Has anyone tried running this with smaller models? Some 7B or 3B variants? Should require less VRAM.
New features in Open-Assistant let you set your model (references oasst-shared/oasst_shared/modle_configs.py) with env var MODEL_CONFIG_NAME. See Allow overriding of MODEL_CONFIG_NAME from environment (#2722) · LAION-AI/Open-Assistant@2ce2db6 · GitHub
If people are after an easy text infterface, you can use the following project with any sized model, it can even download the libararies and models for you.
4 Likes
Could also say 4bit models (q4) drops the memory substantially to about 4-6GB of VRAM, this makes gaming cards become more of an option.
The following user converts alot of models, can pick the right format with this:
GPTQ = GPU inference
GGML = CPU+GPU inference
1 Like
Linux Mint 21.1, fully patched. Fresh install.
Threadripper PRO 5970wx 128 GB RAM RTX 3090
Hit the wall and can’t seem to get past this block.
All of @wendell edits above have been made. Docker loads up using:
docker compose --privileged --profile frontend-dev --profile ci --profile inference up --build --attach-dependencies
Web interface opens and I select “custom” in settings. All good so far. When I type a query, it comes up with ‘your query has been queued’ prompt on the web page. The 12b model downloads and when done, I get the following errors in the terminal:
open-assistant-inference-worker-1 | 2023-06-10T18:46:00.261569Z ERROR batch{batch_size=1}:prefill:prefill{id=3 size=1}:prefill{id=3 size=1}: text_generation_client: router/client/src/lib.rs:29: Server error: CUDA error: CUBLAS_STATUS_NOT_INITIALIZED when calling
cublasCreate(handle)
open-assistant-inference-worker-1 | 2023-06-10T18:46:00.261622Z ERROR HTTP request{otel.name=GET /health http.client_ip= http.flavor=1.1 http.host=localhost:8300 http.method=GET http.route=/health http.scheme=HTTP http.target=/health http.user_agent=python-requests/2.31.0 otel.kind=server trace_id=1e98cc0ae907f01e59dcad8a4b2ef5a1}:health:generate{request=GenerateRequest { inputs: “liveness”, parameters: GenerateParameters { best_of: None, temperature: None, repetition_penalty: None, top_k: None, top_p: None, typical_p: None, do_sample: false, max_new_tokens: 1, return_full_text: None, stop: [], truncate: None, watermark: false, details: false, seed: None } }}:generate_stream{request=GenerateRequest { inputs: “liveness”, parameters: GenerateParameters { best_of: None, temperature: None, repetition_penalty: None, top_k: None, top_p: None, typical_p: None, do_sample: false, max_new_tokens: 1, return_full_text: None, stop: [], truncate: None, watermark: false, details: false, seed: None } }}:infer{batch_size=1}:send_error: text_generation_router::infer: router/src/infer.rs:382: Request failed during generation: Server error: CUDA error: CUBLAS_STATUS_NOT_INITIALIZED when calling
cublasCreate(handle)
open-assistant-inference-worker-1 | 2023-06-10 18:46:00.262 | WARNING | utils:wait_for_inference_server:120 - Inference server not ready. Retrying in 5.98 seconds
When I run ‘nvidia-smi’ when the Open Assistant is operating I see this:
±--------------------------------------------------------------------------------------+
| NVIDIA-SMI 530.41.03 Driver Version: 530.41.03 CUDA Version: 12.1 |
|-----------------------------------------±---------------------±---------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 3090 Off| 00000000:41:00.0 On | N/A |
| 0% 45C P8 36W / 420W| 382MiB / 24576MiB | 22% Default |
| | | N/A |
±----------------------------------------±---------------------±---------------------+
±--------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 1952 G /usr/lib/xorg/Xorg 236MiB |
| 0 N/A N/A 4381 G cinnamon 53MiB |
| 0 N/A N/A 5104 G …2658078,15485756801842386794,262144 89MiB |
±--------------------------------------------------------------------------------------+
The RTX 3090 is recognized, but ‘Off’ and not seen by docker even though all tests are fine and docker can list the GPU successfully.
