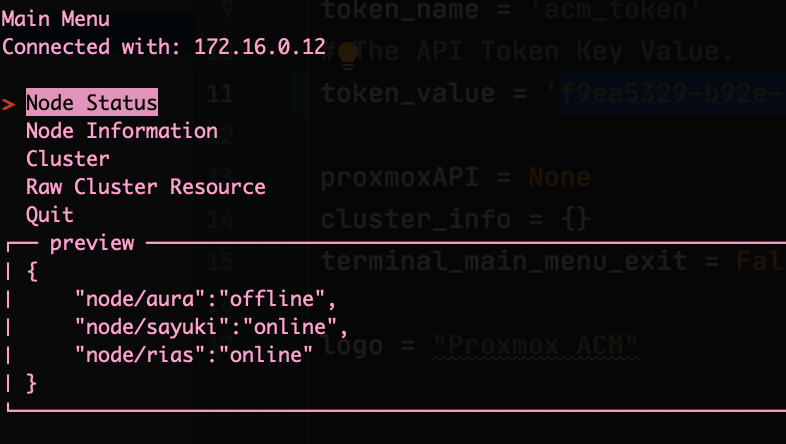
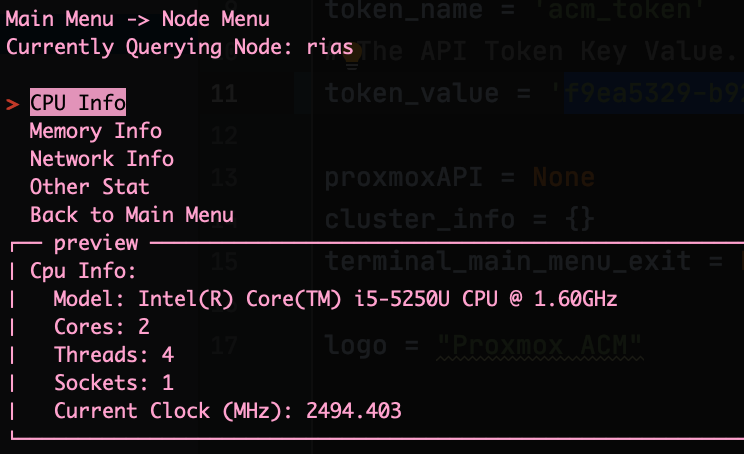
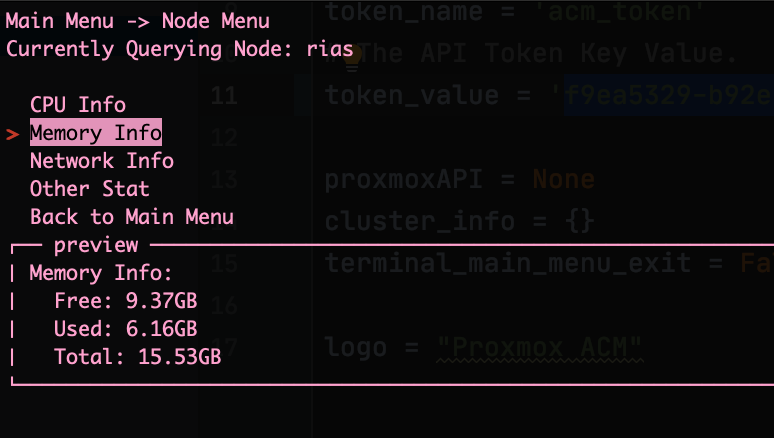
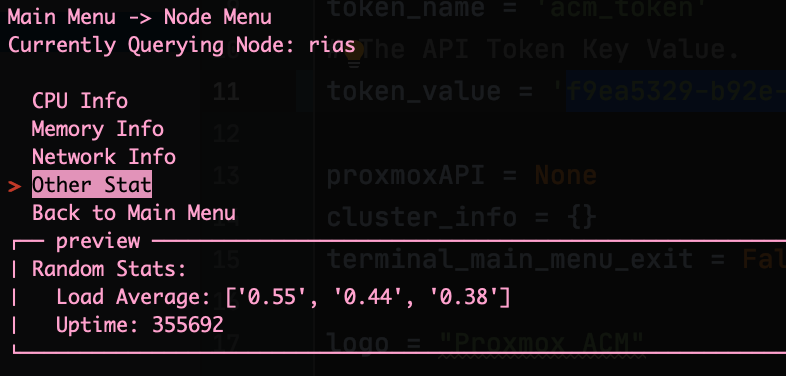
This past week has been interesting. I plagued myself with indecision of how I want the program to function. So much of this post will about my rational and how I decided on functionality. If you don’t want to read this long winded post, skip ahead to Changes.
TL/DR: I decided to use a database and make the system stateful.
