I’m working on a project for a client of mine who requires a networked data store for hosting lots of virtualized servers using VMWare. Most of the servers will be running financial applications, so I need to find a COMPLETELY redundant solution. Everything from a bad drive to a bad CPU needs to have automatic failover w/o losing any data in the process.
Doing this on the cheap, however, is not an easy thing to do. After a week or so of research, I think that ZFS may be the way to go. I’m just looking for the opinions of people who have worked extensively with ZFS to make sure that I’m not insane, and make sure I’m not missing anything critical. I have some experience with FreeNAS, but I’ve never done anything to this level with ZFS.
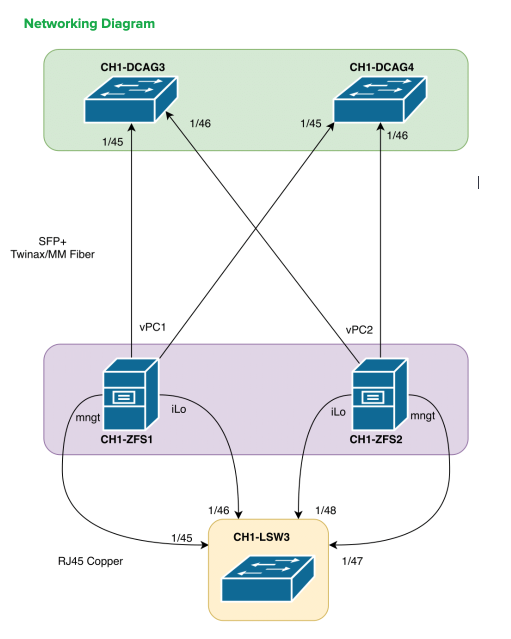
Currently, the configuration I’m planning on going with is based on dual HP Proliant DL360p G8 Nodes w/ D3600 JBOD.
2x DL360e G8 Server
Dual Xeon E5-2430
32 GB ECC RAM
Intel Pro Dual SFP+ Network Card
HP H241 Host Bus Adapter
2x Samsung 256GB SSD ( RAID1 - Boot )
1x Samsung 512GB SSD ( L2ARC )
1x HP SW D3600
10x HP 4TB Dual Port SAS HDD ( RAID 10 - Storage )
2x HGST ZeusRAM 8G SSD (RAID 1 - ZIL/SLOG )
In theory, this should allow for failure of any part in the system, without losing data and without downtime. Both G8 nodes will be configured in HA using Corosync/Pacemaker as recommended by this article.
Please let me know what you guys think about this configuration. I’m looking to be able to get about 3-4Gb/s worth of combined write/read performance, with most of the applications running in VMWare being write intensive. I am looking to start placing orders in about a week but wanted to have a quick sanity check before spending the money.
Your solution has a high potential of split-brain and that could translate into a nightmare… ZFS may be great but server/network fail / glitch is always a possibility.
GlusterFS would be great for that.
Not only it will perform well if configured and tuned rightfully, it can scale as much as you want, it is a solid SDN solution and very flexible. It integrates well with OpenStack, oVirt, etc. It can be configured to provide clustered Samba services with CTDB. It can be configured to provide clustered NFS. It works well with KVM. etc etc etc.
I’m just finishing a migration for KVM Virtualisation (60 virtual servers) on a 48 TB GlusterFS 3 way replication cluster: Server redundancy with automatic Quorum, Hard drive redundancy (RAID), Scalable and flexible. And it will do geo-replication too!
Looks like you’re after “fault-tolerance”, not just HA. Kind of nitpicking, but HA has a lower threshold.
I would scrap the zil and the l2arc and just buy more ram unless you’re hitting the system max, in which case I’d add a lower capacity l2arc.
I’ve never used zil, but it’s my impression that you should not look at it as a write cache. It is a write log. It’s not there to augment performance. I’m not sure what your goal is with the zil, but something to keep in mind.
