Seems this way. The whole thing with setting the dies= option for the cache topology is something I learned not too long ago. It seems this behavior is not well documented and kind of experimental. I also was not able to benchmark significant performance improvements after making this change. It still seems plausible that given Windows history of not detecting topologies with AMD CPUs under heavy load or in certain workloads there might be an advantage when configuring it in a transparent way for Windows.
No problem  It’s approximately the same topic.
It’s approximately the same topic.
Can you put the return of lstopo command ?

So i lauched cinebench r15/20 in 2 configurations :
1-Current conf :
<cpu mode="host-passthrough" check="none">
<topology sockets="1" dies="1" cores="9" threads="2"/>
<cache mode="passthrough"/>
<feature policy="require" name="topoext"/>
</cpu>
cr15 :

cr20 :
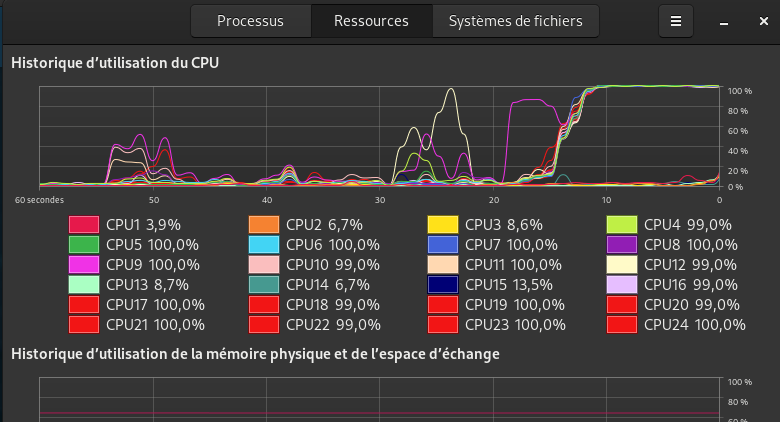
Finally, All cores (9/18T) in cputune are used by the VM.
I got 4800 in cr20 and 2000 in cr15.
2-modified conf :
<cpu mode="host-passthrough" check="none" migratable="on">
<topology sockets="1" dies="3" cores="3" threads="2"/>
<cache mode="passthrough"/>
<feature policy="require" name="topoext"/>
</cpu>
cr15 :
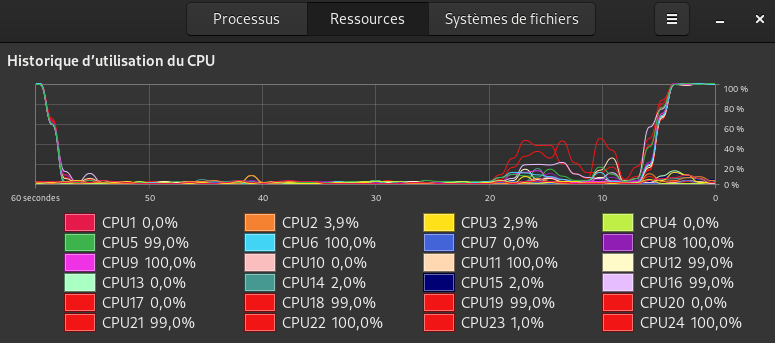
cr20 :
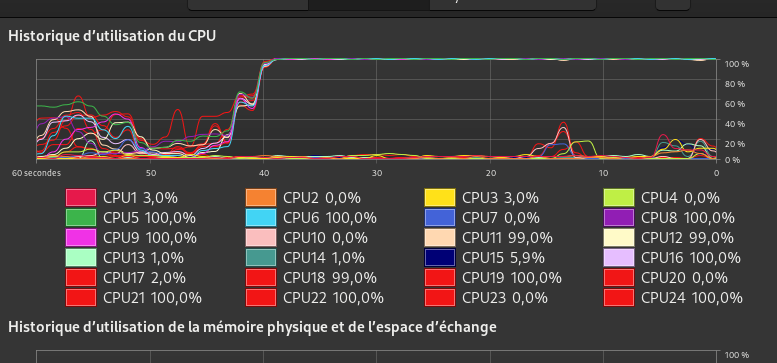
Only 6c/12T are used.
