Hallo everyone, i have returned with a recently “completed” truenas server that is probably very overkill for it’s uses (for now). Hardware is as follows:
Epyc 7371 16C 32T
128GB of ECC RAM, cant remember brand/model offhand
Intel XXV710 25gb/s dual port NIC (direct connected to my desktop over fiber)
SuperMicro H11-SSL-I mobo 2x of these cards to connect all my U.2s
8x WD Ultrastar SN640 6.4TB setup in 1 pool, 4 mirror pair VDEVs
a spinning disk pool thats kind of shameful for 18.03TiB size (lots of mismatched disks from ones i had laying around)
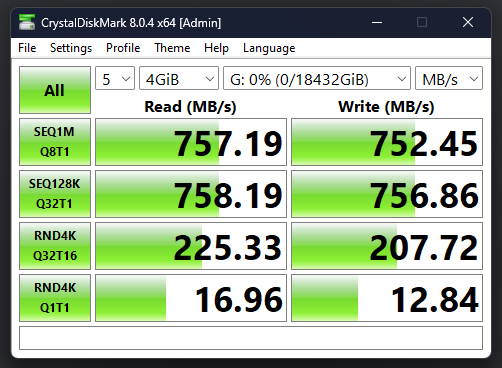
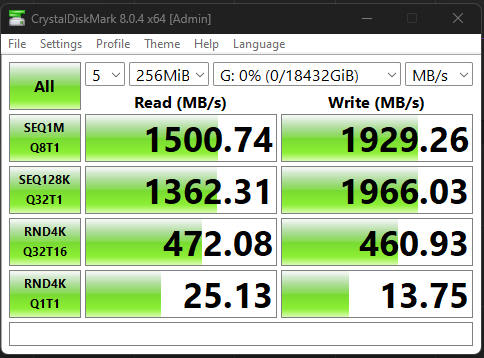
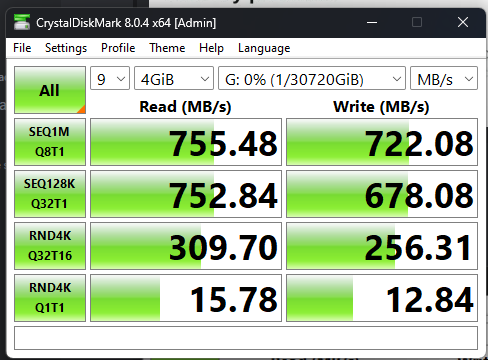
when accessing the NVME pool over ISCSI, across the 25gb/s fiber i get some speeds on the random reads/writes that are alot lower then a local SATA SSD. given the spec sheet of the WD drives i expected alot more. this uncovered something weird in the reporting after i went digging. but first, the numbers mason!
This is on a 18TB Zvol i made just to test this out, not permanent. the random 4K Q1T1s are the really confusing part. though frankly i dunno the difference in the test between the bottom two rows. The sequentials not being even higher isnt surprising, the NIC on my desktop’s side is slotted into an electrically X2 slot to avoid air starving my GPU.
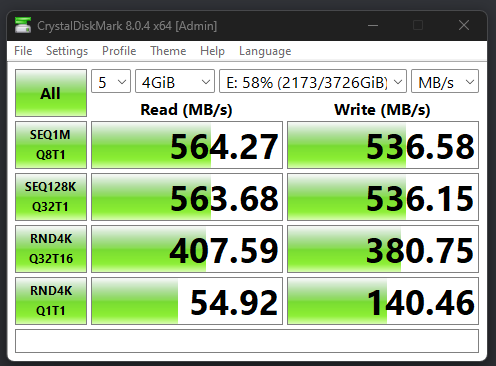
A Local Sata SDD did markedly better than this on random IO, but got outran on sequentials as expected.
latency on the link appears to have been low during this, disk reporting showed roughly “.5” latency for read, “.1-.19” write (it doesnt seem to show units for this, i assume seconds.
this is disk busy above, this could just be a momentary issue in reporting. a re-run of the test did not reproduce this, though the disk did report 150% busy time on run 2?
anyways the NVME pool is acting weird, not sure if i dun goofed on the config or something else. pool is not using dedupe, compression is LZ4, atime is off, block size is 128K. iscsi block is from a thin provisioned Zvol. if anyone has pointers to check on i would appreciate input.
