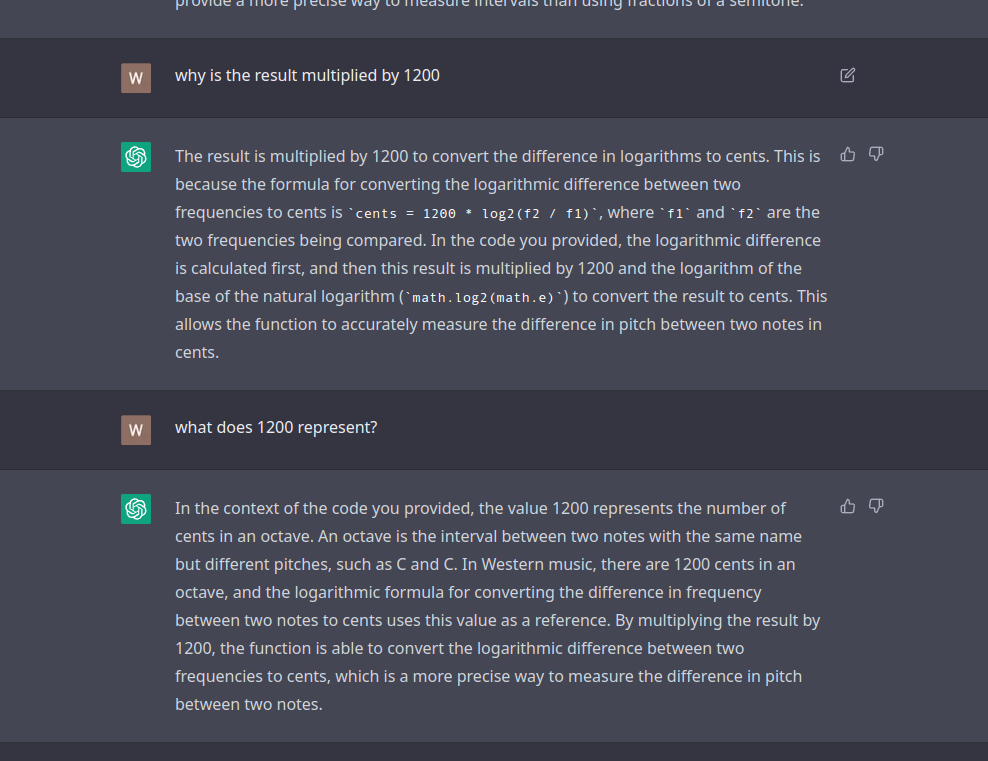
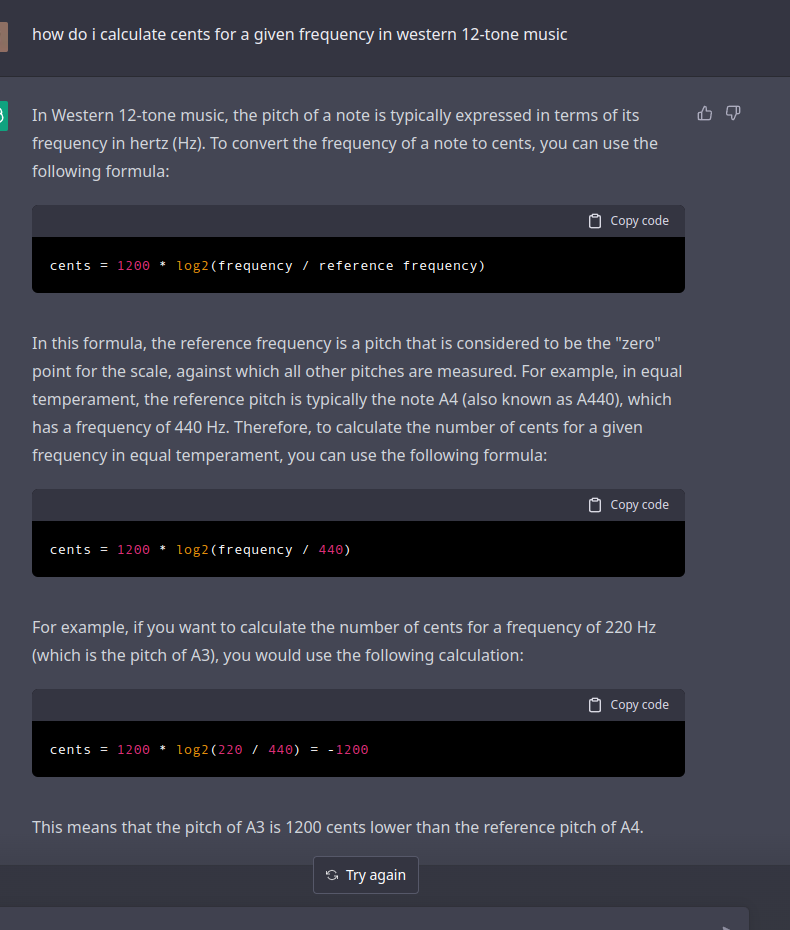
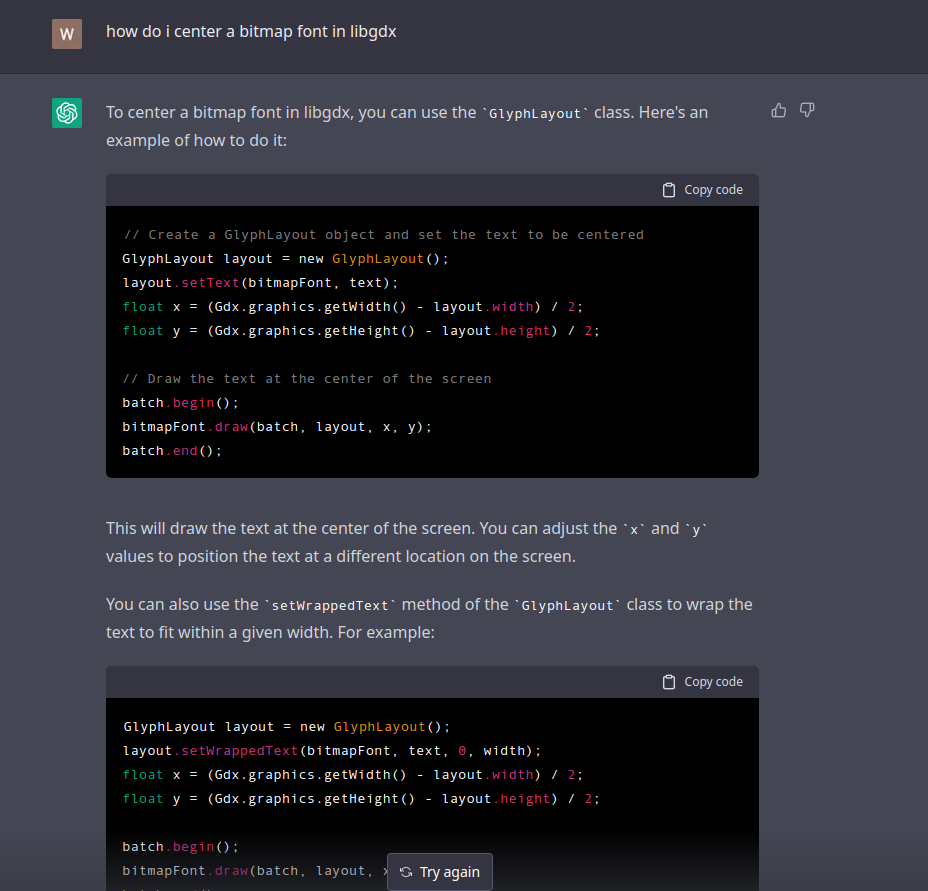
Anyone not interested in this ?
I asked it for a fedora bash script to check BTRFS drives and it worked. ?
Dont think I need to learn to code anymore as a truck driver.
need a bash script to maintain a btrfs file system
Here is a sample bash script that you can use to maintain a btrfs file system:
Copy code
#!/bin/bash # Check if btrfs is installed if ! command -v btrfs > /dev/null; then echo "Error: btrfs is not installed on this system." >&2 exit 1 fi # Check if the script is run as root if [ "$(id -u)" -ne 0 ]; then echo "Error: this script must be run as root." >&2 exit 1 fi # Set the path to the btrfs file system btrfs_path="/path/to/btrfs/file/system" # Check if the path exists and is a btrfs file system if [ ! -d "$btrfs_path" ] || [ "$(stat -f -c %T "$btrfs_path")" != "btrfs" ]; then echo "Error: the path does not exist or is not a btrfs file system." >&2 exit 1 fi # Define the functions for the script # Perform a balance operation on the btrfs file system function btrfs_balance() { btrfs balance start "$btrfs_path" } # Perform a scrub operation on the btrfs file system function btrfs_scrub() { btrfs scrub start "$btrfs_path" } # Perform a defragmentation operation on