I am looking for some help/advice to troubleshoot a stability issue I am having with a Samsung 960 Pro SSD on Ubuntu 18.04.
Machine Specs
i7 8700K
Gigabyte Z370m-DS3H
16GB RAM
Samsung 960 Pro 512GB
Issue description
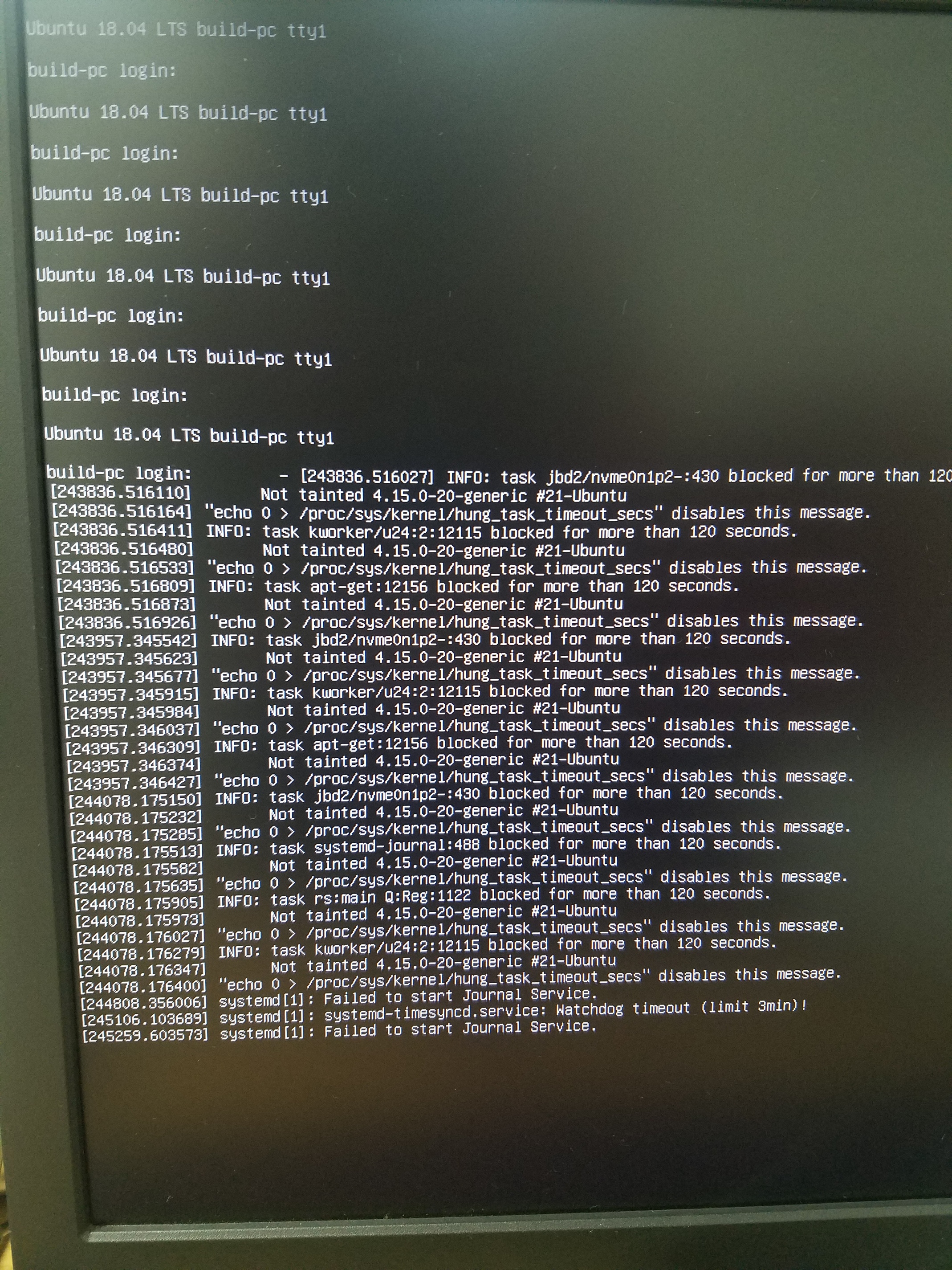
Ubuntu 18.04 64 bit server OS “hangs” with the following errors in dmesg
INFO: task jbd2/nvmeon1p2-432 blocked for more than 120 seconds (see image attached)
Check for firmware updates for the SSD. Some of the 800 series Samsung SSDs were known to not play nicely with ACPI and TRIM on GNU/Linux. That was mostly fixed with firmware updates by Samsung. I don’t know if the 900 series has/had the same issue.
