The goal is to make the system boot with either of the drives unplugged or failed, but installing UEFI to both of them and having /boot mirrored on RAID.
Debian 10.5 is installed, but I could not configure a boot loader with the installer, since it wanted to do a single drive MBR bootloader, not a dual-drive UEFI. So I continued/finished without installing a bootloader.
Now I’m chrooted into the installed system, in recovery mode from a USB stick.
I’m having trouble following a bunch of tutorials that aren’t quite made for this scenario, and there’s a thousand ways to do boot.
How do I get a UEFI boot loader installed on both SDD’s (on partition #1 of each SSD)?
Do any of the guides actually say mirrored boot loader? Because it might be a case of installing the boot loader on one drive, and manually copying it over to the other drive? Which would not be ideal, because manual sync always falls out of sync…
Yeah, but I mean, do they say to do it manually everytime the bootloader changes (each kernel update, basically) or do tehy suggest a way to automate the copying/ syncronisation?
You know, I don’t know. But maybe gparted from a USB live image, or DD one partition over the otehr, if you’re comfortable with the command line?
Of all the information out there on this issue, I have found the Arch wiki partitioning entry to be the most concise (as per usual). In short, you need to manually copy the content of the partition containing your UEFI data to the other drive in your RAID array using dd or the like. Once you have done that, you need to use efibootmgr to add another entry to your boot loader (GRUB etc.) so that you can boot from the other drive should the first one fail.
EDIT
In light of @spiders comprehensive reply below, I should also note that once you have created separate boot entries for the two SSDs in your RAID1 array, there is the maintenance issue to consider. In short, it is possible for the content of your first /efi partition to differ from that of the second. Should this occur and the first SSD subsequently fail, you may end up with a system that is unable to be booted.
The solution (as documented in this thread) is to copy the first /efi partition to the second /efi partition every time the content of the first is changed. The trick is determining when this has occurred.
EDIT2
It turns out that the issue of keeping your /efi partitions in sync is also discussed in the Arch wiki EFI system partition entry. Several methods of performing the sync are described.
If you clone one EFI to the other, I would expect both to try and boot to the same device, that of the original. A perfect clone would copy the UUID giving two places with the same UUID, a bad thing, and if you generate a new UUID, nothing will reference it.
You haven’t mentioned “grub” at all, is that the boot loader you want?
It’s likely that you booted the install media using legacy mode; then it wants to do an MBR install. To do a UEFI install, boot the installer in UEFI mode. This is tricky on some motherboards. If you did an iso boot, I think it depends on the system that opened the iso file, but I’m not sure.
The obvious approach is to mount only the EFI (on /boot/efi) corresponding to the chrooted debian, and run grub-install. You could be explicit:
then repeat for the other install. I’d have thought that keeping the EFI partitions mirrored in some sense is not necessary, so long as they boot their install that’s enough, and they don’t change often. If you do get a grub update that would change something on the EFI partition, just repeat the above.
These are some initial thoughts in case they help with clarifications and decisions, though we can work on more as it moves along. Some may already be known; it’s not got a specific exact step-by-step action plan detailed at the moment. UPDATE: past the below comments is the beginning of some findings/verification that could work, but not every detail yet. See “Addressing recent questions” section. (todo: add two example output/images)
If there are any questions about specific steps etc then feel free to ask and we may be able to clarify. I’m not sure of how much any reader may be familiar with (there may be a bunch of non-needed clarifications).
That the installer/you partitioned each disk separately then created separate raid volumes for each partition? (not one raid volume with partitions across it) I think that is what is shown in your comment.
The partitioning is GPT and not msdos currently, correct?
The output of commands like this might help clarify some:
blkid
parted -l
So there are a few concerns when it comes to the efi partition:
(this is assuming the efi partition will be raided and not two separate copies; and software raid is used)
Correct mdadm metadata version may be needed to not mess up firmware’s view of it as a valid efi partition. (if you raid the efi partition)
Will you ever use the firmware(bios) in a way that writes to the efi partition it happens to be using at the time? (that will make raid unhappy or lead to corruption) can you guarantee the bios won’t ever write to it? (I suspect most firmware won’t be aware efi is mirrored)
I’m unsure if the installer would not allow it due to the specific scenario of raiding+efi or, but as jlittle notes, if the install environment did not boot with efi capability/mode then that can cause it to only allow MBR. (If you get a terminal during install time and check efibootmgr -v and it complains and doesn’t list anything then that may be a sign of that.) It may happen when dd’d hybrid iso install media to usb; unsure how ubuntu’s debian’s is setup, but that is a side concern.