My daemon.json is set up correctly according to the nvidia/cuda docs:
{
“runtimes”: {
“nvidia”: {
“path”: “nvidia-container-runtime”,
“runtimeArgs”: []
}
}
}
Spent five hours trying to get past this error with no improvement.
Any insights appreciated.
Run the docker contsiners that just runs Nvidia smi. Smells like docker docent have per.issions to open the cuda device
1 Like
Spent more time this weekend running through various options. Eventually removed docker and the nvidia drivers completely, then reinstalled. Got further, in that the GPU is fully accessible by docker and am a lot closer than I was, but I hit this block.
set up docker access to nvidia according to this doc:
[How to Properly Use the GPU within a Docker Container | by Jacob Solawetz | Towards Data Science](https://NVIDIA GPU Within Docker)
My outputs matched the article perfectly. Checking the terminal, I saw Inference-Server is not starting. Here is the section from my docker-compose.yaml:
inference-server:
build:
dockerfile: docker/inference/Dockerfile.server
context: .
target: dev
image: oasst-inference-server:dev
environment:
PORT: 8000
REDIS_HOST: inference-redis
POSTGRES_HOST: inference-db
POSTGRES_DB: oasst_inference
DEBUG_API_KEYS: “0000”
TRUSTED_CLIENT_KEYS: “6969”
ALLOW_DEBUG_AUTH: “True”
API_ROOT: “http://localhost:8000”
volumes:
- “./oasst-shared:/opt/inference/lib/oasst-shared”
- “./inference/server:/opt/inference/server”
restart: unless-stopped
ports:
- “8000:8000”
depends_on:
inference-redis:
condition: service_healthy
inference-db:
condition: service_healthy
profiles: [“inference”]
I also see these errors on the terminal:
open-assistant-inference-server-1 | 2023-06-12 00:04:31.465 | WARNING | oasst_inference_server.routes.configs:get_builtin_plugins:149 - Failed to fetch plugin config from http://localhost:8000/plugins/gale_pleaser: Plugin not found
open-assistant-inference-server-1 | 2023-06-12 00:04:31.470 | WARNING | oasst_inference_server.routes.configs:get_builtin_plugins:149 - Failed to fetch plugin config from http://localhost:8000/plugins/gale_roaster: Plugin not found
open-assistant-inference-server-1 | 2023-06-12 00:04:31.475 | WARNING | oasst_inference_server.routes.configs:get_builtin_plugins:149 - Failed to fetch plugin config from http://localhost:8000/plugins/web_retriever: Plugin not found
Tested each of the plugin URL and got “localhost refused to connect” prompts. (ufw firewall is inactive)
Suspecting a port conflict, I changed the port from 8000 to 8011 in the YAML. Now the pages render a little text when tested, but the plugins are still not seen or loaded by the system.
I believe that this is the last hurdle to getting it working.
Hey @wendell what version/commit of Open Assistant where you using? Since you’ve made this post they’ve added the model you referenced to oasst-shared/oasst_shared/model_configs.py so there isn’t a need for so many modifications but something is broken in the latest master because it’s trying to run on the CPU because of the bitsandbytes library not being compiled with GPU support. I saw the model go and use all my 64GB of RAM, and not even touching my VRAM before I stopped it. The versions I’ve tried are:
- the latest main at the time of writing
- v0.0.3-alpha33
- v0.0.3-apha32
- v0.0.2-alpha9 - which would kind of match the time of your post, but this had different issues
It feels a bit tedious to try all the versions until I find the one that’s working
I don’t even have this machine anymore, I need to try a fresh install.
Whats the error output? most of the time not auto-using cuda is somethings broken with the docker to cuda connection,. you can run the cuda “hello world” program or nvidia smi in docker to see what it does.
