Not really a “build log” per se, but I am now running Ceph over 100 Gbps Infiniband.
Set up the 3-node Proxmox cluster about 4 hours ago. That took a little bit because the Proxmox 8.2 installer wouldn’t boot up with my 3090 installed in my 5950X system, so I had to swap it out with a GTX 660 instead, to get the install going. (5950X doesn’t have an iGPU, hence the need for a dGPU.)
The 7950X is a Supermicro AS-3015I-A “server”, which also uses the Supermicro H13SAE-MF motherboard, so it has built-in IPMI, so no dGPU was needed for that.
Two nodes are 5950Xes, one 7950X.
They all have 128 GB of RAM (DDR4, DDR4, DDR5 respectively) and Silicon Power US70 1 TB NVMe 4.0 x4 SSD for the 5950X systems, and an Intel 670p 2 TB NVMe 3.0 x4 SSD in the 7950X.
All of them have a Mellanox ConnectX-4 dual port VPI 100 Gbps Infiniband NIC in them (MCX456A-ECAT), connected to a Mellanox 36-port externally managed Infiniband switch (MSB-7890). My main Proxmox server is running the OpenSM subnet manager that ships with Debian.
Got that clustered up over IB.
And then installed Ceph Quincy 17.2 and got the erasure-coded pools up and running.
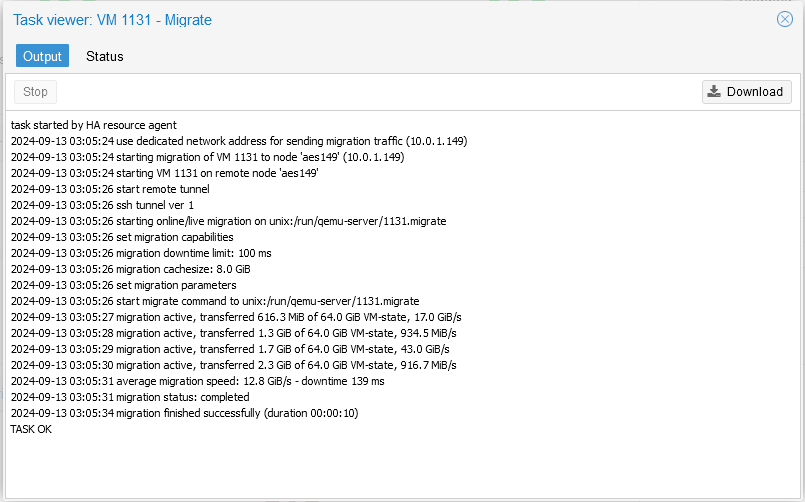
I can live-migrate a Win11 VM (with 16 GB of RAM provisioned to it) in 21 seconds after learning how to make it use a specific network for the live migration.
edit
I can live-migrate an Ubuntu 24.04 VM (which also has 64 GB of RAM provisioned to it) in 10 seconds at an average migration speed of 12.8 GiB/s (102.4 Gbps)
That’s not really that impressive. I used to run proxmox with 2x 1gbps ports in LACP and it took about the same time. The secret was that I was using NFS on a NAS (well, a couple of NAS’es to balance all my VMs storages) and qcow2 for the disk (not that the latter really matters).
All that proxmox does if your storage is shared among the hypervisors is to move the RAM contents.
I’m not saying your setup isn’t impressive in itself, that’s very cool. Ceph in particular is nice, since you don’t need a dedicated box as a NAS or SAN. My setup, if the NAS the VMs ran on went down, I wouldn’t be able to start the VMs. There was replication available, but never used it (we didn’t need that kind of uptime anyway, at least not at the cost of double the storage).
Ok, that’s the transfer speed of the RAM state from one machine to the next.
I’m more interested what speed you get from inside the VM reading data of the ceph storage.
I assume the VM’s have their drives/filesystems store as rbd images in ceph.
Well, you still have the single infiniband switch, unless you have two and use them in HA mode, but still, how many Watt/Hr are you drawing for the whole cluster (nodes+network)?
edit/disclaimer
I am a n00b to Ceph. Absolutely, 100%, most definitely a n00b.
As such, I am, BY FAR, NOT an expert on it.
So, this is my near idiot’s way of doing things.
There will ALWAYS be people who know and understand this stuff way more and way better than I will ever understand all of the various elements at play here.
