Hello! I converted an Ubuntu software RAID5 server to TrueNAS Z2 recently. The networking is still 1Gb but I’m thinking of using the MicroTik 5x 10Gb SFP+ to set up a SAN … anyway … edit: this server is 100% for backups and plex media storage. No unique data will ever be on it. Everything can be replaced.
About this machine
AMD Ryzen 3400G Pro APU
AsRock B450 Pro4 mobo
Kingston ECC ram 32G @ 16G x2 sticks
120GB NVME m.2 boot drive
SYBA pciex4 miniSAS to SATA controller, non-raid with 2x sata octopus breakout cables
256GB m.2 SATA for SLOG w/ large aluminum passive heatsink
2x Silverstone hotswap HDD cages that converts 3 x 5.25" bays into 5x 3.25" HDD trays … so 10 hotswap slots in total
iStar 4U case D-400-6
Seasonic 650W PSU
The configuration of the Z2 Pool is 8x 3TB HDDs including 1 hot spare. The drives are mixed Hitachi ultrastar and WD, all used server pulls. I am also using 1 256G M.2 SATA drive as a SLOG. I understand that this is 2x more space than TrueNAS can use for a SLOG, and perhaps I will over-provision that m.2 to use up the extra space and provide wear-resistance to the drive???
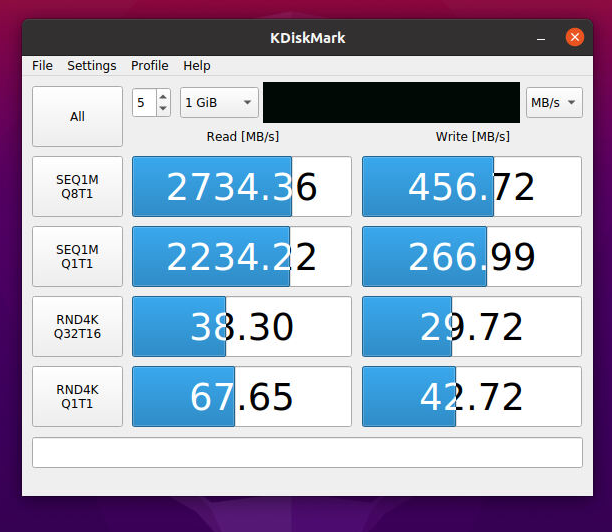
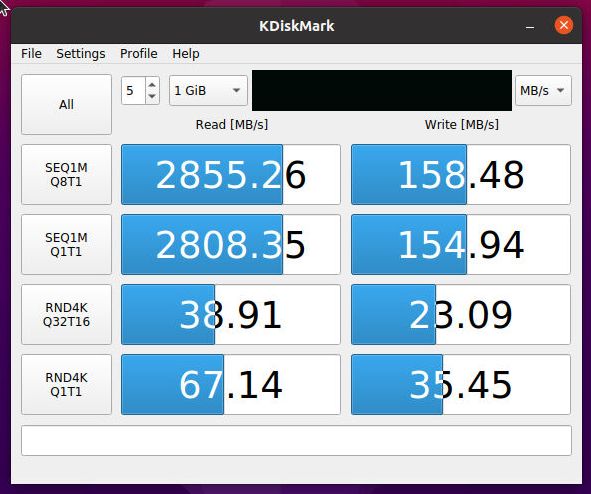
I spun up an Ubuntu 20.10 VM inside TrueNAS and ran DiskMark on the Z2 array. I’d like another set of eyes on the results, and comments are welcome of course. I had been reading that “most people do not need a SLOG” and disabled it, intending to pull the M.2 drive and use it someplace else. After the DiskMark results tho, I re-enabled it for giggles and was very surprised when I ran the bench again.