Yes, this seems reasonable; though while I’m not familiar with Ubuntu’s Debian’s packaging, Fedora/CentOS provides the grub efi binary directly into the mounted efi filesystem (expected at /boot/efi/) and when the package is updated, so are several of those files (they are owned by the package). So in the case of Fedora/CentOS with grub-efi packages, it’s about reinstalling the package depending on the scenario. I’m no sure if it is the same with Ubuntu Debian.
Yes, with a concern over if the raid members might be corrupted by efi firmware writing in anything for new efivars or key databases etc (unsure which if any do), it may not need to be raided and may be “safer” if not. However,
With grub efi it’ll read the grub.cfg from the efi partition and piece together what it needs to do to find /boot and move forward. I’m not certain of grub’s exact awareness of mdadm raid’d boot, but if it finds the correct id, and then files then it should be ok.
This is to note that the grub.cfg that grub efi reads (at least in CentOS/Fedora and I suspect Ubuntu Debian) is located in the efi partition (like the separate one in /boot if it’s legacy MBR). So if the grub.cfg has the list of kernels then it may need to be kept updated/sync’d at times of new kernels (or as you note, new grub versions).
I could probably test this out in a VM with Ubuntu Debian to check on a few things, though I’ve not tried to setup this configuration with it before.
As a side note, it is possible to put two separate EFI entries in the bios (set with efibootmgr commands is most convenient) to efi partitions that have different UUID, so that it will fall through to the other one if the first is not found just by general boot ordering. So it does not specifically need to have mirrored gpt partition and fs id’s. (This is what RBE/jlittle are mentioning)
EDIT: I kept saying “Ubuntu” above but re-remembered it’s Debian, so will be sure to keep that in mind.
EDIT2: I played with the Debian installer a bit but am going to grab coffee while I let it try one other configuration. ([I later redacted older content here to avoid space/partial details])
Spoiler: I’m not going to recommend using mdraid for the actual efi partition (I usually don’t). On a positive note, the debian default non-raid1-efi configuration may actually work well with minimal/no changes, just need to setup the other efi partition; possibly that ‘backup’ efi feature in the installer could dump a matching partition and not even need any copying of files etc too, but test that later).
TL;DR I’d recommend not software raiding the efi fs, and instead following a strategy like what RBE/jlittle have mentioned. It is possible to raid1 the efi partition but there is a chance efi firmware(bios) can write into one but not the other raid member, and cause trouble, and possibly some confusion for grub tools later that may need other tweaks/moving-parts. If not raiding it, then only one can be mounted at /boot/efi so at times you may need to manually sync them, though debian installed does not place the kernel details in the /boot/efi/EFI/debian/grub.cfg but that file points on to the uuid of the raided /boot which is a great default for this scenario. The trouble in the end requires using the same vfat uuid/fs on both efi partitions so that a single /etc/fstab entry can be added (otherwise systemd can become angry about duplicates, also when one of them is missing when the drive is pulled since it usually defaults to requiring it to be mounted during boot). – as long as the uuid does not change then we likely expect even older stale grub in the non mounted /boot may still work in a pinch when a drive dies, or can easily be updated at that time. (as always testing and considering other overlooked issues is recommended before production use). (Cane choose if same uuid but different label can allow mounting it in a way other than device name which can change, and syncing, etc.)
First important notes regarding last few posts (I tested the Debian Expert Graphical install mode; using a VM with uefi firwmare). (some is different from Fedora/CentOS default behavior so I’ve documented key points here).
Manually partitioning via the installer, including efi partition creation and -efi- bootloader install (no raid picked for efi fs) seemed to worked. If it did not allow anything but MBR then you may want to retry installation and be sure the install media is booted in EFI mode.
The first install dvd grub/isolinux menu will note “Debian GNU/Linux UEFI Installer menu” (presumably that splash image is not “UEFI” if you don’t have it booted via uefi mode?)