I got 4000 in cr20 and 1675 in cr15.
Conclusion :
The current configuration is better for now. (1 die, 9c, 2T for the topology)
1 Like
I never tried it between different CCDs. You could check with Coreinfo if the cache is even listed correctly. Maybe when we cross the CCD border we need to work with sockets. I maybe investigate this another time, but for now I am happy that you are finally able to use all your cores. If you have an application that only utilized one single VCPU I would guess that it is an problem with the application.
Hmm crossing CCD means your cache won’t be utilised accordingly and you will pass through the Infinity Fabric. Now I kinda wish to have kept my Threadripper 1950x to see how it would work with different NUMA configurations.
I just checked with Cinebench R23 (the version from the Microsoft store) and I get 9057pts with 2 dies and 3 cores and 9063pts with 1 dies and 6 cores in the multicore benchmark. It seems to have something to do with the CCDs that your values vary so greatly between the different settings.
1 Like
I will stick to 1 socket 2 dies 4 cores and 2 threads as to me it makes more sense - thanks for the feedback
I would be interested in benchmarks from your setup. For me the performance of the VM running on cores 6-12 is about the same with both settings. With dies=2 Coreinfo sees 3 cores assigned to each L3 cache unit, while with dies=1 it sees 4 cores assigned to one cache unit and 2 cores assigned to the other.
I got 12370pts in cr23 (microsoft store) with this conf :
[..]
<vcpu placement="static">18</vcpu>
[..]
<cpu mode="host-passthrough" check="none">
<topology sockets="1" dies="1" cores="9" threads="2"/>
<cache mode="passthrough"/>
<feature policy="require" name="topoext"/>
</cpu>
[..]
Coreinfo v3.5 - Dump information on system CPU and memory topology
Copyright (C) 2008-2020 Mark Russinovich
Sysinternals - www.sysinternals.com
AMD Ryzen 9 3900X 12-Core Processor
AMD64 Family 23 Model 113 Stepping 0, AuthenticAMD
Microcode signature: 00000000
HTT * Multicore
HYPERVISOR * Hypervisor is present
VMX - Supports Intel hardware-assisted virtualization
SVM * Supports AMD hardware-assisted virtualization
X64 * Supports 64-bit mode
SMX - Supports Intel trusted execution
SKINIT - Supports AMD SKINIT
NX * Supports no-execute page protection
SMEP * Supports Supervisor Mode Execution Prevention
SMAP * Supports Supervisor Mode Access Prevention
PAGE1GB * Supports 1 GB large pages
PAE * Supports > 32-bit physical addresses
PAT * Supports Page Attribute Table
PSE * Supports 4 MB pages
PSE36 * Supports > 32-bit address 4 MB pages
PGE * Supports global bit in page tables
SS - Supports bus snooping for cache operations
VME * Supports Virtual-8086 mode
RDWRFSGSBASE * Supports direct GS/FS base access
FPU * Implements i387 floating point instructions
MMX * Supports MMX instruction set
MMXEXT * Implements AMD MMX extensions
3DNOW - Supports 3DNow! instructions
3DNOWEXT - Supports 3DNow! extension instructions
SSE * Supports Streaming SIMD Extensions
SSE2 * Supports Streaming SIMD Extensions 2
SSE3 * Supports Streaming SIMD Extensions 3
SSSE3 * Supports Supplemental SIMD Extensions 3
SSE4a * Supports Streaming SIMDR Extensions 4a
SSE4.1 * Supports Streaming SIMD Extensions 4.1
