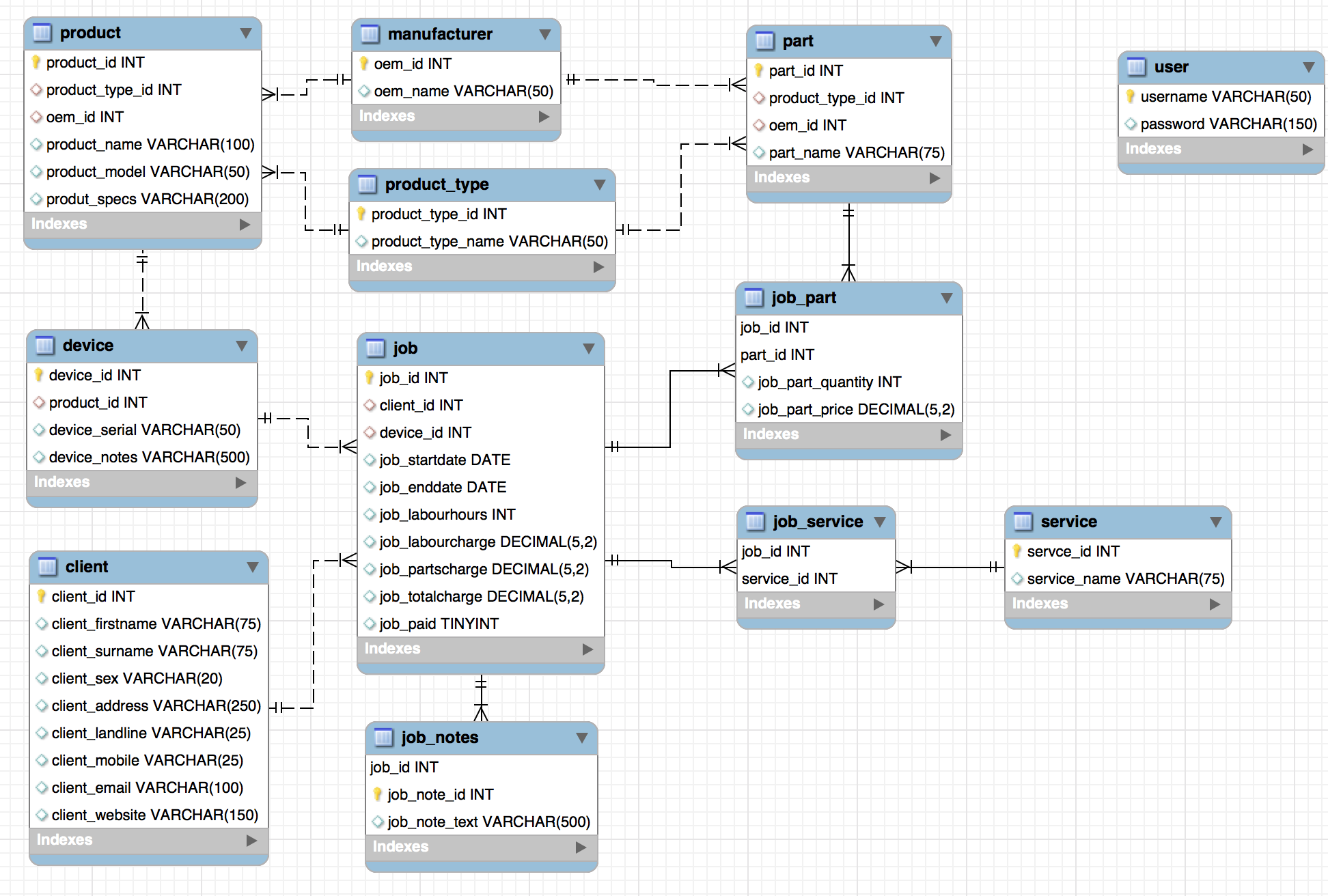
In my spare time, I’e been doing tech repairs for the people around in my community. To help keep things recorded and organised (And to give me an excuse to program), I figured I would create a basic database to record jobs I’ve done. Included in the jobs are parts used and services performed, as well as recording the devices and clients. If possible, I would love some feedback, as I’m not an expert in database design. I would consider myself average, at best.
Also, ignore the user table for now. I’m not sure yet if I want to use that for authentication into the program I’m making, or if I’ll just use existing MySQL user and password for authentication.
I would say actually use the user in your schematic. Then you could associate another key for a job to whoever created it. Or for the service to who performed it etc
Even though it’s just you. Designing for scale now means if this took off to a small business or something then you are already setup for it
Manufacturer and product type should be inlined, you can put an index over those and their cardinality is low.
You’ll need some kind of log, either within a database or outside of it - you’ll want some timestamps and usernames and some kind of action log somewhere.
How do you mean inlined? Like making a manufacturer/product type field in the product and part tables? I would have thought that would increase the amount of redundant data, no?
In general it looks OK. By looking at it I can imagine whats it is all about. As always, it might be that you might be missing something that is very important for your business, but without at least few hour interview and then few more clarifications no one can tell definitely.