Also, ZoL is still working on TRIM, so that’s something to consider with the SSDs.
VMWare has their own proprietary stuff for this (vSAN I think?). Outside of that, you have NFS and iSCSI for network datastores and that’s it.
I believe you can back gluster with zfs and get best of both worlds. Correct me if I’m wrong…
At least from the research I did prior to coming up with a plan for this, Adding the GlusterFS layer on top of ZFS would create additional overhead which could impact performance. I don’t have enough hardware to test this for myself, although I do agree that there is the possibility of issues occurring with the two independent nodes failover not working correctly.
I agree ZFS is great but when you have multi-nodes redundancy with GlusterFS it is, IMHO, of a lesser importance. We have the classic nodes in production: CentOS 7 with GlusterFS on top of LVM / XFS and it works great. When properly setup and tuned, it provides a very good performance too.
Currently I’m just planning on using the two ZFS servers as fault tolerance incase for some reason one of the physical servers is to fail/completely crash. The secondary server would only ever take over during planned maintenance, and in an emergency if ZFS/Linux crashes completely on ZFS1.
After reading the article you referenced the only problem I see with your setup as laid out is the L2ARC per host. The hosts need to share that via the JBOD or else you would possibly end up with disparate data between them, more so if you try active/active pinned ZFS pools. SAS SSD’s that work well for this are not hard to find via ebay and most are lightly used something like a SanDisk Optimus 200GB should be $100 or less. I use them for ZIL/SLOG as the ZeusRAM was out of scope for what I needed.
I was unaware that the L2ARC needed to be available to both hosts. It was my understanding that a L2ARC failure wouldn’t result in any data loss, although the pool would have slower read speeds. So it was my assumption that I could have them be separate and fit another RAID1 vdev into the pool.
Since this is the case it looks like I will have to go with 4x RAID1 vdevs, with one drive set as spare.
I also think that L2ARC is just a cache, and logically you should be able to import the pool without the L2ARC, however you have something to test. Without the ZIL you might have data loss issues, but that is not what you are talking about.
If zfs crashes completely on zfs1 then you might have on disk corruption so zfs2 won’t do you any good on a shared jbod, you would need some kind of delayed replication to a separate disk pool, or are you regarding this situation as a data recovery event rather than HA?
It’s great to see more Chicago people around! We decided to go with the following:
2x DL360e G8 Server
Dual Xeon E5-2430
63 GB ECC RAM
Mycrom Dual SFP+ Network Card
HP H241 Host Bus Adapter
2x HGST 200GB SAS SSD ( RAID1 - Boot )
1x Seagate Nytro 800GB SAS SSD ( L2ARC )
1x HP SW D3600
10x HP 6TB Dual Port SAS HDD ( RAID 10 - Storage )
2x HGST ZeusRAM 8G SSD (RAID 1 - ZIL/SLOG )
I just placed the order for the 2nd lot of drives after testing one of each with the HP Proliants to make sure they worked properly. They should be in later this week.
I’m having some trouble sourcing another Nytro SSD, but was wondering if the L2ARC on both hosts need to be identical drives or not.
Another thing is the necessity to mirror the ZIL/SLOG. After reading a few articles, the only way data loss would occur would be if the drive fails, and the server failed at the same time. However, I wasn’t sure how that applied to a configuration such as the one you described in your article.
But mirroring SLOG is handy in the event of SLOG failure. I just had a ZeusRAM fail in a bad way, and the performance impact for that customer’s workload was unfortunate. Some environments allow me to stripe multiple SLOG devices. It all depends on risk and application.
I have tons of SAS SSDs in various setups available. I’m assuming you’re using hardware RAID for the system/OS drives.
Another note that I will update documentation for is that you should have another network connection available in the event of a switch failure. I’ve been using a USB sync cable between nodes to provide an alternate path for the cluster ring.
L2ARC on hosts do not need to be identical. But ideally, you’d use the same drive location/name, or you may have to add some post-import scripting during failover.