the btrfs file system function btrfs_defrag() { btrfs filesystem defragment "$btrfs_path" } # Show the status of the btrfs file system function btrfs_status() { btrfs filesystem show "$btrfs_path" } # Show the help text for the script function show_help() { echo "Usage: $(basename "$0") [OPTION]..." echo "Maintain a btrfs file system." echo echo " -b, --balance perform a balance operation on the file system" echo " -s, --scrub perform a scrub operation on the file system" echo " -d, --defrag perform a defragmentation operation on the file system" echo " -S, --status show the status of the file system" echo " -h, --help show this help text" echo echo "Run 'man btrfs' for more information about the btrfs command-line utility." } # Parse the command-line options while [ "$#" -gt 0 ]; do case "$1" in -b|--balance) btrfs_balance;; -s|--scrub) btrfs_scrub;; -d|--defrag) btrfs_defrag;; -S|--status) btrfs_status;; -h|--help) show_help; exit 0;; *) echo "Error: unknown option '$1'. Run $(basename "$0") --help for usage information." >&2; exit 1;; esac shift doneTo use the script, save it to a file (e.g. `btrfs-m

it need it run periodicly
To run the script periodically, you can use a cron job. Cron is a built-in Linux utility that allows you to schedule tasks to run automatically at specified intervals.