This is me following my deployment notes from earlier this year, where/when I deploy Ceph for the first time on a trio of cheap $150 Mini PCs that uses one of the slowest 12th Gen Alder Lake CPUs I can find (because it was cheap).
I have no intention on using this system/setup for long (due to other reasons that are related to how Debian interacts (or doesn’t interact) with IB.
Also, I surmise that there are probably people here where you might be dealing with faster system interconnects, especially at where you might work.
Keep in mind that I am running this in the basement of my house.
This is not at my work. This isn’t what I do professionally.
This is only for fun/shits and giggles.
I think that the switch, IIRC, idled at somewhere like 20-30 W. I forget.
And then the nodes, now without a (d)GPU – maybe about the same, also at idle.
I should be able to get firm numbers tonight thought, but it might take a few tries to get the numbers as I would have to plug and unplug stuff into my Kill-A-Watt meter.
But I can get that, not a problem.
(It’s probably not going to be as high as you might think because it isn’t super taxing to the CPU(s).)
Thank you.
So far, the absolute peak that I have been able to hit on numerous occasions is 16.7 GiB/s (133.6 Gbps).
If the source of the migration comes from the 7950X, then it is faster.
If the source of the migration comes from the 5950X, then it peaks out at around 11.1 GiB/s (88.8 Gbps) which means that for high speed transfers, the 7950X generational uplift can be as high as 33.5% using the same Mellanox ConnectX-4 PCIe 3.0 x16 NICs.
(5950X supports PCIe 4.0 whilst 7950X supports PCIe 5.0, but none of that matters because the NIC doesn’t support the newer PCIe generations.)
See the first edit.
The original, slower speed was because by default, Proxmox uses the same interface to perform said live migrations as the interface that you are using to manage the system. (So, typically, over GbE.) After testing it for a little while, I was trying to figure out why it wasn’t using the IB network at all for the live migrations, and found the answer here where I can tell it the network that I want it to use instead of the default network.
From there, it pushed the live migration traffic off of the GbE and onto the 100 Gbps IB, and that’s when I started hitting 100+ Gbps during said live migrations.
Agreed. But without a fast(er) network, that can still be the slowest part of the live migration process, even if it doesn’t have to “copy” the VM disk over the network (because it’s already sitting on shared network storage that all of the nodes in the Proxmox cluster can “talk” to).
So, the ironic thing about this was that I actually first deployed Ceph at home, on my three OASLOA Mini PCs which only has an Intel N95 Processor in it, and a M.2 2242 512 GB NVMe SSD with no other ports/internal option to expand storage. And that cluster is used for my Windows AD DC, DNS, and AdGuard Home, so I wanted the storage to be “self-contained” to the cluster, as to avoid the issue where if the storage was connected to a NAS (or SAN), and said NAS/SAN goes own, then it would take those services down along with it.
So, I didn’t actually originally PLAN on deploying (and learning about) Ceph. But since I did that, when I set out to run these tests, I had my deployment notes already from that, so I was able to just follow my deployment notes to get this whole thing up and running in ~2 hours (with the slowest part being that I had to swap my GTX 660s around on the 5950X nodes because it doesn’t have an iGPU and the motherboard (Asus) doesn’t have IPMI (that can also control the power).
Ceph on my N95 Mini PC cluster isn’t super fast. (It also ran over GbE.)
This just took that to an entirely different level.
Yes, the VM disks are written to RBDs.
That tended to vary quite a bit. Neither Windows Task Manager nor iostat running in Ubuntu appear to be accurately reporting the Ceph speeds over IB.
Having said that though, on the Proxmox host itself (I haven’t exactly figured out which method/mechanism I am going to use, to pass Ceph into the VMs (i.e. virtiofs? or create a disk and then pass the disk into the VM. Not really sure yet.) – I was testing the CephFS read and write speeds with time -p dd if=/dev/<<thing>> of=<<output file>> bs=1024k count=<<number>>
where <<thing>> was either zero, urandom, or random, and the output file was either 10Gfile or 50Gfile, and the count is proportional to the desired size of the test file.
b) Only two of the NVMe 4.0 x4 SSDs are matching, the third is a NVMe 3.0 x4 SSD.
c) I have done absolutely ZERO tuning of Ceph (PGs, sizes, etc.) In fact, as of right now, I don’t know if Ceph is even IB aware. (i.e. uses ib verbs for data transfers)
Haven’t tried. Haven’t looked into that yet.
This was just a VERY quick test.
