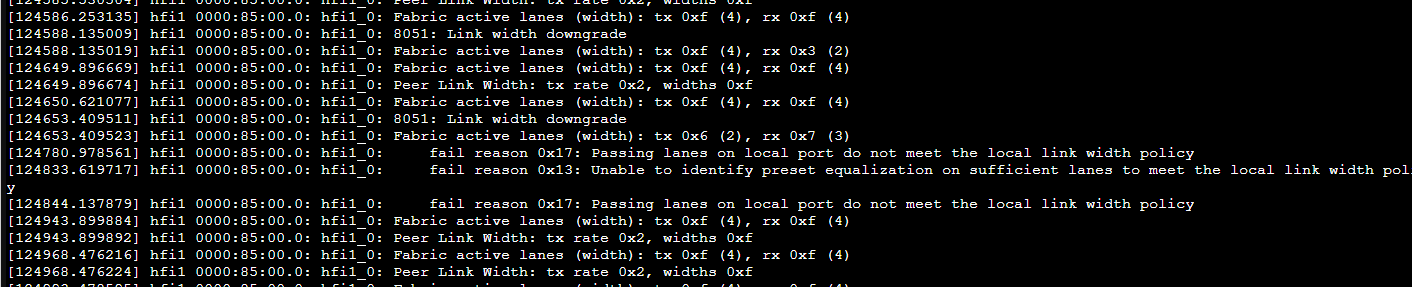
any time I just touch the mess-o-fiber cables at the top of rack.
This is almost certainly my own fault for using $1 fiber adapters and I recommend using copper 100g QSFP cables if you can find a cheap source (let me know as I need some too!)
I have already found a few ports on the Opal 14 OP switch that seem to work better than others for this reason, so don’t be afraid to experiment. Don’t count on all 24 ports working correctly; this is old equiipment after all.
It turns out the yellow ports are “short haul” ports, but they are 100g. That’s probably why they don’t work for me, but they should work at 100g.
More OPA Info
Here is a link to one of my colleagues (a Guru of Omni-Path) github with OPA tips
This git repo has a bunch of awesome tips I wish I’d had when I was setting this up!
In addition to that Cornelis Networks has a lot of docs and firmware updates you can get, for free, if you have the hardware:
https://customercenter.cornelisnetworks.com/
Signup there and look for
![]()
PCIIe3 for these cards is also a bit of an overstatement. EPYC, especially Rome, was a lot more fiddly getting these cards to consistently show up across a variety of motherboards. There is updated modern firmware for these cards though, which promises to improve things.
Even More Off-Label uses
Even though it’s not Infiniband, it looks and acts like infiniband in a lot of ways. You can share block devices via IB without the TCP stack as well, which is what I’m working on with our 45Drives Storinator.
You can share physical or virtual devices from a target (host/server) to an initiator (guest/client) system over an IB network, using iSCSI, iSCSI with iSER, or SRP. These methods differ from traditional file sharing (i.e. Samba or NFS) because the initiator system views the shared device as its own block level device, rather than a traditionally mounted network shared folder. i.e. fdisk /dev/block_device_id , mkfs.btrfs /dev/block_device_id_with_partition_number
Final Thoughts
I’d rather have Mellanox, to be honest. But Mellanox CX4 are still $100/card and there are no deals to be had on 100gbe switches. To be all in on a 10-node setup here and out around $500 US is an absolute steal but it is not without wrinkles. There is no real upgrade path and it won’t really be possible to plug in anything
The cards were also really finicky to get working on modern platforms. EPYC Genoa-based systems would fail to detect the PCIe cards unless you force PCIe3 mode in the bios (not all boards let you do this!) and even our Epyc Milan-based Gigabyte 2u2n system would not detect the IB cards on cold boots (but warm boots were always fine).
It sure is fast. And it wasn’t tooo much of a black hole to get working. Nevertheless this is not something I’d really recommend for any production enviromnent given that this hardware is already pretty well used and runs a bit hot.
With 12 ports active on the Opal 14 switch, it was consuming ~263 watts. I expected more given I was sending north of 1 terabit through the switch for testing? And a good bit of that power budget was likely the ColorChip PHY adapters.
Interesting times that 100GB intefaces are ~$25, or less if you buy in bulk.
Oh, and there are no windows drivers as far as I can tell. There is this weird java-based configuration app, but I haven’t managed to get it to operate properly yet.
Proxmox 8 Setup Notes
When I started this guide I was on Proxmox 7.4 with a custom kernel. Things that had been stable with Proxmox were a bit squirrely with Omnipath.
I am happy to report performance and stability has returned with these versions.
Linux node1 5.15.108-1-pve #1 SMP PVE 5.15.108-1 (2023-06-17T09:41Z) x86_64 GNU/Linux
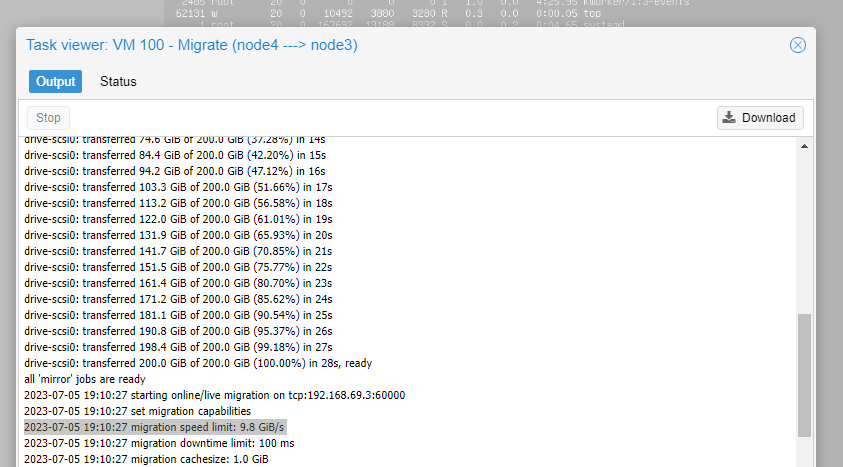
Speed is even better.
With kernel
Linux node1 6.2.16-3-pve #1 SMP PREEMPT_DYNAMIC PVE 6.2.16-3 (2023-06-17T05:58Z) x86_64 GNU/Linux
I do get the old lockup-on-migration with this. Feels like the old recurring issue like:
https://forum.proxmox.com/threads/online-migration-fails-from-6-3-to-6-4-with-cpu-set-to-amd-epyc-rome.89895/
but I haven’t had time to investigate further. This plus the infiniband bug makes me a little hesitant of trying newer 6.ish kernels.
It hangs hard always migrating FROM kernel 5.15 to 6.x but not FROM 6.x back to 5.15, interestingly. No oops message that I can see on the host or any indications anything has gone wrong in the VM guest.
This is maybe a cautionary tale to have 4+ machines in your cluster just so you can experiment with updates and migrations after every little change.
Proxmox Migrate Bug Fix
Are you having the Proxmox bug on AMD Epyc where it locks up after migration? I was having that problem until this kernel:
Linux node1 6.2.16-4-pve #1 SMP PREEMPT_DYNAMIC PVE 6.2.16-4 (2023-07-07T04:22Z) x86_64 GNU/Linux
it seems resolved on this config, even with the infiniband/omnipath drivers.
*1 I am using a 10gbe circuit as a “backup” PHY cluster connection so if the OP switch or nics go down, or a kernel update nukes support, I can limp along at a mere 10 gigabit. If you plan accordingly, maybe it would be okay in your situation.