UPDATE: My conclusions were wrong, this was evidently not caused by the power supply itself, see follow-up message.
Original post below:
This is more of a report on some initial findings I’ve had with a bit of a perplexing issue I’ve been experiencing, and may be of some value to other people.
I have a fairly old system - a first gen Threadripper 1950x in a Zenith Extreme motherboard, and have been running it in a VFIO configuration for quite some time, with one GPU for a Linux VM and a second GPU for a Windows VM. While there were some problems initially, the system has generally been fairly robust.
Lately I’ve been planning a major system change, and with the release of the RTX 4090 in October I decided to buy one as the first major upgrade, even though it’s severely bottlenecked until I upgrade the rest of my system.
Things seemed to be fine, initially. Then I made some changes to the system, including replacing the power supply, updating the BIOS, playing with some new USB controllers etc. At the same time I’ve been doing further experimentation with PCIe bifurcation and an M.2 eGPU (ADT-Link), so there’s quite a few variables at play here.
Afterwards I started noticing some odd behavior.
-
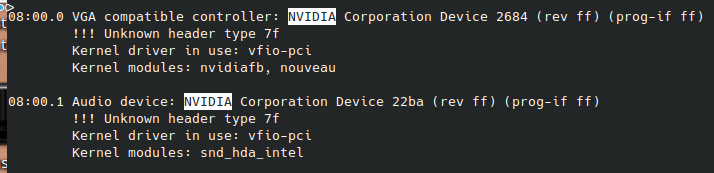
I could no longer reboot my Windows 10 VM without encountering what appeared to be a reset bug. The whole GPU (RTX 4090) would essentially ‘fall off’ the bus, no longer correctly report in lspci (don’t recall the error code, I’ll take a screencap once the opportunity arises again). Forcing the VM to shut off and attempting to boot it again would yield “Unknown PCI header type ‘127’”, only a full host reboot would bring it back up again. My other GPU, a Quadro M2000 on my Linux VM, continued to function fine. This card (RTX 4090) is on the bottom slot of the board due to its ridiculous size, as I’m using ~every other slot in the system I can’t obstruct them. This limits the card to a maximum of x8 PCIe 3.0, unfortunately.
-
Increased count of PCIe link errors, all corrected, but only on one PCIe link. This was occurring on the link to my eGPU that I was messing around with, so I figured I just had some connection issue or I was abusing the max signaling length far too much. (It’s a ridiculous setup - I have a M.2 extender + the eGPU’s M.2 cable, the full length is quite long, so this didn’t seem to be a major shock to me.) This link also came from the primary PCIe x16 slot, which I had bifurcated with a Hyper M.2 card (lol).
-
Yesterday (and it’s been weeks since I started encountering these issues, but just haven’t had time to deal with them due to working very long hours) I decided to try and address some of these issues.
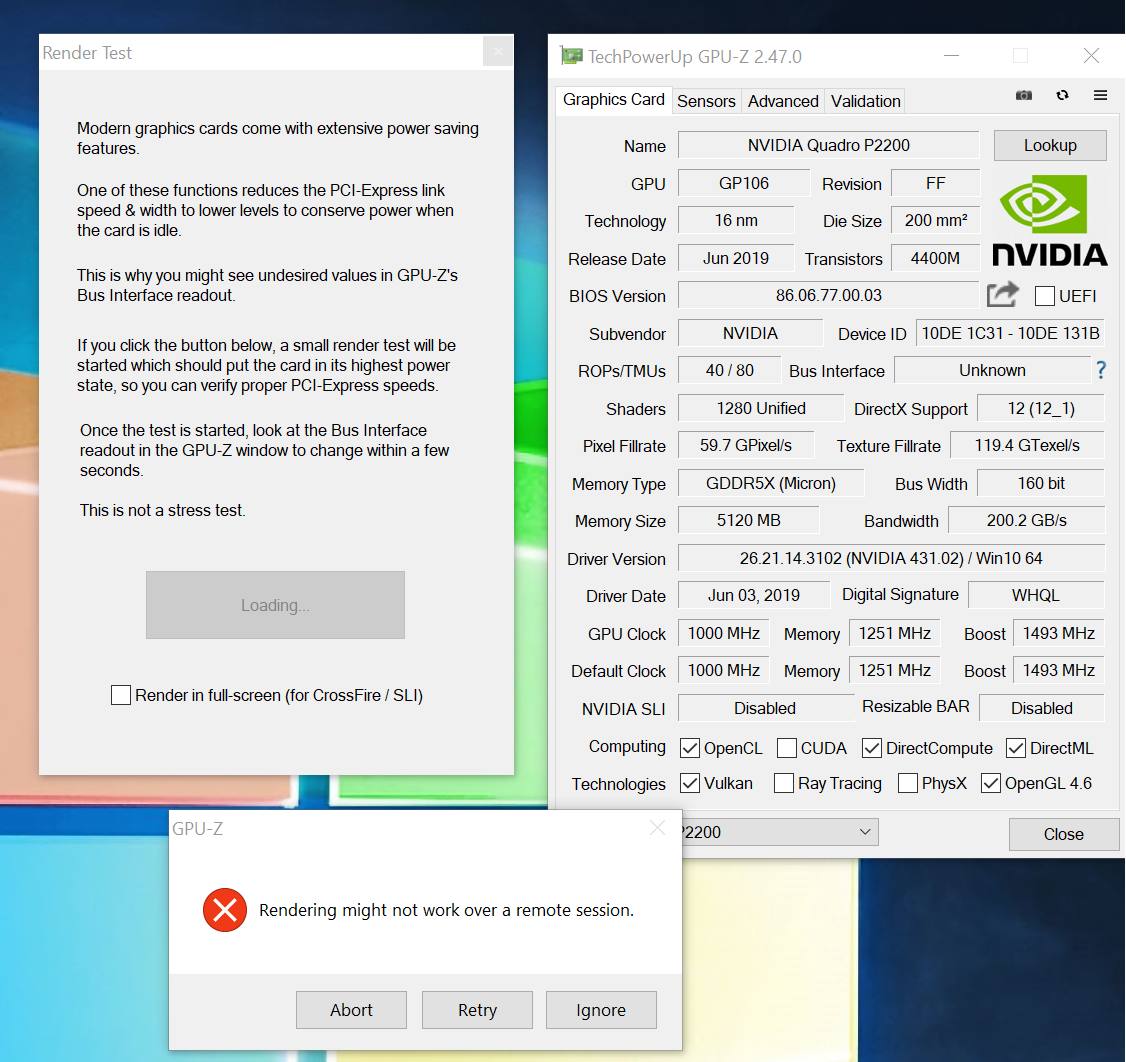
I took a look at lspci on the RTX 4090 again. This time I noticed it’s only negotiated to PCIe x4. I rebooted into the BIOS, and there, too, it only listed as PCIe x4. This slot can be configured to operate in x4, and I figured it may be some issue with the BIOS not respecting my preference for x8 (and thus disabling the U.2 port), so I decided to revert to an older BIOS. No dice, same problem. Clearing BIOS settings didn’t help, either.
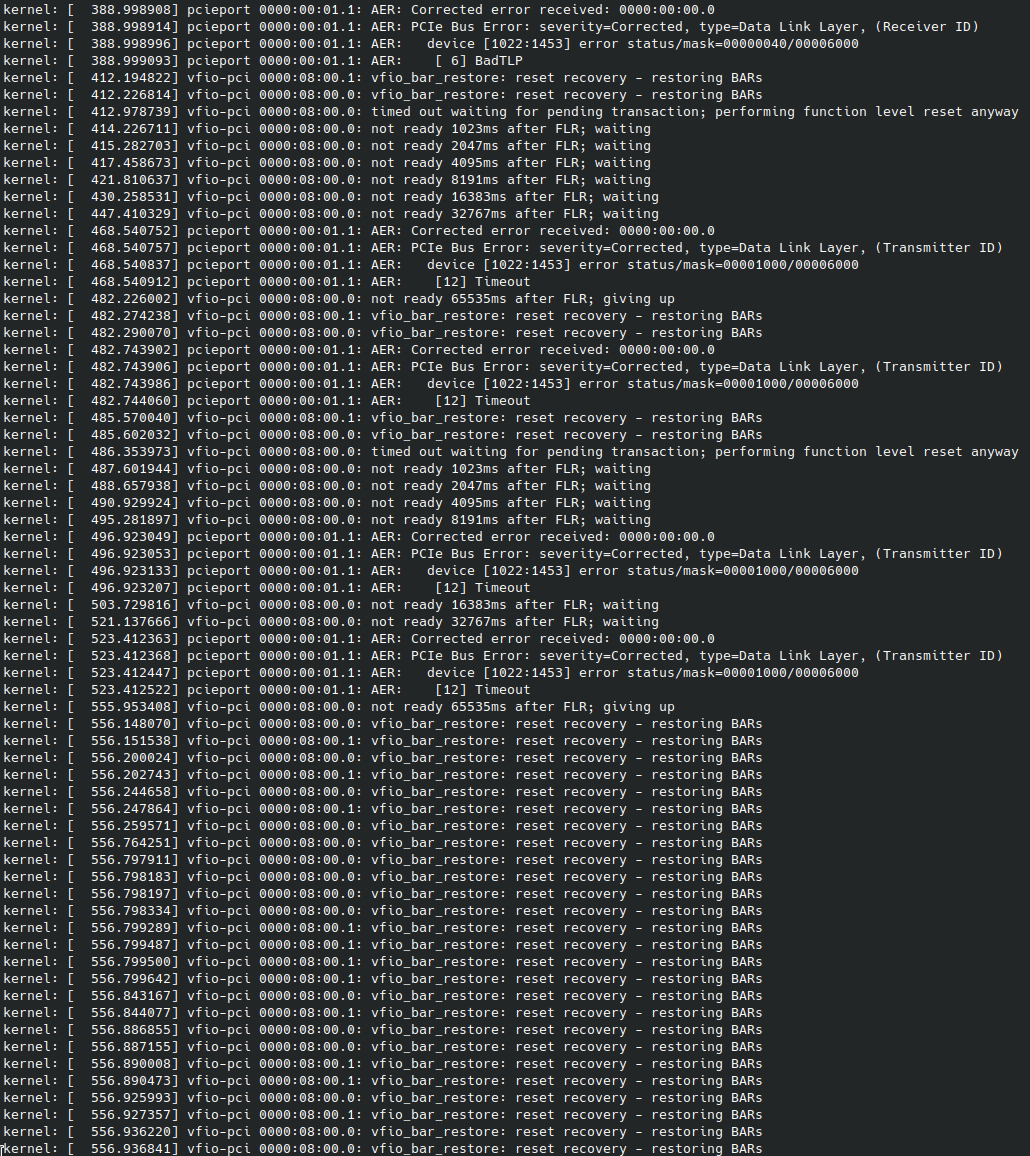
The apparent culprit.
As I’m sure many of you know, when the RTX 4090 came out there were a lot of concerns about the 12VHPWR cable. I was concerned as well, but my bigger concern was that I couldn’t close the side panel on my case without pressing down on the cable quite a bit, so I had the system running with the side panel off. Additionally, I’ve been running a Rosewill Hercules 1600W power supply for about 8 years now. It’s quite old and there’s presumably zero chance I could get a better 12VHPWR cable for it. I found out that Seasonic was shipping free 12VHPWR cables for those who owned Seasonic units, and I found a Seasonic GX-1300 unit on Newegg for a very decent price and decided to order one.