So, there’s definitely more testing that can be performed with this (and a LOT more tuning as well, which I typically don’t bother with because I’ve found that if you have a mixed use case, tuning it may help with one, but then hurt a different use case. So I tend to leave it, “as-is”. (with the defaults).)
(And you can spend a LOT of time, tuning the crap outta this thing. A LOT of time. Between IB tuning and Ceph tuning – a LOT of time.)
I can probably start pulling together tonight.
I don’t think that it’s going to be as much as people might think, mostly because the modern systems are quite power efficient and the data transfers don’t really tax the CPUs that much.
It depends on how much you write to them, I suppose.
I’m just using consumer grade drives for these tests. And luckily, because the VM disks sit on the shared Ceph RBD storage, so no further copying of said VM disks is required, therefore; as far as write endurance efficiency is concerned, this is actually pretty good as I am just moving the RAM state over.
So far, the observed results is that it looks like that I don’t necessarily need to explicitly define nor enable RDMA. The speeds are fast enough, and it also looks like that it is handling the 4x25 Gbps links that’s in EDR IB (rather than it only using one of those 4 links for the data transfer as was the case when I tried to set up a Linux Network Bridge (Ethernet bridge, where I set one of the ports with LINK_TYPE=ETH) on the two 5950X nodes, and over said ethernet vmbr, running iperf with 8 parallel streams, I could only barely muster 23 Gbps.
By the way, if any of the people who have commented here have any experience about how you have tuned Ceph to run on 100 Gbps IB, please educate me in terms of what you did (and how).
What I was saying was that, the network traffic was on 2x gigabit NICs in LACP and the NAS VLAN was on another 2x gigabit NICs in LACP. Not even 10G and the live migration was still fast. I only wanted to point out that you’re only migrating the RAM, which doesn’t really need a lot to be moved (unless you have a hypervisor with 2048GB of RAM and your VMs are all in the hundreds of GB of RAM, then you’d have to wait a couple minutes on gigabit, compared to 100G in a few seconds).
I haven’t delved into ceph on pve, but I’m pretty sure it functions like with others. The Ceph RDB presents a block storage device and qemu virtualizes it with virtio and presents it to the VM as a virtual disk. You can see that in your windows VM in task manager, if you look at the disk (it should say QEMU disk I think).
And you can blame me if while plugging unplugging something breaks and I will reply telling you about the philosophical advantages of testing stuff in the field.
Just to give you food for thought for the next rabbit hole: here in the EU/UK we can buy a smart plug that can also measure power draw for about 17USD after tax, and you can choose between Tasmota (mqtt) and esphome as open source firmware installed … they work pretty well and cost very little. I use them in my homelab to monitor and plot energy draw of the various components
I would be surprised if the IB switch only draws 30W … the ones I see that are 40GB from Oracle draw 110W at idle
It’s basically a pre-configured deployment by the proxmox devs that integrates nicely into the Proxmox UI and all. There are some limitations, like only having RBD and no CephFS or RGW. Hypervisor only uses block storage, so that’s fine, but you can just administrate ceph via CLI and get the ceph dashboard and other missing stuff…it’s just diverging from the proxmox standard install.
Ceph likes to sync a lot. That’s why drives with PLP perform vastly better. 100 IOPS vs 1000-1500 IOPS per OSD, that’s huge. I certainly can’t get more than 100-120 out of my consumer drives, but everyone says you need PLP and I checked this with a fellow forum member here. Replicated pool + enterprise drives are the way to go for IOPS
5-15% less than advertised max speed is totally normal. And 100Gbps is still 4x25Gbit “lanes”, so 23 seems reasonable depending on your LAGG settings and/or test method
Ceph doesn’t benefit from RDMA and most people seem to skip all RDMA for Ceph…too much of a hassle for not really a difference.
So, let’s assume that you are able to achieve perfect scalability with 2x GbE that are bonded together, given you a 2 GbE effective.
Let’s also assume that the time it takes is roughly halved by using said bonded connection, so if it took me 21 seconds to move 16 GB of RAM contents around, then it would take you about 10 seconds to move the same.
That’d still only work out to be 1.6 Gbps.
60 seconds / 10 seconds = 6 * 16 GB of RAM = 96 GB of RAM. Therefore; if your VM has more than 96 GB of RAM provisioned to it, then it will take you approximately a minute to perform the same migration.