I had not fully grasped the fact that the “write buffer” operates at the speed of the slowest HDD in your Pool. Adding a true 600MB/sec device as a SLOG raised writes from 150M/sec to 460M/sec
Unless I’m just wrong and reading this incorrectly
As I understood it, the ZFS Intent Log (ZIL) is a limiting factor and only exists on 1 drive of the array thus is limited by the speed of that single drive. Unless I am mistaken, providing a ZIL external to the array on perhaps an M.2 drive (external ZIL is a SLOG) will allow writes to the array limited by the speed of the SLOG device ~
It was pointed out to me that I was running the test locally in sequential mode and disabling safe sequential writes would improve speed … but whats the point of having a “safe” ZFS server running ECC ram if you are going to freeball the write safety
The way I understand it using a ZIL can help a lot with writes in an array of mechanical storage and the ARC/L2ARC helps with reads. How well that scales
I’d imagine if someone had a rack of spinning storage they would need one heck of a ZIL drive to keep up.
ZFS always has a “ZIL” (ZFS intent log). This is an area on the pool that ZFS will spew writes to as fast as possible in order to decrease the latency of responding to to the program requesting Sync writes.
What adding an SLOG (Seperate/secondary log) does is provide a dedicated device to spew those writes to, so that you’re slowest disks can avoid a pretty bad workload. The ZIL/SLOG are never read from unless there is a crash, so an SLOG can’t even be considered a write cache the way such a thing is normally meant. All writes, both sync an async are still packaged into txg’s and written to the pool in normal intervals.
The basic rule is that the slog should be faster than the pool, especially when it comes to small block writes.
So it’s best to consider an SLOG as something that doesn’t accelerate a pool, but rather it takes back some of the massive performance loss resulting from needing to use sync writes instead of async writes. Even if you were to create a ram disk SLOG (lmao), sync writes will still have an obvious performance loss compared to async because of the additional software overhead.
Various flash drives will certainly be at least somewhat better than hdd’s, but most won’t be very good. It’s optane tech that really shines here.
L2ARC helps with repeated random reads. It’s fill rate is by default limited to 8MiB/s, otherwise it’d burn through disks.
It’s not useful for sequential reads, which ARC and L2arc specifically resist taking in.
So basically it’s for databases and torrents. Maby VM’s.
L2ARC is for when your workload (hit rate) won’t fit in ram, but will fit on an SSD, but the total data involved is too big to fit on an SSD (like a huge database)
Most of the time you are better off creating an SSD pool.
Ah thank you I didn’t realize that SLOG is supplementary to ZIL and does not delete the ZIL.
As you can see my SATA m.2 SLOG recovered speed for sync writes from 158MB/sec to 457MB/sec in my 7 HDD Z2 array within an Ubuntu VM on the TrueNAS box as a testbed.
edit- come to think of it, I should move the boot/root m.2 drive to the SATA m.2 slot on the motherboard and move the SLOG m.2 drive to the full speed pciex4 m.2 slot on the motherboard and see if it makes a huge difference.
VMs and databases both typically have random writes followed by sync/flush operations. These are an issue with all COW and/or checksumming filesystems. LSM trees are a class of data structures that turns all writes into sequential writes. Examples would be rocksdb (based on leveldb used in chrome/chromium) that you can use as a table engine in MySQL. Or if you need to store your monitoring timeseries then one of the influxdb formats.
I don’t know of any opensource log structured volume format that can be used to back qemu VMs (qcow are not it).
For torrents, the issue is metadata fragmentation. Torrent clients do random writes but don’t sync and then it’s up to the filesystem driver to choose how to coalesce writes to stable storage (in time or space) and when to commit whatever is in ram to stable storage. Blocks in torrents are a power of 2 in size and since it’s usually big files that are shared these blocks often end up being 4M or 16M per block. Many torrent clients will just download a series of chunks sequentially even if smaller files are shared. Another problem with torrents is when you have many small files - the blocks may not be aligned - it’s up to whoever makes the . torrent file to try to put the largest file at the beginning of the torrent for alignment.