Yes, the nvidia-smi container works:
~ docker run --rm --gpus all nvidia/cuda:12.0.0-base-ubuntu20.04 nvidia-smi 125 ✘ at 10:34:30
Unable to find image 'nvidia/cuda:12.0.0-base-ubuntu20.04' locally
12.0.0-base-ubuntu20.04: Pulling from nvidia/cuda
ca1778b69356: Pull complete
b77b207a3766: Pull complete
fe39e032640f: Pull complete
349ba5086241: Pull complete
caeb32864e46: Pull complete
Digest: sha256:887fcddc4467e29e7b261807ba117a2697a7432b834f97db17255ded02f92723
Status: Downloaded newer image for nvidia/cuda:12.0.0-base-ubuntu20.04
Sat Jun 17 08:34:47 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.116.04 Driver Version: 525.116.04 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:05:00.0 Off | N/A |
| 0% 34C P8 20W / 320W | 550MiB / 10240MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
I’m on v0.0.3-alpha33 now on a Kubuntu 22.04.2 install. Because the model is already in the list and the docker-compose file now exposes the model variable I simply created a .env file with:
MODEL_CONFIG_NAME=OA_SFT_Pythia_12Bq_4
I’m using the quantized version since I have a RTX 3080 10GB so not enough VRAM to spare.
I run the containers with:
docker compose --profile frontend-dev --profile ci --profile inference up --build --attach-dependencies
After I give it a prompt this is the relevant section form the log:
open-assistant-inference-worker-1 | 2023-06-17T08:54:10.001735Z ERROR shard-manager: text_generation_launcher: "Error when initializing model
open-assistant-inference-worker-1 | Traceback (most recent call last):
open-assistant-inference-worker-1 | File \"/opt/miniconda/envs/text-generation/bin/text-generation-server\", line 8, in <module>
open-assistant-inference-worker-1 | sys.exit(app())
open-assistant-inference-worker-1 | File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/typer/main.py\", line 311, in __call__
open-assistant-inference-worker-1 | return get_command(self)(*args, **kwargs)
open-assistant-inference-worker-1 | File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/click/core.py\", line 1130, in __call__
open-assistant-inference-worker-1 | return self.main(*args, **kwargs)
open-assistant-inference-worker-1 | File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/typer/core.py\", line 778, in main
open-assistant-inference-worker-1 | return _main(
open-assistant-inference-worker-1 | File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/typer/core.py\", line 216, in _main
open-assistant-inference-worker-1 | rv = self.invoke(ctx)
open-assistant-inference-worker-1 | File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/click/core.py\", line 1657, in invoke
open-assistant-inference-worker-1 | return _process_result(sub_ctx.command.invoke(sub_ctx))
open-assistant-inference-worker-1 | File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/click/core.py\", line 1404, in invoke
open-assistant-inference-worker-1 | return ctx.invoke(self.callback, **ctx.params)
open-assistant-inference-worker-1 | File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/click/core.py\", line 760, in invoke
open-assistant-inference-worker-1 | return __callback(*args, **kwargs)
open-assistant-inference-worker-1 | File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/typer/main.py\", line 683, in wrapper
open-assistant-inference-worker-1 | return callback(**use_params) # type: ignore
open-assistant-inference-worker-1 | File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/text_generation_server/cli.py\", line 55, in serve
open-assistant-inference-worker-1 | server.serve(model_id, revision, sharded, quantize, uds_path)
open-assistant-inference-worker-1 | File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/text_generation_server/server.py\", line 130, in serve
open-assistant-inference-worker-1 | asyncio.run(serve_inner(model_id, revision, sharded, quantize))
open-assistant-inference-worker-1 | File \"/opt/miniconda/envs/text-generation/lib/python3.9/asyncio/runners.py\", line 44, in run
open-assistant-inference-worker-1 | return loop.run_until_complete(main)
open-assistant-inference-worker-1 | File \"/opt/miniconda/envs/text-generation/lib/python3.9/asyncio/base_events.py\", line 634, in run_until_complete
open-assistant-inference-worker-1 | self.run_forever()
open-assistant-inference-worker-1 | File \"/opt/miniconda/envs/text-generation/lib/python3.9/asyncio/base_events.py\", line 601, in run_forever
open-assistant-inference-worker-1 | self._run_once()