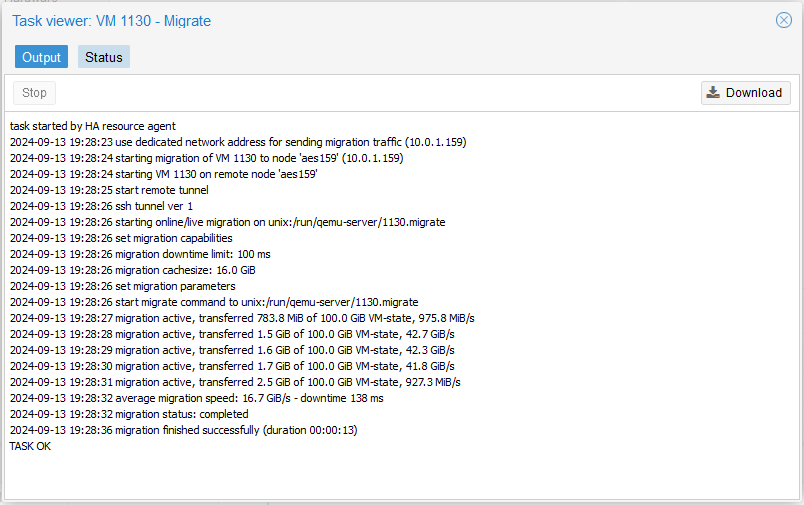
I was testing with a VM with 100 GB of RAM earlier this morning, and that took between 11-12 seconds to live-migrate.
So, to your point – would you rather spend roughly a minute, migrating your VM that has 100 GB of RAM provisioned to it, or would you rather spend roughly 11-12 seconds doing the same task?
I agree with you that it’s migrating just the RAM/VM state. But pushing 100 GB even over a 2 GbE connection AT the theoretical peak of 2 Gbps transfer/line speed, is still at least a 50 second endeavour.
For the record, the VMs were only set up with a 100 GB disk as well, therefore; even if I were to move the VM disk, the time that it would take, provided that the rest of the stack can handle it, would still max out at about those speeds.
If you can complete the task faster, why wouldn’t you?
Furthermore, to your point (about it moving the stuff in RAM, which I agree with), you’d think that having LESS RAM should take LESS time to live migrate, but that proved NOT necessarily to be the case because a VM with 16 GB of RAM provisioned to it live migrated in roughly the same 9-10 seconds as it did to live-migrate the same VM with 64 GB of RAM provisioned to it.
According to the theory of operation, if the interface is 100 Gbps, then I should have been able to live-migrate a VM with 16 GB of RAM, roughly four TIMES faster than what it took to live-migrate the same VM with 64 GB of RAM (4x more RAM, should’ve taken 4x longer).
But that’s not the case.
I’ll have to take a look when I get home tonight.
I think that I set up the VMs where the VM disk actually uses the VirtIO block device “driver”/“method” rather than SATA.
But on the other hand, I also created a CephFS on the same OSDs, so I COULD use virtiofs and “mount” that in Windows. (I am trying to avoid using anything that needs to go through the virtio NIC because that’s capped at 10 Gbps.)
I dunno. I’ll probably play around with it on my Ubuntu VM because I can use dd to write dummy files (faster than for me to find a similar tool, to do the same thing, in Windows).
I think that it should be alright, so long as I am careful with it.
So, I took a quick look at those, and I think that the problem that I am going to run into is that the size of those plugs makes it so that I can’t put very many on a surge protector/power bar that only has 6 outlets that are relatively spaced closely together.
I’m not super concerned about power draw (I mean I am, but for some stuff, I think that I’ve hit the lower limit already). My main Proxmox server (with 36 HDDs, dual Xeon E5-2697A v4s, 256 GB of RAM) uses somewhere between 600-800 W nominally (and my server load average is about 20). I’ve tried looking for lower power systems, but I’ve noticed that many CAN’T support 36 HDDs (via LSI MegaRAID SAS 12 Gbps HW RAID HBA) and a Mellanox ConnectX-4 100 Gbps IB NIC and a RTX A2000, all in a single system. (Most low(er) power systems don’t have enough PCIe slots for all of that. And my system isn’t even fully populated in terms of what I can fit, in said PCIe slots.) Even low power systems that can only handle 4 HDDs at a time, may approach 40-50 W when in use, *9 (36/4 = 9) = 360-450 W. (And then I’d have to run more support infrastructure to be able to tie it all together vs. having my “do-it-all” Proxmox server, do it all – in one box.)
I’ve looked. There doesn’t seem to be a great way to get performance, PCIe slots, and 36 HDDs in < 500 W.