SSE4.2 * Supports Streaming SIMD Extensions 4.2
AES * Supports AES extensions
AVX * Supports AVX instruction extensions
FMA * Supports FMA extensions using YMM state
MSR * Implements RDMSR/WRMSR instructions
MTRR * Supports Memory Type Range Registers
XSAVE * Supports XSAVE/XRSTOR instructions
OSXSAVE * Supports XSETBV/XGETBV instructions
RDRAND * Supports RDRAND instruction
RDSEED * Supports RDSEED instruction
CMOV * Supports CMOVcc instruction
CLFSH * Supports CLFLUSH instruction
CX8 * Supports compare and exchange 8-byte instructions
CX16 * Supports CMPXCHG16B instruction
BMI1 * Supports bit manipulation extensions 1
BMI2 * Supports bit manipulation extensions 2
ADX * Supports ADCX/ADOX instructions
DCA - Supports prefetch from memory-mapped device
F16C * Supports half-precision instruction
FXSR * Supports FXSAVE/FXSTOR instructions
FFXSR * Supports optimized FXSAVE/FSRSTOR instruction
MONITOR - Supports MONITOR and MWAIT instructions
MOVBE * Supports MOVBE instruction
ERMSB - Supports Enhanced REP MOVSB/STOSB
PCLMULDQ * Supports PCLMULDQ instruction
POPCNT * Supports POPCNT instruction
LZCNT * Supports LZCNT instruction
SEP * Supports fast system call instructions
LAHF-SAHF * Supports LAHF/SAHF instructions in 64-bit mode
HLE - Supports Hardware Lock Elision instructions
RTM - Supports Restricted Transactional Memory instructions
DE * Supports I/O breakpoints including CR4.DE
DTES64 - Can write history of 64-bit branch addresses
DS - Implements memory-resident debug buffer
DS-CPL - Supports Debug Store feature with CPL
PCID - Supports PCIDs and settable CR4.PCIDE
INVPCID - Supports INVPCID instruction
PDCM - Supports Performance Capabilities MSR
RDTSCP * Supports RDTSCP instruction
TSC * Supports RDTSC instruction
TSC-DEADLINE * Local APIC supports one-shot deadline timer
TSC-INVARIANT - TSC runs at constant rate
xTPR - Supports disabling task priority messages
EIST - Supports Enhanced Intel Speedstep
ACPI - Implements MSR for power management
TM - Implements thermal monitor circuitry
TM2 - Implements Thermal Monitor 2 control
APIC * Implements software-accessible local APIC
x2APIC * Supports x2APIC
CNXT-ID - L1 data cache mode adaptive or BIOS
MCE * Supports Machine Check, INT18 and CR4.MCE
MCA * Implements Machine Check Architecture
PBE - Supports use of FERR#/PBE# pin
PSN - Implements 96-bit processor serial number
PREFETCHW * Supports PREFETCHW instruction
Maximum implemented CPUID leaves: 00000010 (Basic), 8000001F (Extended).
Maximum implemented address width: 48 bits (virtual), 40 bits (physical).
Processor signature: 00870F10
Logical to Physical Processor Map:
**---------------- Physical Processor 0 (Hyperthreaded)
--**-------------- Physical Processor 1 (Hyperthreaded)
----**------------ Physical Processor 2 (Hyperthreaded)
------**---------- Physical Processor 3 (Hyperthreaded)
--------**-------- Physical Processor 4 (Hyperthreaded)
----------**------ Physical Processor 5 (Hyperthreaded)
------------**---- Physical Processor 6 (Hyperthreaded)
--------------**-- Physical Processor 7 (Hyperthreaded)
----------------** Physical Processor 8 (Hyperthreaded)
Logical Processor to Socket Map:
****************** Socket 0
Logical Processor to NUMA Node Map:
****************** NUMA Node 0
No NUMA nodes.