Another way to test if in uefi mode is with lsmod | grep efi and efibootmgr -v but only using the chroot / /target after most of the install is complete. (see below) [[ TO BE ADDED ]]
Successful efi install goes into only one efi partition and:
Minimal grub.cfg in efi fs points at raid1 boot volume by uuid, to load a larger grub.cfg in /boot that contains the kernel menuentry.
grub is configured with efi/mdadm/lvm modules as needed.
The efi grub.cfg thus will load the mdadm /boot or members as the uuid will match for all. (good; redundant)
The main /boot/grub/grub.cfg uses lvm pv/lv uuid. (good; redundant)
/etc/fstabis a concern (decide on how to add /boot/efi mounts; w/o breaking systemd/etc; also only one can be mounted there)
If efi fs must be created after install (rescue-cd/booted-os):
The below will help (detail in jlittle’s comment) as expected, once the vfat fs is created and mounted.
NOTE: grub-install did seem to copy a minimal grub.cfg into the /boot/efi/EFI/... path which points efi grub to check /boot/grub/grub.cfg for the next grub.cfg containing all kernel entries.
The minimal /boot/efi/EFI/debian/grub.cfg is 3 lines and is a similar minimal design for both my manual grub-install and the one the installer did without issues/complaints for me.
I would recommend avoiding a grub-mkconfig if the grub-install has already created one, or do it to a different path first to check content. (you don’t want it to contain kernel menuentry). (That eliminates need to update efi partitions every time a kernel is installed. This is different from Fedora/CentOS default behavior.)
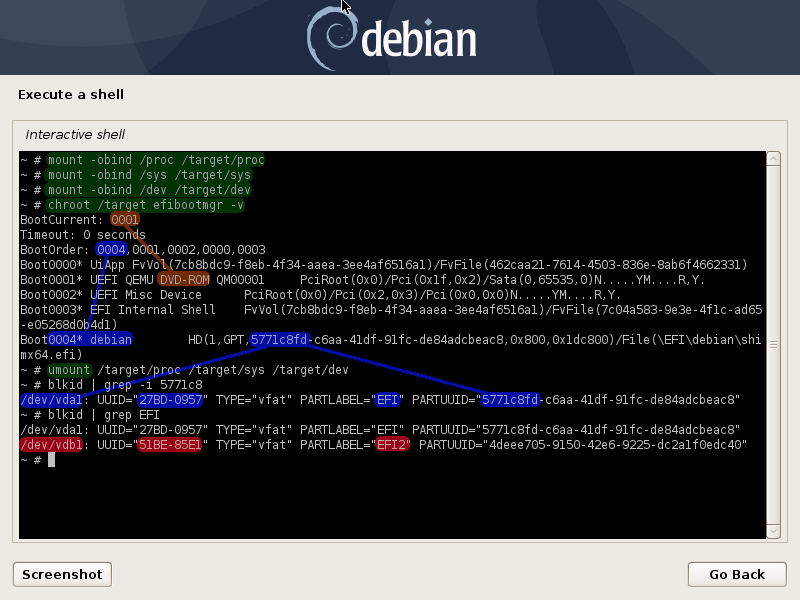
NOTE: Before commands above- if not fully booted normaly with one efi partition, you likely need to temporarily bind mount proc+sys+dev of the install environment over their respective /target/{proc,sys,dev} locations before chroot; then efibootmgr -v from chroot should also report actual entries seen from system nvram.
NOTE: if the installer already has a working efi fs created for you then using dd as RBE suggested is one good option for copying it and keeping the same vfat side uuid (helps to have one fstab entry for /boot/efi). If it’s already created and booting, thegrub-install above would not be needed; but the bullet not below would still be needed.
After getting grub-efi content into an empty efi fs, the efi entry likely must also be added to the bios/nvram so it knows to try that one too (note that the GPT partition id are different after manual/separate partitioning during installation. An example of an efibootmgr command to add an entry is below (be sure to pick the efi partition with the GPT id that is not already in the nvram boot list. [[ TO BE ADDED ]]
Side note: One installer stage had a neat note about backup external media for efi, which I suggest/did skipping of; however, if it’s not “special” it might actually work to install both efi partition (unsure about efi nvram boot entry on bios side), but this should be tested and verified later.
This was the first issue. There was a motherboard option that had some description about Windows 8, that, when set to disabled, causes everything to boot up in UEFI mode. So when I ran the installer in UEFI mode (I believe the splash screen actually says “UEFI installer”), it didn’t ask me about boot loaders at all. I think the Debian installer works in either mode, but goes int MBR mode if you let the motherboard choose automatically.