Decisions
One of the things I really wanted to do with this program was keep it stateless, meaning all the information required for the program to operate (with the exception of the config file) would be pulled from the API.
This however produces a problem, one part of the operation is to prevent auto migrations of VMs or of VMs to/from a certain node.
The idea behind this functionality is to allow the operator to pin a VM to a node (if you have an application in running in a VM that’s particularly sensitive, it maybe beneficial to prevent it from moving) or even reserve a node in the cluster for the operators needs. To be clear, it won’t prevent manual migrations (either in the program via API or in the WebUI) only auto migrations being triggered by the program.
“Wait, hold up… in your amazing 6 step plan, the migration lock is on step 5! What gives?”
I shifted to doing it now as I noticed it had a larger impact than initially thought on the programs data handling. Hence I shifted to doing it now as I thought this may require some data management of some description. Turns out, I was right.
So here is what I tried and why I settled on what I did… a database.
- Store the migration flag in cluster.
- Store the flag in a local file.
- THEY’RE IN THE DATABASE!
1- At first I looked at storing the flag within the cluster itself and that would allow the program to remain stateless. pvesh can allow you to set a config variable (and hence also through the API), the problem is via the API you can’t apply a custom variable. Not a problem, I can store the migration flag in the node config in its description as it can take a string value. However I had doubts if this was a reliable way of doing this due to an issue I have experienced (and seen a few cases of it dotted around the web), the config sometimes resets on a node reboot.
A planned function is to have the cluster turn on and off nodes, so I have played with the wake-on-lan config option (where you store a MAC address for a node that will accept a WOL packet) and occasionally it would reset upon a node reboot.
This then lead me to numero 2.
2- Store the flag locally. This sounds pretty simple, on the surface, until you start picking apart what you need to store. So I need to store the ID of the node/VM, whether its a VM or node and a migration state. As the API operates using JSON formatting, my immediate logic was to follow the same convention.
What I quickly realised however is that I was attempting to re-invent the wheel. I was building a JSON handling database and it was crap.
This then lead me to numero 3.
3- Yes it’s a database. I ultimately decided that a database was the best idea, however what kind of database was the next question. There were two things that I thought were needed for this to fit nicely into this program.
- Light Weight.
- Not require any additional server setup.
So a light weight database was a functional requirement as a full blown Relational database like MySQL would be 100% overkill (maybe not on a large cluster with hundreds of VMs, but that isn’t the target setup here). As I was essentially building a document orientated database, I took to looking down this route.
The second requirement of no additional server was kind of limiting. A system like MongoDB would be pretty well suited to what I was doing, but also required additional setup. After some looking around I looked into TinyDB. This is a small document oriented database written within Python and ultimately was what I was trying to write.
Database
So after playing around, finding the pitfalls and looking into the full capabilities. I’ve got to say TinyDB has impressed me. I am slightly worried for future dev as written on their own “Why Use TinyDB?” Under the Why Not Use TinyDB is the following: access from multiple processes or threads
This posses an issue with say a separate thread doing migration functions. However I am hoping this won’t be an issue as the system doesn’t have a lot of data changing rapidly. Additionally the secondary threads will likely only be reading the database and not making changes.
Changes
0.0.2 (2020-11-12)
- Cleanup of Code.
- Applied proper Python forming to some functions.
- Added some more comments.
- Removal of ‘Network Info’ in node info menu.
- Added VM information querying.
- Added Migration controls to VM and Node Menu.
- Added TinyDB to store information and settings.
Screenshots
A lot of the changes have just been in how the program runs and doesn’t really have many user facing changes.