Logical Processor to Cache Map:
**---------------- Data Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
**---------------- Instruction Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
**---------------- Unified Cache 0, Level 2, 512 KB, Assoc 8, LineSize 64
********---------- Unified Cache 1, Level 3, 16 MB, Assoc 16, LineSize 64
--**-------------- Data Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
--**-------------- Instruction Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
--**-------------- Unified Cache 2, Level 2, 512 KB, Assoc 8, LineSize 64
----**------------ Data Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
----**------------ Instruction Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
----**------------ Unified Cache 3, Level 2, 512 KB, Assoc 8, LineSize 64
------**---------- Data Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
------**---------- Instruction Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
------**---------- Unified Cache 4, Level 2, 512 KB, Assoc 8, LineSize 64
--------**-------- Data Cache 4, Level 1, 32 KB, Assoc 8, LineSize 64
--------**-------- Instruction Cache 4, Level 1, 32 KB, Assoc 8, LineSize 64
--------**-------- Unified Cache 5, Level 2, 512 KB, Assoc 8, LineSize 64
--------********-- Unified Cache 6, Level 3, 16 MB, Assoc 16, LineSize 64
----------**------ Data Cache 5, Level 1, 32 KB, Assoc 8, LineSize 64
----------**------ Instruction Cache 5, Level 1, 32 KB, Assoc 8, LineSize 64
----------**------ Unified Cache 7, Level 2, 512 KB, Assoc 8, LineSize 64
------------**---- Data Cache 6, Level 1, 32 KB, Assoc 8, LineSize 64
------------**---- Instruction Cache 6, Level 1, 32 KB, Assoc 8, LineSize 64
------------**---- Unified Cache 8, Level 2, 512 KB, Assoc 8, LineSize 64
--------------**-- Data Cache 7, Level 1, 32 KB, Assoc 8, LineSize 64
--------------**-- Instruction Cache 7, Level 1, 32 KB, Assoc 8, LineSize 64
--------------**-- Unified Cache 9, Level 2, 512 KB, Assoc 8, LineSize 64
----------------** Data Cache 8, Level 1, 32 KB, Assoc 8, LineSize 64
----------------** Instruction Cache 8, Level 1, 32 KB, Assoc 8, LineSize 64
----------------** Unified Cache 10, Level 2, 512 KB, Assoc 8, LineSize 64
----------------** Unified Cache 11, Level 3, 16 MB, Assoc 16, LineSize 64
Logical Processor to Group Map:
****************** Group 0
1 Like
Sure I can run a few things. My current settings are:
[..]
<cputune>
<vcpupin vcpu="0" cpuset="4"/>
<vcpupin vcpu="1" cpuset="20"/>
<vcpupin vcpu="2" cpuset="5"/>
<vcpupin vcpu="3" cpuset="21"/>
<vcpupin vcpu="4" cpuset="6"/>
<vcpupin vcpu="5" cpuset="22"/>
<vcpupin vcpu="6" cpuset="7"/>
<vcpupin vcpu="7" cpuset="23"/>
<vcpupin vcpu="8" cpuset="12"/>
<vcpupin vcpu="9" cpuset="28"/>
<vcpupin vcpu="10" cpuset="13"/>
<vcpupin vcpu="11" cpuset="29"/>
<vcpupin vcpu="12" cpuset="14"/>
<vcpupin vcpu="13" cpuset="30"/>
<vcpupin vcpu="14" cpuset="15"/>
<vcpupin vcpu="15" cpuset="31"/>
<emulatorpin cpuset="0-3,8-11,16-19,24-27"/>
<iothreadpin iothread="1" cpuset="0-3,8-11,16-19,24-27"/>
</cputune>
<cpu mode="host-passthrough" check="none" migratable="on">
<topology sockets="1" dies="2" cores="4" threads="2"/>
<cache mode="passthrough"/>
<feature policy="require" name="topoext"/>
</cpu>
[..]I can think of the following tests
- Test 1
<topology sockets="1" dies="2" cores="4" threads="2"/>- Test 2
<topology sockets="1" dies="4" cores="2" threads="2"/>- Test 3
<topology sockets="1" dies="1" cores="8" threads="2"/>- Test 4
<topology sockets="1" dies="1" cores="16" threads="1"/>I’m not sure if Test 4 is going to be accepted even but can give it a go Any other configuration you’d like to see?
For all the above I suppose you’d want coreinfo output along with some kind of benchmark result - right?