The partitions are GPT. There is a UEFI partition on the beginning of each drive, that is not on RAID. There is a RAID base partition on each drive that becomes a RAID 1 array for /boot, and another RAID base partition on each drive that is a RAID 1 array, with LVM on top of it for everything else.
I’m unsure of if the installer installed to both UEFI partitions or not.
It may just be simpler to boot into rescue mode (if/when needed) and install UEFI on the other drive at that time, rather than tying to maintain two of them, especially if /boot is raided?
It may not have; or at least I don’t believe it did when I created two separate ones in the previous test. Though I used the ‘Expert gui’ install mode so I was picking specific items rather than waiting to be prompted, and I did not fill out the ‘external usb backup efi’ (or however it was called).
At the least, to check on the efi entries while booted (rescue or otherwise) the sudo efibootmgr -v command could be run to see if there are two entries related to debian and then see if the uuid matches anything in blkid output (and if two of them mach). And to mount the second efi partition that is not already mounted (somewhere else) and check it’s contents. (See links/notes below)
Yeah, trying to maintain both and know “a good approach was used” can be a small pain. I see @RBE updated with the thread discussing some of the options for syncing.
Based on what I saw of the grub.cfg in the EFI path, it was just a 3 line one that did not have any kernels(img), so at least in my test I wouldn’t need a dracut/mkinitcpio/kernel hook to do the sync upon kernels being installed necessarily (unless I’m forgetting something), but something at least for when grub was updated; or anything else we can think of that is in /boot/efi/EFI/ paths. (simplest to check all files in that path(img) to see if they are owned by what packages, or which may have install scriptlets or hooks that update them ever; I can’t speak with the certainty of experience to what debian does that modifies files in those paths over time, unfortunately).
The initial setup of the second efi partition (after the first clone/copy and adding the entry to the nvram so it can boot to it if needed), is more to be sure it at least works at that time, and it may continue to work for a while as long as the grub efi modules/etc all still work to read the boot partition’s grub.cfg and kernel/initramfs images (even if old). But it is also possible to just go into rescue at the time of issue (if there was no previously setup secondary efi partition and nvram entry for it) and set one up; it depends some on if you want it all to be a smooth failover on next reboot after disk issues and then if the syncing method choice if any (and mounting the correct one after booting so future updates end up sync’d to there) is worth the configuration or anything over looked, like the potential of systemd getting updates (changing behavior) and then starting to complain about duplicate EFI fs UUID if using that method(img) and not booting some time in the future even if both disks are still good at the moment and fail to boot, etc).
Oh, I see a second edit by @RBE adding some sync options-
I’m not sure if plain debian is using the archlinux efistub kernel method or not by default (but does have the ability to do that), it did not look like that to me, but I did use the ‘expert mode and chose the stages of the installer myself so I picked things and that may be different from default’ (partly why I documented some of the things observed). This is mostly regarding if syncing of the EFI fs is needed per kernel update or just per grub/bootloader update.
I did consider a symlink and double bind mounts and other things as there may be many approaches though I’m not sure if I like any of them more than just the duplicate UUID of the EFI partition in the /etc/fstab when using systemd, but some of what is in the archlinux doc can be useful here indeed. I don’t think I’ve seen an issue at the firmware/bios level with duplicate UUID, I think it just uses one of them that it finds first/etc in my past systems that I’d tested that on. Though the duplicate fs UUID (but different gpt partition uuid/label) only solves the need to mount whichever one it can find when both or only one is available, and not further syncing steps.
The “[[ TO BE ADDED ]]” parts from my earlier comment (in quick form as I considered taking all the screenshots from my debian install test (and command output showing/verifying content of files and success or initially required steps to get the second one working) and putting them together depending on if it was still an issue/question and status updates.
These are not as concise as some docs online but are not the “very verbose” version either.
(the “see below” is still in the original comment but the added part is here)
In the install environment’s shell (before or after install) (img-with-note)
~# lsmod | grep efi ##this one works before installing, or find UEFI on install screen
<after root OS volumes are mostly installed/all mounted at /target or similar in rescue>
~# mount -obind /proc /target/proc
~# mount -obind /sys/ /target/sys
~# mount -obind /dev /target/dev
~# chroot /target efibootmgr -v
(if checking on your booted system, no need for chroot/bind-mounts/LD_LIB*/etc)
(skiping the details of dd and or cp depending on what is chosen regarding uuid and syncing, the adding of an entry is something like below)
~# mount -obind /proc /target/proc
~# mount -obind /sys/ /target/sys
~# mount -obind /dev /target/dev
< preferably mount EFI partition to be added to nvram at `/boot/efi` >
~# chroot /target
root@debian:/# efibootmgr -v ##check for existing entries.
