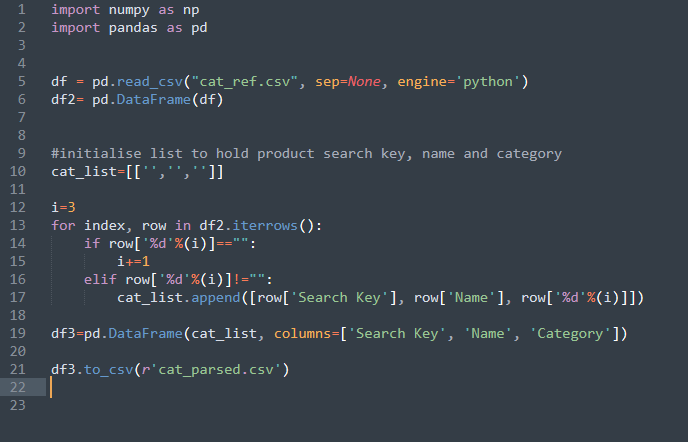
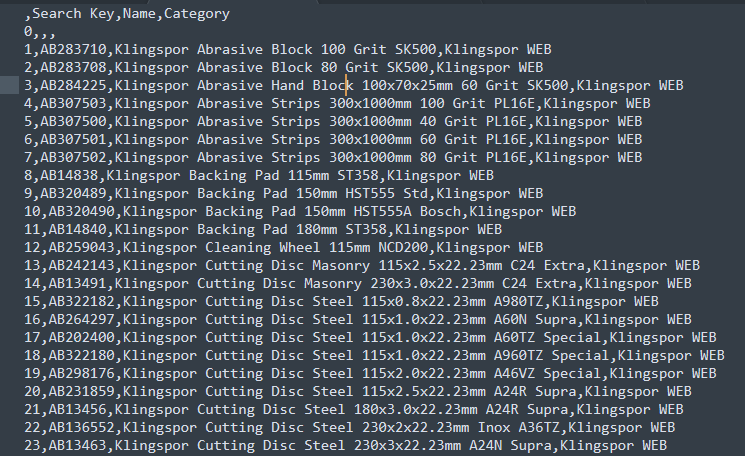
As the title says I’m new to pandas and I’m trying to check whether an element in a dataframe row is empty, and if it is not null pull some elements from the row. My goal is to parse a csv which has product names, IDs and product categories used in search indexing.
Each row of the csv has multiple categories and the end goal is to create a list with the product name, ID and a single category for each item, with the multiple entries for each product that has multiple categories.
My idea was to load the csv, create another dataframe to hold the data in case I make a mistake and alter the original, and loop through each row with .iterrows, incrementing a variable and using a for loop to get the elements in question. At each iteration append the product row name, ID and current category to a list that I’d convert to a dataframe and finally a new csv.
But for some reason it doesn’t go through each row element making copies for each category, I only get the third element(category) as given by the variable i.
oh btw you don’t have to iterrate over the rows most times unless you are doing something like a slice or push, you can just drop rows if they have something, pandas handles it on the backend
edit:
This page explains drop pretty good according to my cursory overview:
pandas can do a lot on the back end
you don’t need df2 when pandas imports from a csv, all the data is stored in df any changes to df is not written to the original csv file
I don’t quite understand why you have additional arguments after the csv, but see if pd.read_csv("cat_ref.csv") will load the dataframe. You only need the additional arguments if your csv file has issues loading with the default.
A thing to note, pd.DataFrame() is usually used to convert a list to a dataframe structure.
You really don’t need the for loop, to check for values
if you make new data frames, you can set conditionals in the new dataframe intialization
Thanks a bunch. I worked through the data fine in pure python and the csv module, but getting used to Pandas when you keep trying the stuff that worked before is a trip.
I’ll piggy-back off this reply to push @bedHedd and his post below, haven’t finished going through it all but it has great detail for anyone having a problem like I was.