I’m not sure what @risk had in mind, but at first glance I also read it as suggestion for putting the single fields you have (manufacturer and product_type) into the product.
I would be against it for following reasons:
it actually looks better when separated as generally those relations are inherently 1 to many
you might have concerns that a table with a single business field looks as a week detail in the design but it is actually opposite (in those cases), because:
you protect you self (to some extend) from having values like “MS” “MicroSoft” “Micro Soft” “micro SoFt”
you can actually change the name of manufacturer in one place.
you can easily extend the information about the manufacturer or product type or introduce new relations with them (e.g. manufacturer contact list)
Yes, you introduce some overhead to access this information (e.g. you will need to use joins or framework for persistence will need to). But there are “tools” to eliminate that overhead (views/materialized views, or good configuration of the persistence framework).
Other things:
The lack of “product” <–> “part” relationship (N:M) looks odd for me. Because of N:M (not just 1:N)l, it would require association table). But then again, that relation might be not needed and too costly to have/maintain. And I’m seeing that connection only because I’m probably too deeply into Linked Data.
I would consider of dropping relation between “part” and “product type”. But that depends on the business (I can simply imagine that there are various of types of electronic devises that can have soldered in similar parts, e.g. capacitor).
“job_part” name I would change to “job_orders” or “job_external_orders” (I assume that it is for list of parts replaced in the device - AKA list of parts you order outside).
“client_sex” name I would change to “title” Mr/Ms/Ph.D/etc or get rid of it.
consider option that the client could be a company: e.g. change “client” to “contact_person” and add relation (optional) to new table “company”
I suggest to do not use MySQL user credentials when logging into your application. In general application must be capable of accessing the DB without user intervention. You might not need your application to do so, but even then logging in with DB credentials is just weird. Even if no security is really required, just have this “user” table with one entry in it.
Yes, basically denormalize it and make (manufacturer, product) a primary key (or primary key part) and get rid of random primary key ints.
It just makes the schema simpler and probably your queries easier if you denormalize and use organic instead of synthetic identifiers when you can.
At the stage you’re in, I’d aggressively focus on usability over theoretical correctness or performance or space (it might actually perform faster this way and take up less space due to how innodb works).
There’s always a balance to be found when normalizing data, you can take it too far. If you were only ever going to deal with a few manufacturers e.g. ‘HP’, ‘Dell’ it might make sense to keep them in the product table - especially if you are not storing any details about them, just a short name or abbreviation, no address, contact information or account manager etc. But as @jak_ub points out there are lots of good reasons not to.
Whilst not breaking up some data will not meet the criteria of proper normalization, it might be good enough for you. You’ve basically done this already with product specs when you think about it - you’ve made that a descriptive string, but to be properly normalized could have either broken it down into columns for ‘CPU’, ‘RAM’,‘Disk’ and just entered a value in each or gone for a table of CPU models and ID’s for each one… Trying to think about what will be used in WHERE clauses in your queries may help guide you here - searching strings for values that may not be consistent will be painful.
Another reason for keeping table count on the low side (if sensible) is that once you try and join more than 7 tables in a single query the query engine will usually give up trying to find a good quality plan, will time out and you’ll just get a plan that sort of works. Obviously there are times in many databases that more than 7 tables would need to be joined, but that’s what temp tables and views etc can also help deal with.
On the security/access front, not having a user/hashed passwords table can be common for internal facing corporate systems - your users authenticate in the application layer using Active Directory or similar, the app layer will often then use a common service account to access the database, or it may pass the user credentials through - in which case the users often have group membership which is set up against the database to allow read or execute access only to certain objects. If you are building web apps that support external users then the type of thing @Ctrl_Null describes is more usual.
When designing a database it can be really hard to find the right solution, what is right on day one might look terrible 3 years later when your company has expanded. I’ve worked on OLTP databases (online retailers) that were into the TB’s in size because the developers (8 years earlier) had no idea their company would be a success. Unpicking technical debt like that, is an interesting challenge - especially when no one wants any downtime
One thought I had about the separate manufacturer table in particular, is I could have a table to hold aliases for each manufacturer. Like, I could have “Hewlett Packard Inc” in the main table, and in the aliases, I could have “HP”, “Hewlett Packard”, “HP Inc”, etc. Either that, or just separate the name column into the full name, and abbreviation or short name.
I could probably rename the product table. My main need for the product table is to hold information about devices, specifically. Like OEM PC’s/laptops, phones, tablets, etc. Rather than holding all types of products, including part products. The part table is the parts counterpart to the product (maybe change to device?) table.
The product_type <-> part relationship is so I can hold types of parts in the product_type table. Like CPU, Memory/RAM, HDD or SSD. I was originally gong to have a part_type table, but I felt like that could add a smidgen of needless complexity. Unless you think otherwise?
I can agree to that completely. I wasn’t sure what I wanted to do there. In the past, I’ve used a gender/sex table, where I could hold not just male, female and indeterminate, but could hold any number of genders. However, probably unnecessary. I can change that column. Should I leave the column as a varchar type, or change it to being a foreign key pointing to a title table?