Someone had nearly the exact same numbers as far as sequential bandwidth to his remote array. He eventually diagnosed his issue as his NIC in his client being in a pcie3x1 slot. He moved it to a faster slot and got full 10gbe speeds.
Random access 4K Q1T1 represent a worst case performance scenario, that you’re unlikely to encounter in real life. Database workloads can come close to this access pattern.
Why are you concerned with this metric? What workload do you expect to run on your NAS and what performance do you observe as you try to simulate that?
When you’re testing try to test like-for-like.
E.g. What is the performance of your zpool when testing locally, or rather, what performance can you observe against your SATA disk over the network?
The raw storage hw (NVMe’s on EPYC) is capable of 10x the performance that you’re receiving (less when accounting for the various hw/sw layers of your setup).
You could probably save a lot of $$$ if you’re willing to settle on performance lower than 10gb networking.
Your setup feels like you purchased a Porsche, but run it on donuts.
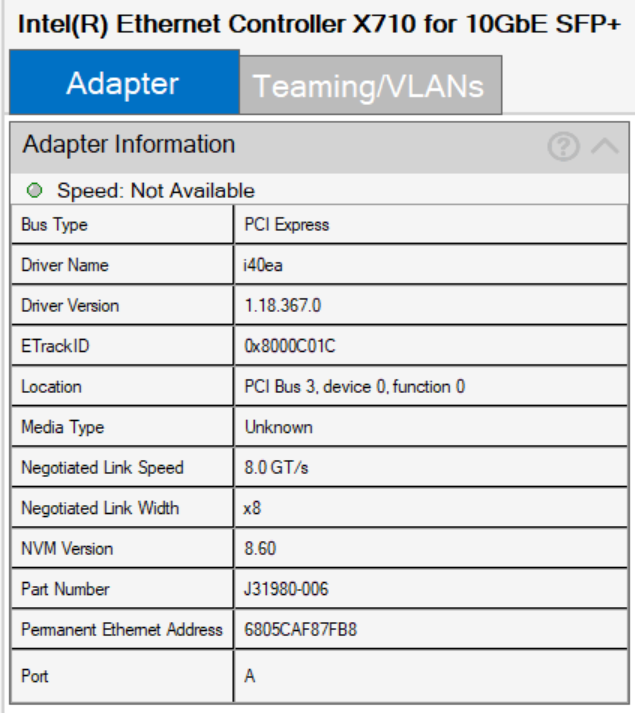
My problem was very similar to yours and it was the NIC’s lack of available PCIe bandwidth. I would make sure that your NIC is plugged into a PCIe 3.0 x8 slot or higher. You can verify the Negotiated Link Speed and Negotiated Link Width using Intel’s PROset Adapter Configuration Utility.
Well, the server as-is kinda skipped from step 1 to 10 at the end. Frankly i’m not sure how to simulate this though this page seems to have some useful info, despite the fact that compression will boggle the test of writing many zeros.
The spinning disk pool is good enough for it current primary use, being archival for myself and family in the house. after some config it will also host a dataset for archival/offsite storage over OpenVPN or similar for trusted close friends.
the NVME pool is intended to end up as a target for 2x VMWare hosts (I7-10700s with fiber cards and a healthy amount of RAM), and as an ISCSI target to mount drives to gaming PCs around the house so people can offload their whole (or partial, up to them) steam libraries onto it in lieu of a bunch of local disks. the idea here is to be at least as fast as a local sata ssd to at least two machines simultaneously, but the network backend for a bunch of fiber aint there yet. plan is to use one 25gbps interface for the hosts, the other for the windows targets.