Just to be clear, we are interesting to the delta between the different dies and core configuration, not the actual performance of the benchmark as this is affected on many factors affecting the benchmark result (PBO max boost, current temperature, CPU cooler etc)
According to the Zen 2 Architecture 3950X have 4 CCX and 4 L3 cache shared between all cores within the CCX. Passing to the VM half a CCX makes no sense (unless you have to) because then the cache would be poluted from host data - hence why I’m passing CCX 1 and CCX3 in my case - resulting in 8 cores 16 threads.
2 Likes
I don’t know if the last one if possible either but these tests would be great. Also correct, we are mostly interested in the delta. The score should be in the general direction of a standard value still.
1 Like
OK I will try to run those and gather the results - maybe even run them multiple times and get a median value to take out outliers. Probably repost here tomorrow though as it’s pretty late now 
1 Like
While the performance you reported is fine the reported cache layout is not in line with the physical layout. Here you can see that 4 cores are in the first two groups and then 1 core in the last. I am really wondering why you had worse performance with dies=3. We’ll see what artafinde reports tomorrow.
Thank you, I am curious.
With 3 dies 3 cores and 2T  :
:
Logical to Physical Processor Map:
**---------- Physical Processor 0 (Hyperthreaded)
--**-------- Physical Processor 1 (Hyperthreaded)
----**------ Physical Processor 2 (Hyperthreaded)
------**---- Physical Processor 3 (Hyperthreaded)
--------**-- Physical Processor 4 (Hyperthreaded)
----------** Physical Processor 5 (Hyperthreaded)
Logical Processor to Socket Map:
******------ Socket 0
------****** Socket 1
Logical Processor to NUMA Node Map:
************ NUMA Node 0
No NUMA nodes.
Logical Processor to Cache Map:
**---------- Data Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
**---------- Instruction Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
**---------- Unified Cache 0, Level 2, 512 KB, Assoc 8, LineSize 64
******------ Unified Cache 1, Level 3, 16 MB, Assoc 16, LineSize 64
--**-------- Data Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
--**-------- Instruction Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
--**-------- Unified Cache 2, Level 2, 512 KB, Assoc 8, LineSize 64
----**------ Data Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
----**------ Instruction Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
----**------ Unified Cache 3, Level 2, 512 KB, Assoc 8, LineSize 64
------**---- Data Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
------**---- Instruction Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
------**---- Unified Cache 4, Level 2, 512 KB, Assoc 8, LineSize 64
------****** Unified Cache 5, Level 3, 16 MB, Assoc 16, LineSize 64
--------**-- Data Cache 4, Level 1, 32 KB, Assoc 8, LineSize 64
--------**-- Instruction Cache 4, Level 1, 32 KB, Assoc 8, LineSize 64
--------**-- Unified Cache 6, Level 2, 512 KB, Assoc 8, LineSize 64
----------** Data Cache 5, Level 1, 32 KB, Assoc 8, LineSize 64
----------** Instruction Cache 5, Level 1, 32 KB, Assoc 8, LineSize 64
----------** Unified Cache 7, Level 2, 512 KB, Assoc 8, LineSize 64
Logical Processor to Group Map:
************ Group 0
1 Like
This is strange, it seems that only 6 cores with their according cache have been assigned to your VM. The last 3 cores as well as their L3 cache is not listed. Thank you for checking this!
1 Like
OK I performed the tests we discussed previously on the VM.
Results are anticlimactic and confusing  - to me at least.
- to me at least.
Test methodology:
- Adjust the libvirt xml to the test setting
- Start the VM
- Execute
coreinfoand log to file - Limit the host executing programs as much as feasible possible (or at least keep them at same programs through the period of tests)
- Mark AIO water temperature
- Execute Cinebench R20 (stand alone)
- Wait for AIO temperature to drop to initial levels
- Repeat Cinebench R20 benchmark
- Repeat last 2 steps for a total of 5 times
Results
Cinebench R20 scores (median)
Test 1: 4677
Test 2: 4681
Test 3: 4677
Test 4: 4647
Coreinfo L3 Cache
The coreinfo shows no difference in Cache map between the tests  I think my assumption that the
I think my assumption that the <cache mode="passthrough"/> “corrects” any mistakes in topology might be true.