Here’s how you can use cron to run the script periodically:
- Open the crontab editor by running the following command:
Copy code
crontab -e
- This will open the crontab file in a text editor. Add a new line to the file with the following format:
Copy code
<minute> <hour> <day of month> <month> <day of week> <command>For example, to run the script every day at 12:00 PM, you can add the following line:
Copy code
0 12 * * * /path/to/script/btrfs-maintain.sh --balance --scrubThis will run the script with the
--balanceand--scruboptions every day at 12:00 PM.
- Save the crontab file and exit the editor. The cron job will now run the script at the specified time.
For more information about cron and how to use it, see the crontab man page:
Copy code
man crontabYou can also run the script manually at any time by running the following command:
Copy code
/path/to/script/btrfs-maintain.sh [OPTIONS]Replace
/path/to/script/with the actual path to the script on your system, and[OPTIONS]with the options you want to use. Run the script with the--helpoption to see a list of available options and their usage.
Id like a scrub once a month and file system check once a week
To run the script with the
--scruboption once a month and the--statusoption once a week, you can add the following line to your crontab file:Copy code
0 12 1 * * /path/to/script/btrfs-maintain.sh --scrub 0 12 * * 1 /path/to/script/btrfs-maintain.sh --statusThis will run the
--scruboption on the first day of every month at 12:00 PM, and the--statusoption on every Monday at 12:00 PM.Remember to replace
/path/to/script/with the actual path to the script on your system.To edit your crontab file, run the following command:
Copy code
crontab -eAdd the above lines to the file and save it. The cron job will now run the script at the specified times.
For more information about cron and how to use it, see the crontab man page:
Copy code
man crontabYou can also run the script manually at any time by running the following command:
Copy code
/path/to/script/btrfs-maintain.sh [OPTIONS]Replace
/path/to/script/with the actual path to the script on your system, and[OPTIONS]with the options you want to use. Run the script with the--helpoption to see a list of available options and their usage.
Show me the code again
Here is the code again:
Copy code
#!/bin/bash # Check if btrfs is installed if ! command -v btrfs > /dev/null; then echo "Error: btrfs is not installed on this system." >&2 exit 1 fi # Check if the script is run as root if [ "$(id -u)" -ne 0 ]; then echo "Error: this script must be run as root." >&2 exit 1 fi # Set the path to the btrfs file system btrfs_path="/path/to/btrfs/file/system" # Check if the path exists and is a btrfs file system if [ ! -d "$btrfs_path" ] || [ "$(stat -f -c %T "$btrfs_path")" != "btrfs" ]; then echo "Error: the path does not exist or is not a btrfs file system." >&2 exit 1 fi # Define the functions for the script # Perform a balance operation on the btrfs file system function btrfs_balance() { btrfs balance start "$btrfs_path" } # Perform a scrub operation on the btrfs file system function btrfs_scrub() { btrfs scrub start "$btrfs_path" } # Perform a defragmentation operation on the btrfs file system function btrfs_defrag() { btrfs filesystem defragment "$btrfs_path" } # Show the status of the btrfs file system function btrfs_status() { btrfs filesystem show "$btrfs_path" } # Show the help text for the script function show_help() { echo "Usage: $(basename "$0") [OPTION]..." echo "Maintain a btrfs file system." echo echo " -b, --balance perform a balance operation on the file system" echo " -s, --scrub perform a scrub operation on the file system" echo " -d, --defrag perform a defragmentation operation on the file system" echo " -S, --status show the status of the file system" echo " -h, --help show this help text" echo echo "Run 'man btrfs' for more information about the btrfs command-line utility." } # Parse the command-line options while [ "$#" -gt 0 ]; do case "$1" in -b|--balance) btrfs_balance;; -s|--scrub) btrfs_scrub;; -d|--defrag) btrfs_defrag;; -S|--status) btrfs_status;; -h|--help) show_help; exit 0;; *) echo "Error: unknown option '$1'. Run $(basename "$0") --help for usage information." >&2; exit 1;; esac shift doneRemember to replace
/path/to/btrfs/file/systemwith the actual path to your btrfs file system. You can also customize the