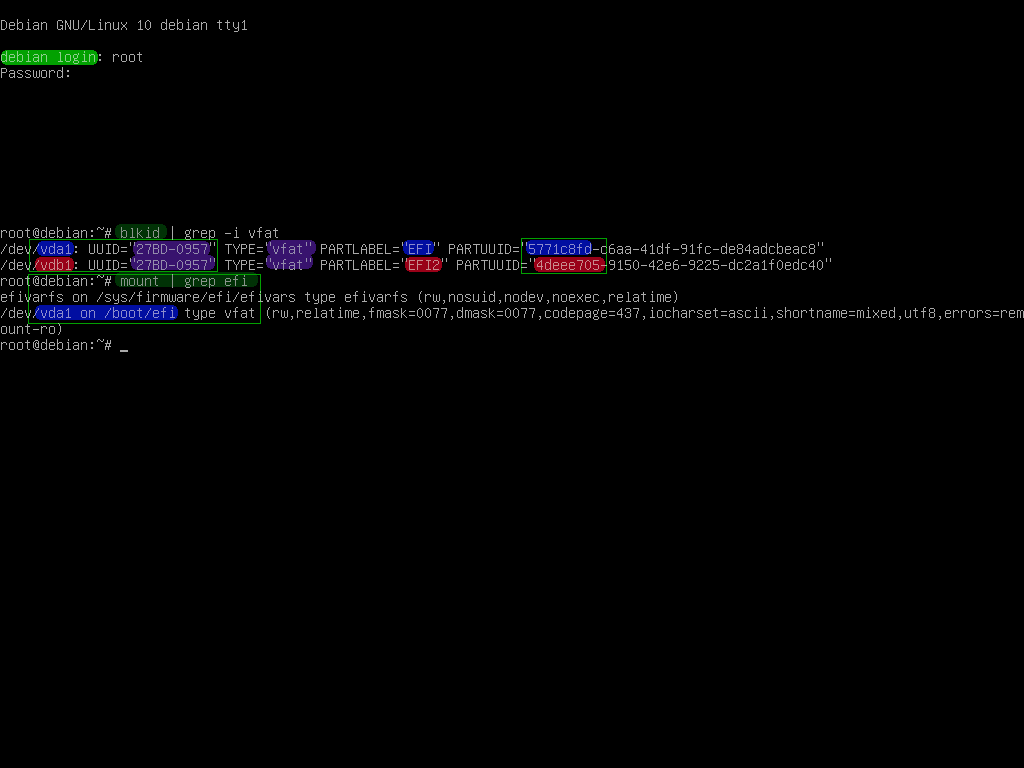
root@debian:/# blkid | grep vfat ## find EFI-fs non-matching PARTUUID
root@debian:/# efibootmgr -c -d /dev/Xda -p 1 -L \\EFI\\debian\\shimx64.efi -L 'debian efi mirror2' -v
< where `Xda` is your disk and `-p 1` is partition 1 (or your own) >
(an entry should appear and BootOrder: should show it’s ID in front as the default now; now hopefully there are two entries) (below-img-with-more-notes)
In my test case I eventually dd'd the content of the debian installed efi partition over to the secondary one so that the fs uuid matched, but left the GPT partition uuid and label as unique. (there can be some errors if you simply add two entries to /etc/fstab for /boot/efi as systemd will complain(img)…); Below(image-below-with-more-notes)
(EDIT: and for clarity, the above image/test that shows successful boot had UUID=27BD-0957 /boot/efi .... as the device specifier ie. first column in a single fstab line; that may be more clear from the additional notes on the imgur link or total album)
I did also try converting it to mdraid (with correct metadata version) and booting the VM which worked as expected, but then we have the other concerns about firmware/bios that may eventually edit the fs of one of the separate members that it happens to boot from.