While not necessary now, that’s a good point. I have to include possible future use, where I might have companies coming to me.
So after initial setup/installation of the application (Which is where, I presume the DB credentials could be entered), the application stores the credentials somehow? I’m not very well versed in how to do things like this, especially since it’s about security. Right now, pointers towards doing it in a home office situation (I have a basic Ubuntu server box hosting MySQL and network shares, no AD or anything) would be awesome.
Beyond that, thanks heaps for the detailed point by point response @jak_ub
For my uses, a descriptive string is plenty. As there will be different types of devices, I would prefer just to list off what they have, as opposed to storing specifically individual components. I won’t need to search a device by it’s specs. I mostly have the specs there so I can quickly reference that based on a specific device, either if it’s one from a customer that I’ve dealt with before, or I’m reviewing jobs.
At this stage, this will only ever be used by me. It may or may not ever change. Being the full stack (I guess that’s the right term, despite being a desktop application) developer, I can modify this at a moment’s notice if I need to start authenticating another way. Although, that might bite me later.
Name ‘device_type’ actually might be a better name.
I would then just adjust name of the table “product_type” to be more generic, e.g. ‘item_type’, ‘component_type’. Or actually if you would go with change of “product” to something like “device_type” then name “product_type” might be OK.
The point is that if something is more generic then we should try to avoid naming it in a way that suggests it is strongly connected to single table (as long as we can).
Definitely not directly in the code.
In the future I might want to run other instance of the application (presumably with different database), or maybe even share source codes in some repository.
Usually DB parameters (host, port, db name, user, password) is stored in a file that application reads during start.
I think it is also acceptable that in cases like PHP that a file containing such information is actually a PHP code declaring the variables. The most important thing is that it will be dedicated file for such sensitive information and in case of PHP it will not be exposed via server directly. It is kinda in the code, but in a cleaver way.
I personally have experience with Java so for me it is usually JNDI (in general place for configuration in form key/value) or property files as a configuration of application.
Thank you so much for the help. I’ll be making a few changes to the schema tonight, then I can start my programming.
Funny enough, I’ll be writing the application in Java, so thank you for the nudge in the direction of looking at JNDI. Just as a side question, how best should I use the database information in my application? Have an object/struct for each table and just map them directly, or is there a better way? Most of my experience with connecting a database to an application was C#, using Entity Framework and ADO.NET, which I feel might have spoiled me a bit, and possibly stunted my learning at the time.
I’ve been using the designer in the MySQL Workbench. It allows for me to design the tables without creating a database on that machine, then when I’m ready, I can forward engineer it to a new database schema. It can also take existing schemas I’ve made and reversese engineer them into a layout like this
JPA is the general standard for ORM in Java. JPA it self is common API for persistence via annotations. The most influential implementation is Hibernate. The JPA actually was designed by community organization, based on earlier Hibernate implementations.
Once standard was designated as final by community, many different ORM-like Java frameworks for persistence started to implement the API.
That said, some or many other frameworks did not, because of major differences.
JPA/Hibernate/EclipseLink/DataNucleus in general can be simplified to following description:
annotations on fields and classes (POJOs) that instruct how data should be persisted in database
entity manager to call to read/write objects
query engine to query with similar SQL language for lists or single objects
most JPA implementations allow to use native SQL.
Spring Data
Spring Framework has few persistence frameworks interconnected.
JDO
To be honest, nowadays too similar to JPA. I never heard about commercial project using JDO. Some actual implementations of JPA also implement JDO.
I think JDO it started long time ago but mostly had academic use. And at a time commercial software development was looking for something better than JDBC projects like Hibernate erected and gained popularity.
Many others
There are many others frameworks and APIs. Toooooo many to be honest. Offering different approach to persistence, being frameworks or libraries, ORM or not ORM, offering different support for actual data storage (RDBMS, graphs, tripolesotores, key-values, documents, XML, JSON … and that crazy robot arm project that two, too drunk, students are thinking about, to store information in Quipu language).
I’ve started with the most commonly used (maybe with unnecessary mention of JDO).
But most commonly used, not always means that there are the best.
Schema looks okey, whats worries me are ur countrys legislation on recording custommer data. Atleast where I am from, we are currently working on implelemting the new GDPR law, this makes it mandatory to keep the custommer informed at all times. On what data you have collected, why you have it and what type of information you have, it is also mandatory to let the custommer have access to the stored data at ALL times, and deliver proof of deletion if the customer wants to be erased of your records. And where I am from you are also requierd to apply to a goverment branch to store any custommer data. And if you are caught with no licens, you are fined for redicolus sums, and jail time. Just keep this in mind, it might seem small and inocent. But keeping a real record of customer data, thats no fun and games if you get hacked and the customer information is out in the wild.
I don’t believe we have strict legislation like that here in NZ. I have to comply with GDPR if I’m recording data on anyone in the EU (Which I am not). Anyone within the country, I believe is okay. I do have to register as a business and for tax if I earn revenue about a certain threshold, which is about $60,000pa.