Observations
- Between 1,2,3 tests where SMT is used I see no real difference on performance - 4 points in the Cinebench R20 scores are withing error limits.
Notes
The tests are performed without isolating the 8 cores on the hosts. This mean the host could still use these cores for something and pollute the L3 cache. I’ve tried to limit the processes running in the hosts but it could have skewed the results.
I think though this won’t show much of a difference on the results because I performed the runs 5 times on each test and because the host have 8 other cores to use which basically were idle during the period of the tests.
Raw data
Tests definitions
Test 1
<topology sockets="1" dies="2" cores="4" threads="2"/>Test 2
<topology sockets="1" dies="4" cores="2" threads="2"/>Test 3
<topology sockets="1" dies="1" cores="8" threads="2"/>Test 4
<topology sockets="1" dies="1" cores="16" threads="1"/>Coreinfo logs
The fact that coreinfo-1.txt and coreinfo-2.txt are identical is not a mistake - I double checked.
coreinfo-1.txt (7.1 KB)
coreinfo-2.txt (7.1 KB)
coreinfo-3.txt (7.1 KB)
coreinfo-4.txt (7.3 KB)
Cinebench R20 Raw results
| Run 1 | Run 2 | Run 3 | Run 4 | Run 5 | Median | |
|---|---|---|---|---|---|---|
| Test 1 Score | 4686 | 4650 | 4677 | 4662 | 4705 | 4677 |
| Test 2 Score | 4689 | 4668 | 4694 | 4681 | 4666 | 4681 |
| Test 3 Score | 4676 | 4672 | 4677 | 4685 | 4697 | 4677 |
| Test 4 Score | 4561 | 4647 | 4642 | 4662 | 4687 | 4647 |
3 Likes
Interesting, thank you for taking the time to test this. When you look at the last post from Ur4m3sh1 you can see that the layout can be detected wrong, at least on a 3900X. In his case with dies=3 the VM even missed to allocate 3 cores somehow. The internal workings and correlation between the CPU architecture and these settings seem to elude me still.
By the way, if you are in the mood for some optimization may I point you to vfio-isolate. The software requires a manual created configuration file but makes proper isolation between the VM and the host possible. While using a VM utilizing vfio-isolate the host won’t be able the schedule tasks on the cores used by the VM. There is also a python package and an entry in the AUR for this.
1 Like
I had seen something similar in the Archlinux Wiki but I’d go with systemd approach as I tend to use stuff I already have installed. But having try this python script seems rather simple so I might stick to it.
The command I used for my vm was:
vfio-isolate -u /tmp/undo-cpu_isolation \
cpuset-create --cpus C0-3,8-11,16-19,24-27 /host.slice \
cpuset-create --cpus C4-7,12-15,20-23,28-31 -nlb /vm.slice \
move-tasks / /host.slice@anon27075190 You mentioned something about a config file, I check the GitHub vfio-isolate and there’s no mention of a config file. Also any idea how to bind the two commands when starting / stopping the VM?
@artafinde : Sorry I did not know that this was not part of the Github page. I have the following hook script /etc/libvirt/hooks/qemu in place. It is executed every time a VM starts or stops.
#!/bin/bash
if [ "$1" != "gaming" ]; then
exit 0
fi
RSET=/
HSET=/host.slice
HNODE=C0-4,12-16
MNODE=C6-11,18-23
UNDOFILE=/var/run/libvirt/qemu/vfio-isolate-undo.bin
disable_isolation () {
vfio-isolate \
restore $UNDOFILE
taskset -pc 0-23 2
}
enable_isolation () {
vfio-isolate cpuset-delete $HSET
vfio-isolate \
-u $UNDOFILE \
drop-caches \
cpuset-create --cpus $HNODE $HSET \
compact-memory \
move-tasks $RSET $HSET \
cpu-governor performance $MNODE \
irq-affinity mask $MNODE
taskset -pc 0-4,12-16 2
}
case "$2" in
"prepare")
enable_isolation
;;
"started")
;;
"release")
disable_isolation
;;
esac
2 Likes