All the screenshots from testing (including some errors that are unrelated that happened when trying to mess with it before fully completing the installation, using the Shell after packages+bootloader were installed) with all the extra notes and some examples of failures and successes. A bit too verbose but someone may find them informative by example. It is not a direct guide on steps needed, just working screenshots following my test/checking of things. Some sections may help clarify how to check (like I’ve shown further above) for efi entries and how to add one etc. Those notes do not address any of the syncing side of the issue.
There may be several approaches to syncing if that is desired, it just depends on what you think feels “ok” and that won’t possibly introduce failure to boot in the future (regarding mounting of both disks or just any one available when one is gone) even if a disk has not gone bad yet. (Like if systemd later errors our after updates when two disks have same uuid; however, that can be common with lvm on raid etc so it may not be something I’d expect, but is a possibility that I can use as an example of ‘potential’ concern).
(EDIT: small change to remove extra /dev on /target/dev of the typed out non-photo chroot command further above, that got there due to copy paste error; though that was probably obvious upon error/seeing it)
I’m sorry I haven’t the time at the moment to work through your long post, but you seem to touch on (what I’ve been told is) a bug in grub (at least the version I have in Ubuntu 20.04) where grubx64.efi, which makes it always use EFI/ubuntu/grub.cfg, even if booted from, say EFI/mine/grubx64.efi. I’ve been pointed at this old blog post (which I haven’t had time to read), that mentions some undocumented options to grub-install:
Ah. I think a few things ended up getting crossed in communications. I can blame my longer post for part of that (and inclusion of the odd events I observed during my testing). I’ll need to read the blog post once again more closely later, but I wanted to respond sooner in-case you end up spending more time looking over it later before I return.
Assuming this is directed towards my post/self -
Several things noted in the blog post look very similar to part of what I was doing/observing in attempt to install debian to reproduce an environment like lightnb’s scenario / desired-scenario.
Though, my intention was just:
to confirm how the installer behaved and the state the debian installer leaves it’s grub.cfg / grub64.efi for booting.
provide steps on how to add EFI grub to the second efi partition that did -not- have anything installed to it (one disk has it and boots ok, but the other disk did not in my case, and I suspect also in lightnb’s case; I actually expect this behavior from the installer as it has no option to do it to both disks; just the odd “backup removable media efi”).
and to do this in a way where if either disk is pulled that a reboot will result in a successful boot.
ie. to have two disks, one raided OS, and two separate efi partition (one per disk)(and intended just two NVRAM efi boot entries one per efi partition)
On my quick reading over the blog, it has a bunch of good details. However from what I read along with the final comment on it:
Update (2015-12-11):
There is an interesting discussion about the whole topic in the Kubuntu forums. Apparently, it should also be possible to use multiple EFI partitions to get multiple instances of Ubuntu working with secure boot. Thanks for that idea, and sorry for being unreachable. I will probably have to add my mail address here sometime. In the meantime, you can try “me” at …
The bold part is what I had set out to show could be accomplished but not multiple Ubuntu installs. Quick reading over the blog suggests issues with multiple ubuntu installs sharing the same single efi partition. | (In lightnb’s desired scenario it would be two disks each with one uefi partition; else still two disks but also software raiding the efi partition, which I had recommended against due to potential for corruption due to efi firmware being unaware of software raid)
What you’ve linked to Is actually interesting and good to know and may apply more to the one other forum post/topic regarding having multiple installs of debian/ubuntu distros but only one disk. The one about PopOS+Ubuntu on one disk, where I recommended having separate efi partition if possible spacewise (on the same disk) just to be sure there would be no concern. In fact what you linked to suggests there could indeed be a concern if only one efi partition was used, depending on their folder structure between the two/more distros sharing an efi partition.
Continuing side comment from above
Though if the main grub.cfg was then told to point towards loading other sub grub.cfg one per OS /boot then it would not be a concern (for the user with one disk), though possibly with secure boot it would need to be verified just to be sure. But the one main grub efi would load at least, then past that it would be that all kernels it could load from sub grub.cfg would be ok (not so sure about passoff from one efi executable to another instance of grub efi (in secure boot), like with systemd’s bootmanager though I assume they might have taken care of that).