i cant lie, that made me laugh a bit, because it cant be a more apt comparison for how i use my automobile…
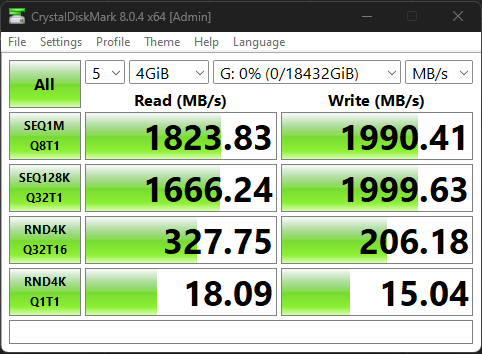
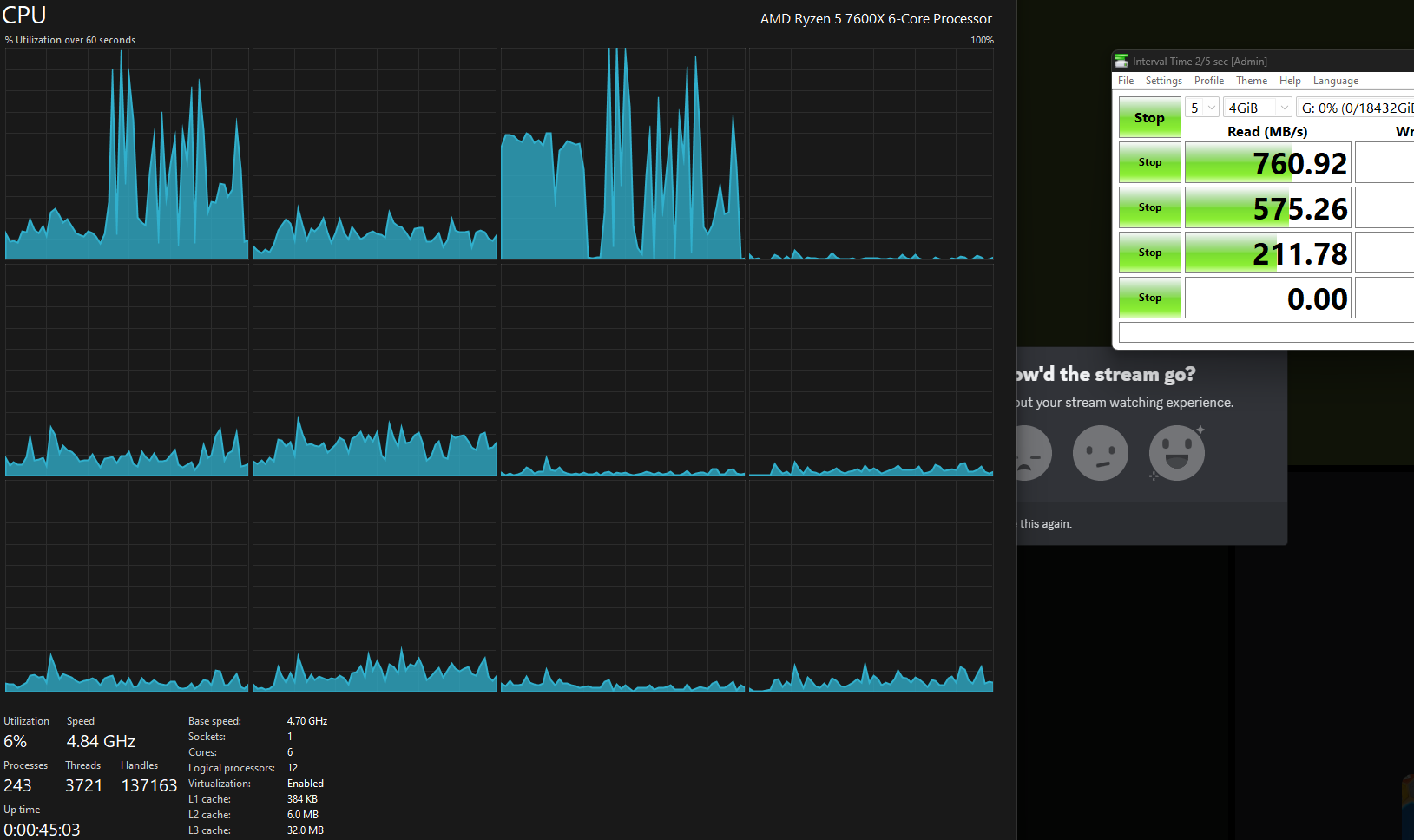
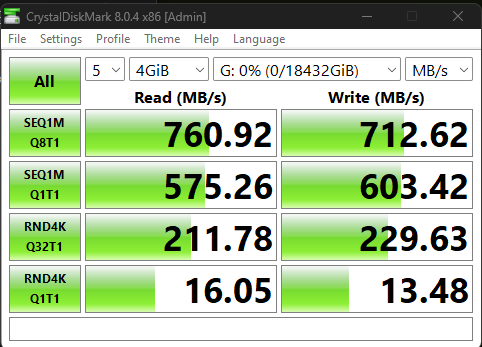
I swapped my GPU on my rig out and dropped in the XXV710 then re-ran the tests, the numbers are much faster. but the random IO still feels slower than what i’d expect from 4 mirror pairs of U.2s, now that i’m ignoring the Q1T1.