How would one check and update the firmware on a drive in Linux?
Edit: I was guessing you could view and update firmware revisions through hdparm, and found the following after a brief search. Does it look about right?
It was specifically for Seagate HDD’s, but I’m presuming it could be adapted?
I am doing some stability tests at the moment with Ubuntu 18.04 server on a VM (Windows host). So, don’t have the problem environment to capture the partition table at the moment.
Await my findings from the VM experiment…
coming from the aur world, im not sold on using ubuntu server. I have been trying to use it for about a month. documentation is lacking. I would also check the #ubuntu irc to solve your answer.
I had this exact issue with a drive that had not been trimming correctly. Doing a secure erase (the drive got EXTREMELY hot) and letting it sit overnight, everything was just peachy.
I think the situation was that at some point I had used something on it that wasnt trimming properly. And now I was, but the current software assumes that the previous software already issued a trim command and that any trim now for something not explicitly written, then deleted, needs a trim.
In other words only the parts of the drive you have erased have been trimmed, not all the space from all of the past history of the device. So the OS may be assuming the “already empty” space when it started was in a proper ready-for-writing trimemd state.
Remember, samsungs are the firmwares that are ntfs/fat32 aware to try to mitigate some of this when the internal drive’s trim table gets out of sync with the os for whatever reason.
You can try issuing a command to trim ALL deleted space and see if that helps, otherwise use mfg utility to reformat and condition the drive.
I also experienced something similar, but not to this extent, on a surface pro device which was ultimately returned to MS due to defective ssd. Samsung nvme in that case.
Wendell’s answer made the most sense. It best matches my observations. But I haven’t solved my problem yet. @wendell what tool did you use to secure erase the drive? and what is the reason to leave the device overnight?
I tried secure erasing with Samsung’s Magician software and using parted magic (and also Diskpark clean all). That made no difference to the stability. But I didn’t leave the machine idling overnight.
Few other updates/clues:
Windows continues to be stable; I can run Ubuntu inside a VM on Windows without any issues
I used my 960 Pro SSD on a friend’s Ryzen 1700/X370 system and Ubuntu was stable. So it has something to do with my MB/SSD combo.
I reached out to Gigabyte support and they advised to enable CSM and set the storage boot option control to Legacy. Gigabyte support sent screen shots of them installing Ubuntu on a samsung NVMe drive (960 EVO 1TB) without any issues. However it didn’t make any difference to me.
Antergos was unstable as ubuntu; didn’t try Vanila Arch yet
Did you take a look at the Arch Wiki link that Zerophase provided. If you have not then I would recommend it. Your installation may have tried to be smart, or conservative on some options that could be causing issues. Like the scheduler and what not. If you do not see anything in dmesg or jounalctl then you either have some defective hardware or you are missing some important configuration somewhere.
To iron out issues with NVME on the RVE, with a SATAIII drive also installed, I had to enable “all drives” in the boot options. Previously, I just had “boot drives” only. But, that had only caused issues with machine check exceptions when booting into Windows. Might have caused problems with Linux too, but I didn’t check the logs. It’s worth a shot.
I would also go ahead and disable power saving features in the kernel, just to rule that out. And make sure discards aren’t being issued.
Which tests are you running in UnixBench? I could always check if I get errors too under the stock and ck kernel. Using “none” for the disk scheduler.
@Zerophase and @Mastic_Warrior: thanks for the advise.
it’s been a couple of frustrating days playing around with Arc. The problem still exists and here are a few updates:
I can get the Arch based system to either get stuck or get a kernel panic related to timeouts/watchdogs as soon as I do something that is disk I/O intensive. Like building a package or enable a swap file deamon
Disabling Autonomous Power State Transition didn’t make a difference
So, secure erase and possible firmware update? I see the same (failed to unmount /old_root and hang).
There was a brickage with the late 2017 firmware, but I see whispers that this has been fixed as of Jan 2018. Anyone know otherwise or have reason for caution against firmware update? (caution given the very bad result of the Q4 2017 update).