open-assistant-inference-worker-1 | File \"/opt/miniconda/envs/text-generation/lib/python3.9/asyncio/base_events.py\", line 1905, in _run_once
open-assistant-inference-worker-1 | handle._run()
open-assistant-inference-worker-1 | File \"/opt/miniconda/envs/text-generation/lib/python3.9/asyncio/events.py\", line 80, in _run
open-assistant-inference-worker-1 | self._context.run(self._callback, *self._args)
open-assistant-inference-worker-1 | > File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/text_generation_server/server.py\", line 99, in serve_inner
open-assistant-inference-worker-1 | model = get_model(model_id, revision, sharded, quantize)
open-assistant-inference-worker-1 | File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/text_generation_server/models/__init__.py\", line 64, in get_model
open-assistant-inference-worker-1 | return CausalLM(model_id, revision, quantize=quantize)
open-assistant-inference-worker-1 | File \"/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/text_generation_server/models/causal_lm.py\", line 283, in __init__
open-assistant-inference-worker-1 | raise ValueError(\"quantization is not available on CPU\")
open-assistant-inference-worker-1 | ValueError: quantization is not available on CPU
open-assistant-inference-worker-1 | " rank=0
open-assistant-inference-worker-1 | 2023-06-17T08:54:10.705742Z ERROR text_generation_launcher: Shard 0 failed to start:
open-assistant-inference-worker-1 | /opt/miniconda/envs/text-generation/lib/python3.9/site-packages/bitsandbytes/cextension.py:127: UserWarning: The installed version of bitsandbytes was compiled without GPU support. 8-bit optimizers and GPU quantization are unavailable.
open-assistant-inference-worker-1 | warn("The installed version of bitsandbytes was compiled without GPU support. "
open-assistant-inference-worker-1 | Traceback (most recent call last):
open-assistant-inference-worker-1 |
open-assistant-inference-worker-1 | File "/opt/miniconda/envs/text-generation/bin/text-generation-server", line 8, in <module>
open-assistant-inference-worker-1 | sys.exit(app())
open-assistant-inference-worker-1 |
open-assistant-inference-worker-1 | File "/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/text_generation_server/cli.py", line 55, in serve
open-assistant-inference-worker-1 | server.serve(model_id, revision, sharded, quantize, uds_path)
open-assistant-inference-worker-1 |
open-assistant-inference-worker-1 | File "/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/text_generation_server/server.py", line 130, in serve
open-assistant-inference-worker-1 | asyncio.run(serve_inner(model_id, revision, sharded, quantize))
open-assistant-inference-worker-1 |
open-assistant-inference-worker-1 | File "/opt/miniconda/envs/text-generation/lib/python3.9/asyncio/runners.py", line 44, in run
open-assistant-inference-worker-1 | return loop.run_until_complete(main)
open-assistant-inference-worker-1 |
open-assistant-inference-worker-1 | File "/opt/miniconda/envs/text-generation/lib/python3.9/asyncio/base_events.py", line 647, in run_until_complete
open-assistant-inference-worker-1 | return future.result()
open-assistant-inference-worker-1 |
open-assistant-inference-worker-1 | File "/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/text_generation_server/server.py", line 99, in serve_inner
open-assistant-inference-worker-1 | model = get_model(model_id, revision, sharded, quantize)
open-assistant-inference-worker-1 |
open-assistant-inference-worker-1 | File "/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/text_generation_server/models/__init__.py", line 64, in get_model
open-assistant-inference-worker-1 | return CausalLM(model_id, revision, quantize=quantize)
open-assistant-inference-worker-1 |
open-assistant-inference-worker-1 | File "/opt/miniconda/envs/text-generation/lib/python3.9/site-packages/text_generation_server/models/causal_lm.py", line 283, in __init__
open-assistant-inference-worker-1 | raise ValueError("quantization is not available on CPU")
open-assistant-inference-worker-1 |
open-assistant-inference-worker-1 | ValueError: quantization is not available on CPU
open-assistant-inference-worker-1 |
open-assistant-inference-worker-1 |
open-assistant-inference-worker-1 | 2023-06-17T08:54:10.705766Z INFO text_generation_launcher: Shutting down shards
open-assistant-inference-worker-1 exited with code 1
As far as I read it it’s running on the CPU because bitsandbytes wasn’t compiled with GPU support.