not sure what the local disks themselves on the nas should be capable of outputting yet, dunno how to test that and compare to the net results. further research is required.
Measuruing directly at the storage can rule out many problems. iperf3 is your established CLI tool for testing network throughput.
Other than that…fio is basically the industry standard for measuring file system and drive performance.
Depending on your zvol properties, can be entirely normal. iSCSI random I/O over Ethernet just can’t compete with native and local disks. My homelab wont ever go >15k IOPS on my zvols. It scales really nicely over multiple clients, but single application with a single client on low blocksize stuff just isn’t the Disneyland of storage.
Looks more like a network thing to me + maybe overly high iSCSI/zvol expectations.
Those 750MB/1500MB very fishy looking sequential numbers are wierd…doesn’t look “normal”
I was able to confirm after some looking that the MTU of the interfaces on both sides is 1500, there are no hops inbetween the NAS and windows client. fiber goes straight from the nas to my desktop (for now)
weird in that they are too low for the hardware behind them? i’m aware the SSDs should be capable of many many times this perf, i’m just not yet sure how to examine local pool perf and compare it to these tests. i’m also not aware of the most accurate settings for queue depth and thread count for a typical “go find this texture from this games directory because we’re loading x map” use case either. one could say i jumped off the deep end a bit too early for my own good.
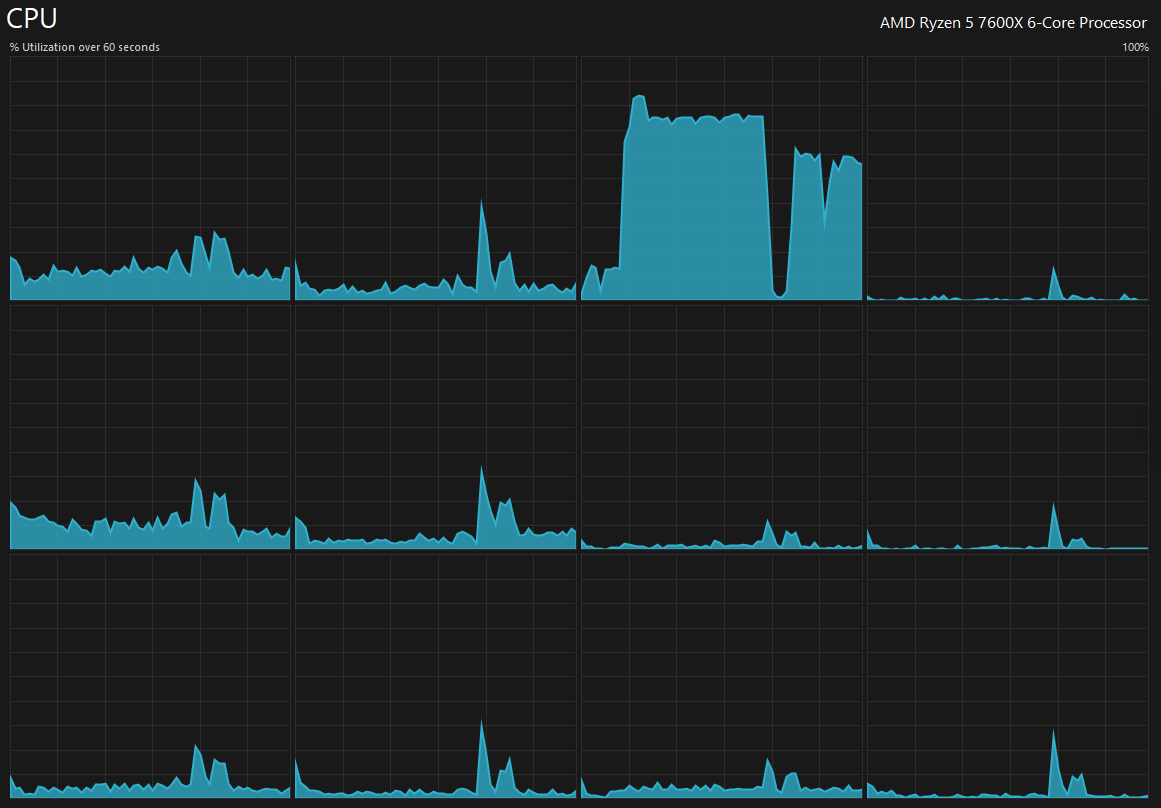
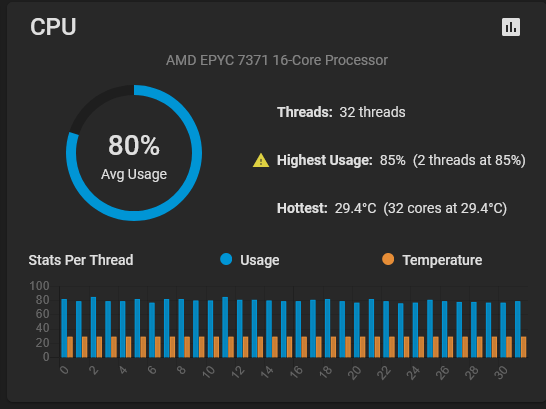
i checked on CPU use age on my desktop client during these transfers (R5 7600X on a watercooler, no OC) and while there is a very significant rise in specific threads, there is still headroom.
CPU usage on the nas itself seems to be negligible at best.
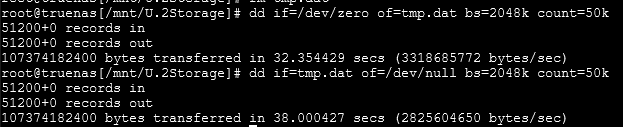