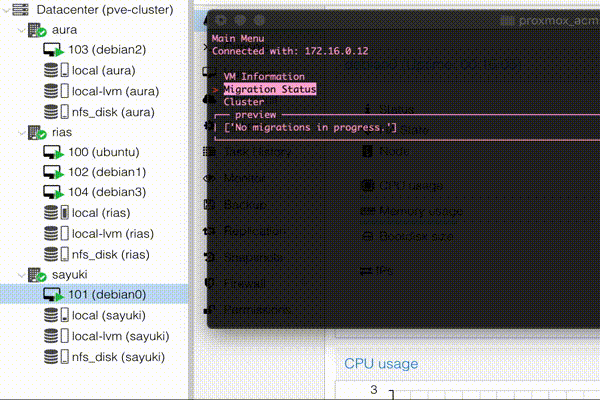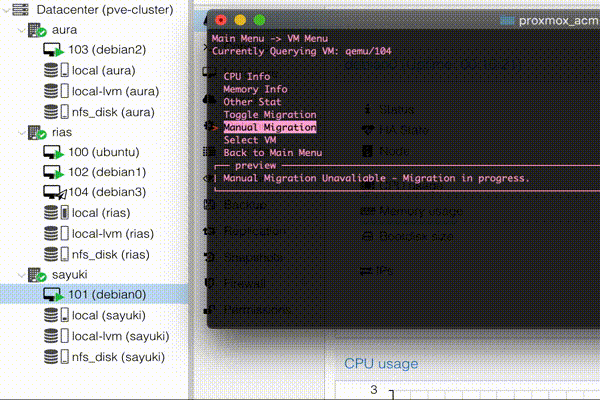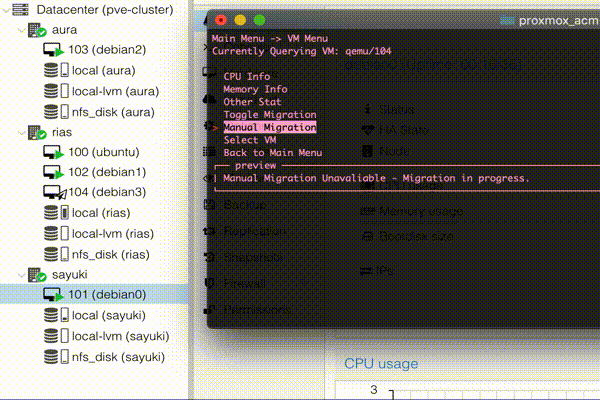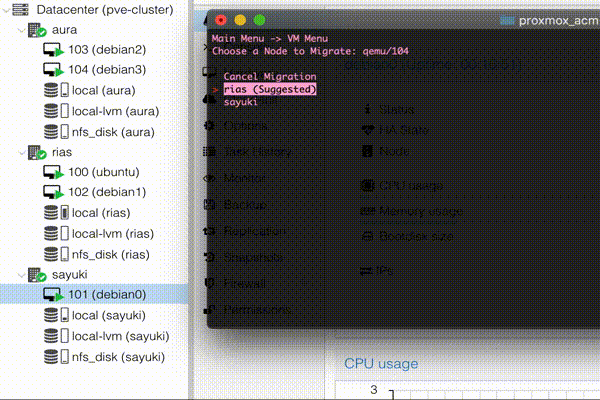
That said the Main Menu does now have the “VM Information” and “Rebuild Database” options
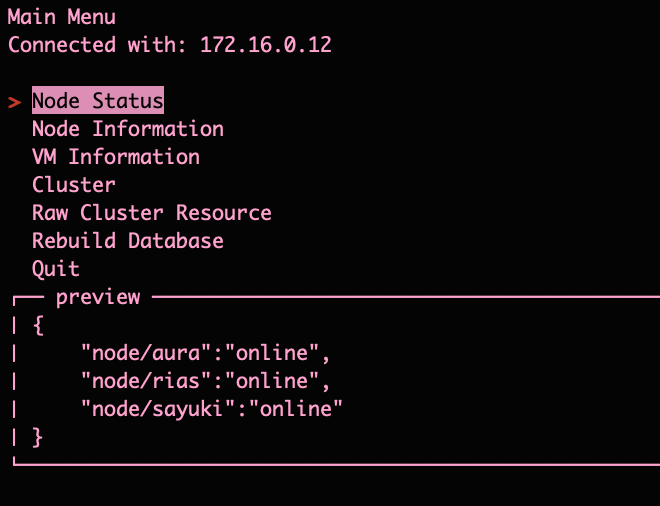
The “Rebuild Database” option is only in here at the minute as certain changes that happen in the cluster aren’t reflected in the database yet. Plus if it messes up, its a nice option to have to essentially say “reset all”. Later, I plan to put a small confirmation message in front of this option though.
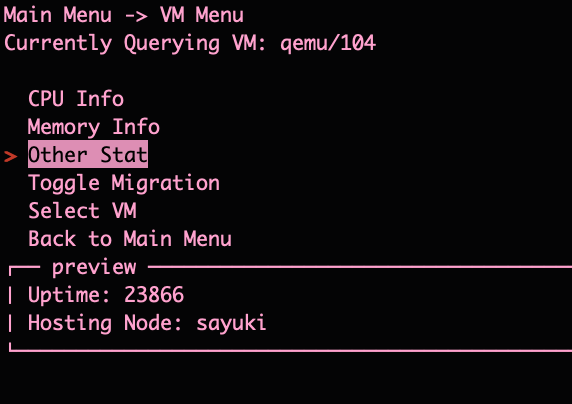
The VM Information is much like the node one. With the exception of the “Other Stat” displaying the node the VM resides on. “Toggle Migration” which does what it says on the tin and toggles the migration flag. “Select VM” is me playing around with being able to reselect a VM without having to exit to the main menu and re-enter the VM menu. I will likely reflect this change into the Node Information Menu as well.
What’s Next?
With my data handling dilemmas out of the way (for now) I am hoping to make faster progress through planned functioanlity. First off is to tackle the Manual Migration. I will likely push this as v0.0.3 without other changes.