I’m interested in how models are benchmarked. Which are practical and which are scientific?
I noticed the hugging face page for Pythia 12B has their own demo comparing 2 models. But, each prompt is configured with different model parameters. Like: temperature, top_p, tok_k, etc. Isn’t this a bias and almost cherry picking for good generated responses? Those parameters are manually tuned (I believe), but there are presets.
This is Open Assistant’s own implementation and data comparing prompts + responses between models Comparer
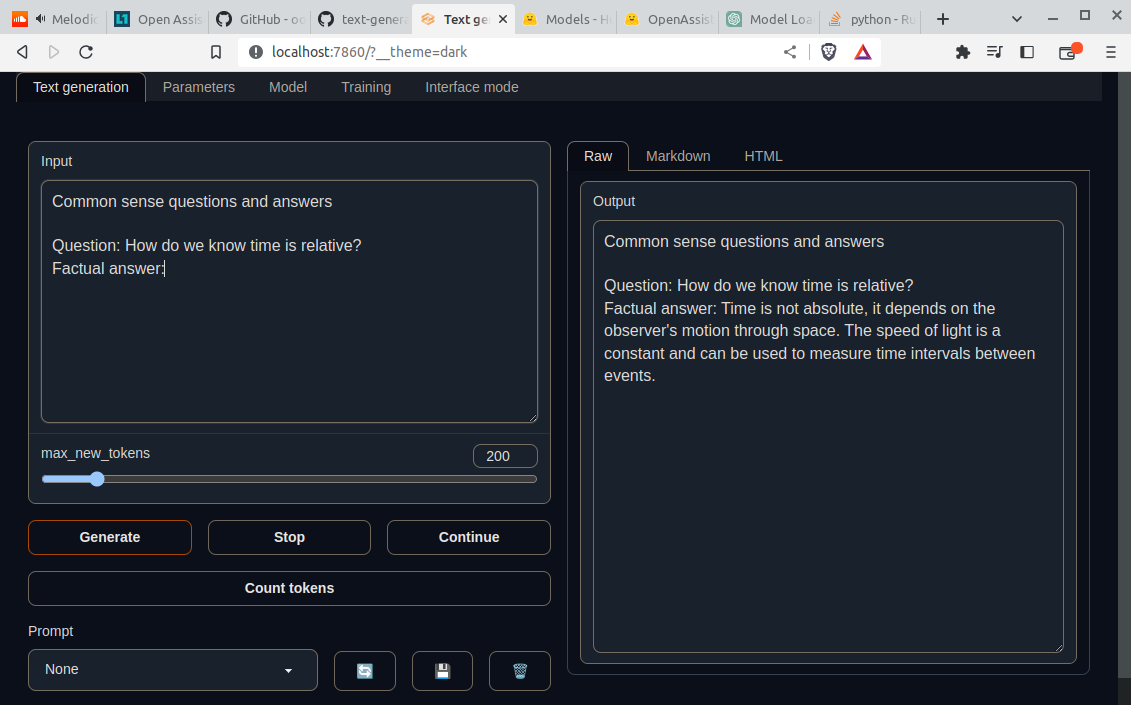
I finally abandoned the open-assistant as I was chasing error after error. After three weeks of tweaking, I ended up back at the first error I got.
Instead I followed @Iron_Bound recommendation and had oobabooga up and running within an hour. By no means perfect and needs a lot of tweaking. Decent performance and the accuracy is dead on so far, but I’ve only played with it for a limited time.
Had to modify the boot sequence to limit vRAM use and avoid vRAM exhaustion:
conda activate textgen
python server.py --auto-devices --gpu-memory 20
(The 20 is amount of vRAM to dedicate in GiB - I have a 24GB 3090)
Thanks to @Wendell for his advice. I feel it was a Linux Mint incompatibility that borked the open-assistant try, but can’t say that definitively.