I did turn off compression and after some googling, i changed sync on the zvol to standard instead of always. didnt really seem to do much. (these numbers are with the X8 XXV710 in a PCIE X4 slot, so i’m aware it’s not ideal, but i think my board doesnt have anymore lanes to give, i will confirm this tonight.
I combined all the disks into one big stripe just for testing throughput, with the client card slotted poorly, destroyed the zvol and turned off thin provisioning, got 30% more random read speed over the initial tests, and 25% random writes. just changing the pool layout with the same zvol settings made no effective change.
worthy of note is that the Q32T16 random writes were sending the cpu to 80+ % util.
i will use a seperate machine to run full speed tests on a fresh W11 install. more info coming tomorrow.
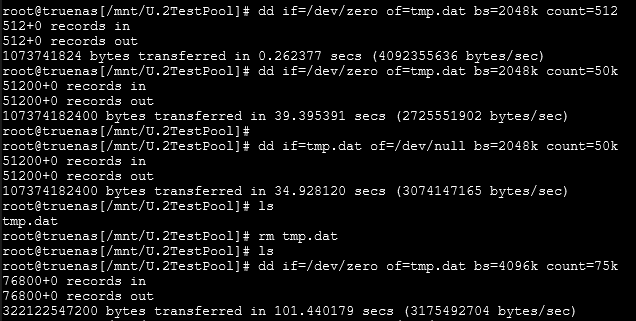
local storage benchmarks, these sequential tests were with all the drive in a single beeg stripe.
This is the drive back in 4 mirror pairs
all this was completed with compression off so it didnt fudge with anything.
it’s been a minute since i had time to circle back to this. after changing the value of target to the U.2 pool and SIZE to 8144, i tried running this and it spat out a massive heap of errors. Almost all of them complaining about operand locations, and another that the IOEngine libaio could not be found. i’ll have to figure out what i need to tinker with to make this script work.
i suspect the other operand errors are due to the same or simmilar reason this one occurs at the top of the script.
the whole script completed instantly so i can only assume nothing ran due to the operand errors.
The top of the script reads #!/bin/bash it’s a bash script so you need to run it with bash not with zsh! In case you put the contents of the script in a file say script.sh you should be able to run it in zsh by specifying which interpreter to use so the following should run without errors: