Would be my question as well. Looking Glass client on the host operating system with the display attached to it and a Windows VM with access to a MIG device with the Looking Glass Server installed and then see the performance to have both accelerated GPU on the host and guest from the same card.
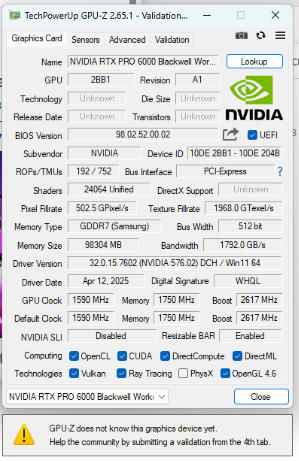
It has the same limitations that the other pro series cards nvidia has put out like the Ada, if you want to partition the card you need vgpu license.
However they did fix the MSI bug that required a registry hack to get the ada card working through vfio. So you can vfio pass through the entire card into the vm without any registry hackery which is nice that they cleaned that up for this generation. So a bit of progress for us plebs who don’t want to pay for vgpu.
Even using the RTX 6000 for display output on the host and acceleration in a guest at the same time, are you sure? It read to me like you need to pass through the entire card, but you can pass through a vGPU, or a partition or however you wanna call it, to the VM while having display output on the host?
Theres two ways to do it, the free way which is to have two video cards. One video card uses the vfio driver and the entire card is passed into the vm while the other video card is used for the actual display. Then you have two ways to view the vm, some sort of remote desktop or something like looking glass which does dma transfers between the two cards for ultra low latency.
The other way is a single card approach which allows you to use both the host and vm on the same card and pass in a vgpu into the virtual machine. This costs money for licensing fees
The former setup is what I have right now, that I know of well.
Okay so I get that as long as you pay for a vGPU license you can use the RTX PRO 6000 series for both host and guest at the same time. This actually sounds good. I’ve found this document, do I understand correctly that one perpetual workstation licence costs $450? Given the cost of the card and the amount of VM’s I need I think that is bad but not too bad.
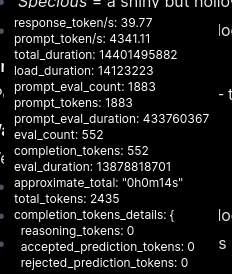
680billion param model running at 45 tokens a second
./build/bin/llama-cli --model /mnt/models/llama/DeepSeek-R1-0528-UD-IQ1_S-00001-of-00004.gguf --n-gpu-layers 62 --temp 0.6 -c 163840 --prompt '<|User|>What is the value of pi accurate to the 1,000 decimal? You must give all 1,000 values. Feel free to use scripts, calculators, or other resources to accurately calculate the number. Show your work calculating and verify the number for accuracy.\n<|Assistant|>' -no-cnv -fa -sys 'This assistant is DeepSeek-R1, created by DeepSeek.\nToday is Sunday, June 1st, 2025.'
llama_perf_sampler_print: sampling time = 214.13 ms / 6351 runs ( 0.03 ms per token, 29659.55 tokens per second)
llama_perf_context_print: load time = 19414.90 ms
llama_perf_context_print: prompt eval time = 516.14 ms / 55 tokens ( 9.38 ms per token, 106.56 tokens per second)
llama_perf_context_print: eval time = 138112.28 ms / 6295 runs ( 21.94 ms per token, 45.58 tokens per second)
llama_perf_context_print: total time = 139185.50 ms / 6350 tokens