I don’t remember.
I think that with nothing plugged in and nothing running – it can be very little.
Also keep in mind that this is an externally managed switch, so there’s no Celeron 1047UE processor in there to manage the switch, which helps reduce the power consumption of the switch itself. The down side, of course, is that you’d need at least one of the system that’s plugged into the switch, to run the OpenSM subnet manager, but since you’re going to be plugging the system into the switch anyways, that’s not that big of a deal.
100% agree.
The ceph mgr dashboard, I think, is a must have add on, so you get to do more with it.
I’ll have to check the logs when I get home.
Agreed.
But that’s 23 Gbps out of the link capacity of 100 Gbps (vs. the 4x25 Gbps).
The test method was literally set the port LINK_TYPE using mstconfig from IB to ETH. Reboot. (Or there was a way to like “reset” the PCIe bus without rebooting so that the change will go into effect.
Then between my two 5950X nodes mentioned here, I had a DAC cable that went between both systems where each system, one of the two VPI ports was set like this.
And then in Proxmox, create a “Linux network bridge” (which turned out to be an ethernet bridge. I didn’t know that a priori.)
And then from there, set up two VMs (I think it was Ubuntu VMs, because it was relatively quick and easy) and then used iperf to run the network test between the VMs.
Nothing complicated nor crazy. (I’m not that sophisticated. My goal wasn’t to test the network. My goal was to try and see if I can deploy HPC applications such that I can share the 100 Gbps connection between LXCs/VMs so that I don’t have to bind and unbind the Mellanox NIC whenever I start up a VM that has it assigned via PCIe passthrough. That was what I was really going after. Didn’t really work though.)
I would imagine that if Ceph runs off Ethernet, then RoCE should help make some of the stuff that it does take fewer CPU cycles by having RDMA.
I dunno.
I try to use RDMA as an offload, as much, when, and wherever possible.
Frees up CPU cycles so the CPU can focus on doing other stuff.
(Sidebar: I did find this Nvidia developer’s guide on how to bring up Ceph with RDMA though. I think that one of the reasons why people might not use RDMA as much (especially in the ethernet networking space) is because it’s not nearly as well known nor as well supported as it is in the IB networking space, due to the background of IB vs. the background of ethernet. Plus the process/procedure to enable RoCEv2 – it takes a few.)
Yeah, I know. I’m not completely clueless about it, but I’ve heard and read about it. I just never tried it myself, to see what it’s capable of and how VMs are presented with ceph (the idea of my previous reply was that ceph would be presented just as a block device through qemu on a VM - I brought up that I’m not sure about it, because I haven’t played with it myself to see).
Now that’s a test I would get behind.
Nice!
My point wasn’t that. My point was that only RAM is migrated between hypervisors. And if your VM only has 16GB of RAM, you can live migrate it really easily on gigabit. I’m not going around and recommending people use gigabit (and I’m personally not a big fan of LACP, I prefer balance-alb - decent performance when it comes to multiple communication threads, but none of the downsides of LACP, nor the requirement to have the same settings on the switch).
But when you don’t migrate a lot of RAM contents, then 100 GB is a waste (unless you are getting other benefits, like lower power consumption than a 10G Ethernet, which I could see happen). And just because “it’s a waste,” doesn’t mean it’s not cool, not to mention discouraging you from testing it out. I’m looking forward to see what else you can test in your infrastructure with that 100G IB.
But I also need to point out that the way proxmox live-migrates VMs is basically seamless uninterrupted, so I encourage people to try out live migration if they have the hardware for it (by hardware, I mean, more hosts, the specs of the hosts are irrelevant). Even if one has to wait a couple minutes to migrate a couple VMs, one won’t have more than 2-3 seconds of down-time for each migrated VM and the VM itself won’t even notice it switched hosts (unless you had other things on it, like passed hardware, but that’s another story).
God… I hope your power bill is not too high. My power bill more than doubled, back in the day when I started running a xeon x3450 at home (with 11x 2TB HDDs).
True. If you’re looking for baller performance, you need to pony up for the power bill. I’ll personally stick to my SBCs, but I still encourage people to play with big metal, even if they don’t power it 24/7 (my threadripper 1950x is my example, hypervisor with 128gb of ram and hardware passthrough - I only power it when it’s not too hot outside, because my room will easily go up 4-5C / 6-8F when that thing’s running, but I’d also like to save some power).
Proxmox runs Ceph and gets all the RBDs (they are like iSCSI shares or zvols with ZFS) as you now have lots of new fancy RBDs available as block devices on Proxmox, you can hand them out to VMs like you would with any other block device.
It’s like using Zvols with ZFS. But with Ceph, you have actual kernel drivers and you don’t need iSCSI. Also available on Windows btw. Direct mounting of RBDs in your filesystem.
SBCs…very tempting. But I miss the PCIe lanes for NVMe and ability to get some proper networking (e.g. 25Gbit+)
So…in Proxmox, you can add the storage type as “RBD” and then Proxmox and Ceph work their respective magic. From there, you can tell, it depends on what kind of “stuff” you want the RBD storage option to store (Disk images and/or Container images).
If you enable both, then when you create a VM (or a LXC), when you get to the part where you add the VM/LXC disk, you can point it to using the RBD storage option, and then Ceph pretty much just handles the rest. And then the way that it gets presented to the VM will depend on whether it is using IDE emulation, SATA emulation, SCSI emulation or VirtIO Block Device.
You can see that it did that in 13 seconds. For a VM with 100 GB of RAM provisioned to it.
Can? Yes. But if you HAVE faster network available to you, unless that network is really busy, otherwise, leverage the capabilities of whatever faster network you might have, available to you/at your disposal.
(My point for posting this was to demostrate what 100 Gbps IB can do with this type of a use case, for shits and giggles.)
Doesn’t that require at least the switch to support that?
I didn’t acquire the 100 Gbps IB stuff for storage.
Unless I am running NVMeoF, I agree with you, that for storage (and storage ONLY), 100 Gbps IB would be a waste. (unless your storage needs are such that it scales out to 100 Gbps levels, which very few homelabbers need 100 Gbps for storage.)
(It MAY help, if you are working with and/or loading some of the larger LLM models though, during the initial load in to VRAM.)
Varies.
There’s been times when, from a system/cluster cold start, that the first time I try to run the live migration, it may fail. But after the cluster “warms up”, then I can toss the VMs around like it’s a hot potato and the cluster doesn’t care.
But there have been times where the live migration may/can fail.
It also won’t work if you have other properties defined such as having a local ISO that’s still attached to the VM. It won’t live-migrate that.
If you are using thin provisioning and the target node for the live migration runs out of space (even though you’re using thin provisioning and you haven’t used all of the space in the VM disk, then that can also prevent the live migration from succeeding). I ran into that when I was trying to do some of the Ceph over 100 Gbps tests.
I actually HALVED my power consumption with this system compared to where it used to be.
That’s what led to the mass consolidation project that I ran in January 2023.
I have yet to find a SBC that support the full bandwidth of a PCIe 3.0 x16 (the Mellanox NICs).
I mean, when I have a load average of 20 on dual Xeons, putting that kind of a load on a SBC (or even a CLUSTER of SBCs) – it would make the SBCs sweat. (I was looking at the LattePanda compute cluster, but you can’t buy that anywhere.)
(Trying to get Photoprism to index 5 million photos will suck on the SBCs.)
(My N95 runs close to some of the SBCs, and beats a smattering of them, and it struggles with more computationally intensive tasks, which is also why I have the “do-it-all” Proxmox server, so that I can shrink my homelab, rather than expanding it - like most tech YouTubers and homelabbers.
(Threadripper 3000-series is out of reach for me, still, price-wise.)
It ended up being 70 W at idle (but that’s also with 4 DACs attached to the switch right now, plus 2 AOCs).
But once the entire cluster + IB EDR is up and running, it idled at around 260 W. When I am migrating a VM, it starts off at the 260 W-ish range, and then it will go up to ~310 W, and then momentarily spike up to 360 W for a second right before the migration completes.
So if I had guess, I would estimate the average power consumption to be ~330 W. But that’s the switch, DAC cables, and three systems.
I am sure that if people wanted to reduce the power consumption, you don’t need the 5950X nor 7950X.
But given the speeds, I suppose there’s a price to pay for performance?
At upto 16.7 GiB/s (133.6 Gbps), that works out to be about 0.405 Gbps/W, which means that at the same efficiency, to do achieve the same efficiency with 10 Gbps, you’d have to accomplish it within a power envelope of 25 W for the entire cluster/system. If the 10 Gbps version of this takes more than 25 W, then despite the higher power consumption, it would still be more efficient, overall.
As for moving more than just the RAM state – so because I only gave the root partition 128 GB, the drive doesn’t have enough free space to be able to do a live migration after moving the VM disk to local-lvm. So I have to do the migration cold, and as such, it was only migrating between local-lvms at ~ 750 MiB/s.
But when I try to use dd to do the write test to the VM disk inside Ubuntu, I could write at upto 2.5 GiB/s, and read at upto 21.4 GiB/s.
The whole purpose if to go so small and efficient as to not need that much throughput. That means more bare-bones services and less convenience (arguably less attack surface too). My SBCs all run on gigabit and I can’t wait to upgrade some to 2.5G (not that they really need it).
For PCI-E lanes, there’s some higher-end stuff, like the honeycomb lx2k, but by that point, just buy a ryzen system (or an older epyc). Obviously, you won’t be running ceph on these… but with just a NAS and a zfs replication (if you really need HA), it’s doable.
I don’t think SBCs are for everyone. Lately the only SBC I’ve been recommending is the odroid h4+ / ultra, because it’s an intel board. It’s hard to recommend the rockpro64 or n2+ to people (particularly if they don’t want to navigate the murky waters of ARM OS support). To some dedicated / knowledgeable linux users, it makes sense. Also, freebsd runs like a champ on the rockpro64.
Note that if you aren’t using that RAM, most of it will be zeros, meaning it’ll easily compress and send over the network. Try to make a linux VM and create a 96 GB tmpfs and fill it with garbage from /dev/urandom. Then, try the transfer test.
It might take a while to complete the dd, but that’ll be a better test to see the throughput (it should still be very fast, as you’re doing RAM to RAM transfer, over a 100G pipe).
Balance-alb is a MAC address hackery on the host side, you can use a dumb switch with it. LACP requires the switch to support LACP bonding and you need to configure the ports accordingly. That’s why I prefer balance-alb (again, you don’t exactly have scalability for a single thread, for example, NFS will run at a single port’s max speed, but if this is your NFS server, you can have 2 NFS clients connect to the server via the balance-alb bond and each one of them will receive each interface’s maximum throughput).
Balance-alb (a.k.a. bond mode 6) is useful when you run out of LACP groups on your switch, or when you don’t want to put too much load on your switch (LACP can be taxing).
Interesting. My hypervisors rarely saw reboots, but it happened a few times that I had a live-migration fail mid-way. I never looked too deep into it, as more than 90% of the time, it worked fine. I only live migrated to patch the hosts, reboot them, then live migrate VMs back, along with other ones, until all hosts were updated. And that didn’t happen often, maybe once every couple of months.
But a live migration failure, for me, never resulted in a crashed VM, just that I needed to restart the live migration process. A slight PITA, but nothing really bad.
Yep, happened to me too.
I never knew what thin-provisioning was (sarcasm, I knew, but I never used it, never really liked it). Ok, I used it of very few scenarios, when I had proxmox with an LVM thin-pool configured, but I eventually got rid of that and had an LVM thick-pool instead (alongside the NFS backend for qcow2 for most VMs).
I doubt you’ll find one, because they’re not meant for that. There’s some ARM micro-ATX and mini-ITX boards out there with 16 cores and full pcie 3 x16 slots, but those don’t really could as “single boards” (well, the term itself is kinda poorly defined, because the odroid h3 and h4 boards are considered SBCs, yet they have SODIMM RAM - not to mention all the SBCs like odroid M1 that have m.2 slots, those are technically additional boards).
Yes! They’re not meant for that. You’d be lucky if your nextcloud instance runs without lagging. Well, you could run on something like radxa rock 5, but it’ll almost certainly struggle with photoprism with too many photos.
Well, that’s a good thing IMO. I think homeprods don’t need a lot of redundancy and especially not a lot of HA. Not really worth it, when you can just wait a bit and restore from backups. You’re not losing money if whatever service you’re running is down.
Well “efficiency” depends on how you calculate it.
If you are only looking at cost vs. power, then yes, but that leaves out performance and/or features of the system.
If you factor in features as a part of “performance”, along with actual CPU performance, and the compare it against the cost and power, then it gives you a “fuller” picture of “efficiency”.
When I compute “efficiency” that way, SBCs end up actually being not all that efficient (because they generally have relatively poor performance overall or can’t really provide much in the way of features). You can get a SBC for say anywhere between $30-roughly $80. But you can get a mini PC that can have dual GbE, and the Intel N95 Processor, which tends to be more performant, for double the price of the SBC. So, when you compute the $/(performance/watt) metric, the mini PC end ups being more “efficient” when calculated that way.
Most Ryzen systems are still only limited to between 20-28 PCIe lanes, which means that for expansion, at best, one node can only really supply one PCIe x16 slot. But if you’re trying to distribute the processing because the individual nodes aren’t that powerful, then it will put a greater demand on the networking infrastructure so that the data can be passed between the nodes, for distributed processing.
Even older EPYC systems, are holding their value a little TOO well.
So I quickly googled this and it’s $139 before you add the power adapter for as little as $9.40. That’s a total of $148.40 and it doesn’t come with RAM nor storage.
By comparison, the OASLOA Mini PC right now, goes for $167.59 on Amazon.com and has 16 GB of RAM and 512 GB of storage. It has a marginally slower processor (N95 vs. N97 from the Odroid H4+) and dual GbE rather than dual 2.5 GbE.
By the time you add in say, 32 GB of DDR5-4800 RAM ($79.58), and a Crucial P3 1 TB NVMe SSD ($56.98, both from newegg.com), the total before taxes and any S&H charges, is $284.96.
And of course, you can pick cheaper components, but again, if you factor that in to your “performance” number that will be used for the $/(performance/Watt) calculation, then it all comes out in the end anyways.
If you’re willing to take the gamble with AliExpress (which tech YouTubers like Patrick from ServeTheHome and even Wendell has bought some stuff off of AliExpress), you can buy a GMKtec M5 Plus Ryzen 7 5825U Mini PC with 32 GB of DDR4-3200 RAM and a 1 TB NVMe SSD for $290.50, preassembled.
From cpu-monkey.com, the N97 Geekbench 6 Multi-core benchmark score is 3051 vs. 6765, or a little bit more than double the CPU performance for ~$6-ish more.
This is one of the reasons why I haven’t tried using SBCs yet because I can’t get the $/(performance/Watt) number to fall out in favour of SBCs, once all is said and done.
To maintain the same $/(performance/Watt) efficiency competitiveness, SBCs would have to be priced SIGNIFICANTLY lower so that it can hold the efficiency line.
re: Arm
It’s unfortunate that Proxmox on Arm is a community-led project, but with no official support from the Proxmox devs.
However, looking at some of the stuff that Jeff Geerling has done, Arm, again, when it comes to $/(performance/Watt), still isn’t quite there yet.
(I’m hoping that the RISC-V procs will help break into that, but hasn’t quite happened yet.)
I can run that test. It will take some time to generate the random, non-zero garbage, to fill up that space.
I’ll post the result when they’re available.
re: balance-alb
I appreciate you educating me on that.
I’ve read that even with LACP, you don’t always necessarily get double the bandwidth like many people seem to think (simplistically), at first.
Yeah, not really sure why this is happening neither.
This isn’t ever going to be deployed as a production system. I’m just testing it for fun/cuz I can.
It’s happened a bunch times for me, during the course of running these tests, that especially after a cold start, that the VMs will migrate, but then crash or end up in a stopped state, despite the HA being set to “started”.
I dunno.
I’m not too worried about it as I am not likely ever going to deploy this as a prod system at home.
re: thin provisioning
My main Proxmox server runs entirely with spinning rust, so I only use thick provisioning, in prod.
For this, the thin provisioning helped speed up creating the VMs for the purposes of the live migration tests.
via TechnoTim: “It’s almost always the DNS.”
So, as such, my 3-node Proxmox cluster with my mini PCs, like I said, runs my Windows AD DC, DNS, and AdGuard Home.
Those services, I like for them to stay up.
I have one other system (Beelink GTR5 5900HX mini PC) that also runs Proxmox via an Oracle VirtualBox VM that runs in Win11 that is responsible for hosting Photoprism that my wife will send/dump her pictures from her phone to. (I originally bought one with 64 GB as my desktop replacement and I liked it so much that I ended up buying this second one.)
The stuff for the wife and tiny humans - I try to separate out from the rest of the backend, so that they may have a higher uptime than some of my other stuff and I can tinker/reboot as needed without taking their services down in the process.
(I ended up just running 16 parallel processes (6 GiB each) of this so that it would write the garbage to RAM a LOT faster.)
Insecure live-migration: 3.1 GiB/s.
Given the slower speed when the RAM is full of non-zero data, I’m not really sure if having 10 GbE will yield the same result or whether it would scale proportionally with the slower interface.