Eventually I got the power supply and the 12VHPWR cable and I was able to replace the old Rosewill Hercules, and although it didn’t seem clear at the time (because of the many other changes I’ve made to my system), it seems like this is when my problems began.
Last night I ad-hoc connected my old 1600W unit to my system, 12VHPWR adapter and all. The system appears to be completely stable. I’m not getting any link errors on the eGPU despite the ridiculous cable length, the RTX 4090 is linking at x8 width, and the GPU reset problem has vanished.
I haven’t yet tried swapping back to the Seasonic GX-1300 to ensure this is 100% the cause, but I’m fairly certain it is.
Has anyone here experienced anything like this before?
TL;DR:
Switching from a Rosewill Hercules 1600W power supply to a Seasonic GX-1300 appears to be resonsible for a GPU failing to negotiate full link width, PCIe errors on an external GPU, and GPU reset failure when rebooting a VM.
UPDATE:
All of my conclusions were wrong, see follow up message.
Conclusion: (I’ll update this as I go)
If the graphics card is not properly seated, the card may no longer correctly reset when the VM is rebooted, even though it otherwise appears to work correctly. This is additionally different from a card that is properly seated, but explicitly set to operate at a reduced link width.
Example:
Scenario 1: Slot configured to x8 in BIOS, card improperly seated running at x4, fails to reset on VM reboot.
Scenario 2: Slot configured to x4 in BIOS, card properly seated running at x4, succeeds in reset on VM reboot.
Now I have more questions…