Im still sorting the networking stuff out… since all the device names are different… but shouldnt be too much longer…
pics coming later…
Im still sorting the networking stuff out… since all the device names are different… but shouldnt be too much longer…
pics coming later…
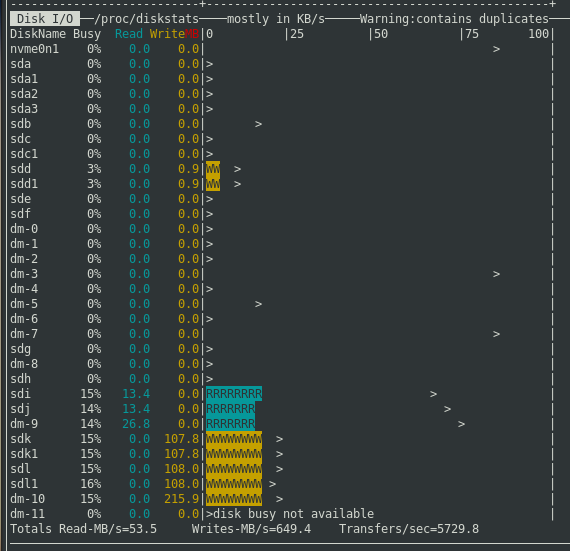
so I removed the cache device from my zfs pool
(after reviewing the arc summary output… even with noprefetch=0… my l2arc hit% was under 1%)
changed from 4Gb HBA to 8Gb HBA…

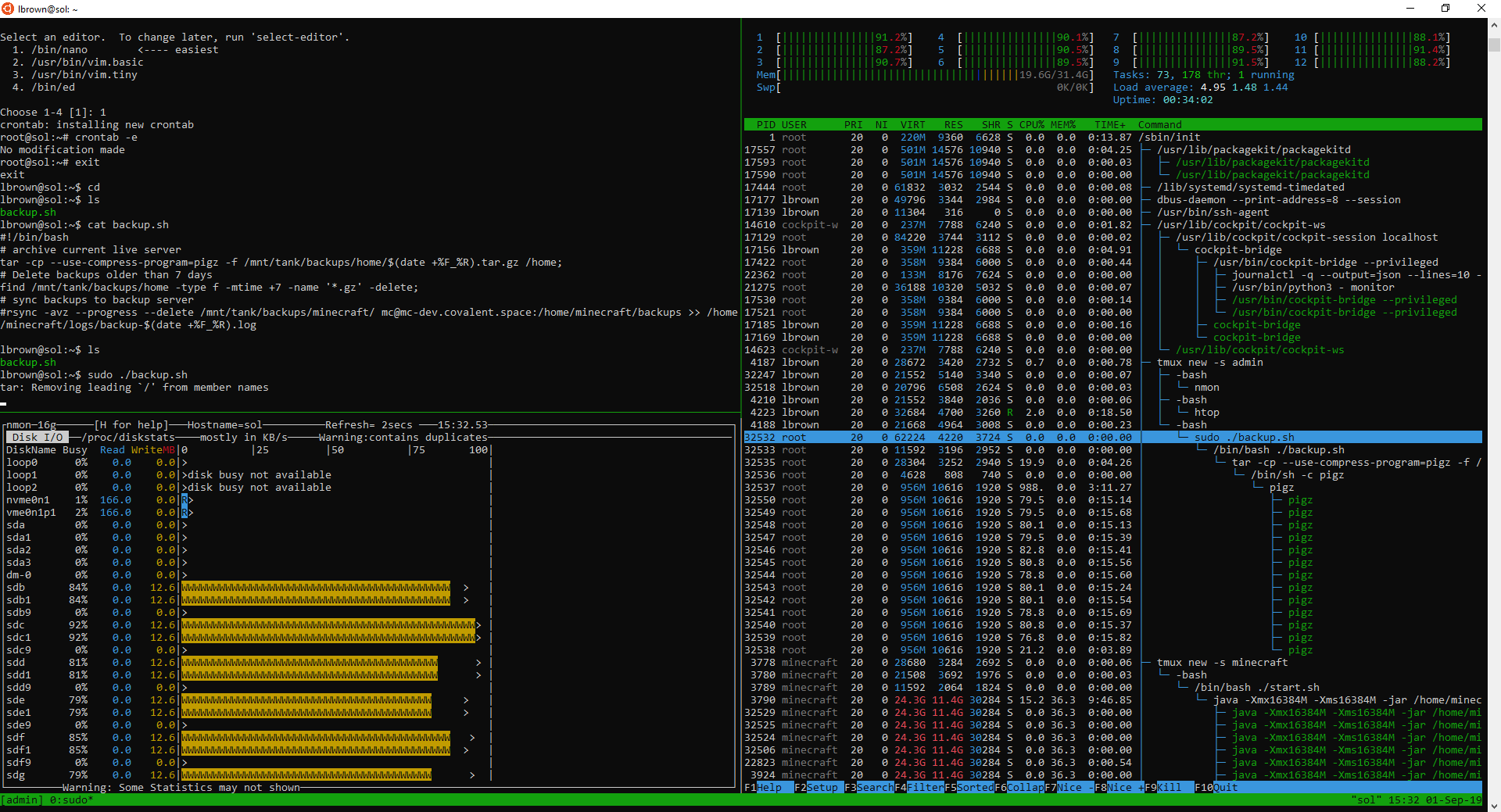
That’s a really neat way to watch the backup take place. What are you using?
.
nmon
Do you use pigz to help accelerate your backups?
For example:
#!/bin/bash
# backup /home to zfs pool located at /mnt/tank
tar -cp --use-compress-program=pigz -f /mnt/tank/backups/home/$(date +%F_%R).tar.gz /home;
Makes backups crazy fast because it will use all threads available to run the backup.
CC’ing @oO.o because you might dig this.
Never heard of that before but I’ll check it out… Was just a simple tar backup
Oh it will change your life 
sudo apt install -y pigz
This is what the backups script looks like.
All cores active.
I’ve used pigz before. Very fast. Unfortunate that uncompressing can’t be parallel.
Got a handful of 3ft cables to tidy up the rack. Removed all the slightly too long ones.
right now I have a powerline adapter to get from one side of the house to the other… but i dont like the speed being limited to 150Mbps.
In the future I plan to come up with something to get the network thru the house without the poor performance.
Working on moving stuff around on one of my zfs pools so I can reconfigure one of the pools as two 4drive raidz1’s.
Hoping to not over fill the second pool too bad so I can reconfigure.
It’s easy to diy your own parallel compression/decompression utility, it’s a good exercise to learn a programming language
I thought parallel uncompress wasn’t possible.
Lets say you have 8 threads, and have 8 input buffers of 1MB each, and 8 output buffers of e.g. 1MB each, and some code that reads .tar from input into these buffers, and some code that copies output of these buffers … To decompress in parallel read not in 1MB chunks, but in whatever size compressed data was outputted …
I’m sure it’s not as smart or efficient as pigz … but if you want to use 128 cores to decompress data into your nvme it works
This is what I was thinking of:
The problem when decompressing is the arrangement of the decompressed data.
Reading the input is fine because it can iterate in predictable chunks. When decompression it could vary wildly.
The only way I can think about how to get around this would be to store additional meta data of what the output should be like but I’m not sure how much this would increase the payload.