My last longer post documented some of that process in the screenshots, and also noted an odd behavior which I suspected was due to my own tinkering in the middle/end of the install. I had thought that the disappearing boot entry in the efi firmware NVRAM was my own fault or a conflict with what I did and the installer eventually completed with, or a quirk of the qemu-kvm efi firmware. My intention was not to investigate that so much as show how lightnb could add a second EFI firmware entry pointing at the second EFI partition (not specifically to add two entries that pointed to a single efi partition containing two different efi paths/OS installs. (doing so either using rescue mode live-cd or from the currently booted system)
My intention was just one efi partition per disk and each efi partition was to point to the raid device or (fs uuid that would be the same for both mirrored/bootif it was broken) (and or it’s specific disk); where I had not considered or tried in this thread to add two grub.cfg/efi install per partition to try and make it so that if one disk was partially failed but the efi partition was ok that it could point at the other disk without failing due to partialy working scenario (ie. not four efi entries in the nvram boot list, just two). (It is correct that if EFI fs on DiskA is bad and OS on DiskB is bad that if you removed one disk then you’d still have problems (corruption vs full disk failure, I had not intended to deal with that scenario; and let software raid sort out which to use and if it could not then intervention would be needed).
Side tracking in the image album/longer post
In the process of confirming the steps, I messed with the install via the Installer’s Shell, to check on it and possibly to add the second EFI partition before rebooting. This is where I ran into some oddness but would need to repeat it to be sure it was not some oversight on my part; the two odd things that happened for me and only due to my use of the Shell to run commands:
Hanging of the grub-mkconfig command on vfs_write/Vfs_read (I forget but is in the image album). I’m pretty sure this is partly my fault.
That the efi boot entry in NVRAM for the main os “disappeared” by the time I logged in at the first boot into the OS. Before completing install, there was one there by the installer competing it’s grub-install stage, i went to the Shell and installed second one to the second partition, then added an efi entry in NVRAM for it, saw there were two entries as expected and that I had setup the second one, unmounted what I had done and left it in what I thought was the state the installer left it in, then told the debian installer to complete the final stages of installation; to find that I only had one debian entry in the NVRAM after loging in. (where the blog post I think is talking about loosing a previously installed os’s efi binary due to the overlapping paths (and possibly it’s NVRAM entry) where the grub64.efi has a hard coded path for the cfg, and thus signed and could not be modified in the efi binary after the fact and allow secureboot.)
I wouldn’t investigate these until I reproduce any of that cleanly or clearly
Regardless of if the blog matches anything after closer review of the blog post later, I do really appreciate having the chance to read over it and realize what I think it’s suggesting about multiple ubuntu sharing a single efi partition. I’ll be sure to read it closer to check on the extra flags etc. In the far past I’ve rebuilt the grub-efi package to modify the modules inside the efi grub/supporting-binaries which of course required pesign at some point in the rpm build (fedora) which I do not have trusted keys for without adding them to the firmware/mok db myself, and can understand if the cfg path is hard coded (it certainly is) there would be a problem and not easy to just move aside. I had not considered it before though usually I have not dual booted or had separate disks or considered having multiple efi partition just to be cleaner about it.
To reiterate how close that blog post is regarding things I looked at; an example:
Finally, there is a grub.cfg configuration file which contains a pointer (both as a disk UUID and as a GPT number) to the “regular” grub boot disk, which is usually your Linux root partition (or a separate boot partition if you are using an encrypted root device).
Many parts of the blog post are things I also discovered about how ubuntu/debian does this in comparison to fedora/centos so all of it would be things I was originally looking for; in that sense it is very applicable
Also, certainly if secure boot is enabled and if the kernel is no longer signed by the same trusted public keys then grub (within the efi partition) would need to be updated along side that kernel if it was expected to boot. (Ie the older non-synced efi partition could then be a problem.) I’ve not actually looked into the checking of the kernel image in the past (likely the .hmac), only how driver keys are passed along to the kernel keyrings after enrollment via mok (comparing vanilla mainline vs centos). It may be a consideration if not syncing and later hoping that the older efi partition could boot without intervention. I would suspect that that side does not change often, though.
Finding myself in the same position as the OP, I set up a test PC and went though the comprehensive notes and screenshots provided by @spiders in their all the extra notes link.
The TL;DR is this:
During OS install, keep your ESPs outside of RAID
After installation, determine which ESP was used (the one mounted at /boot/efi)
Duplicate the content of this “first” ESP to the “other” ESPs using dd
Add entries to UEFI NVRAM using efibootmgr for the “other” ESPs
Sync the ESPs whenever the content of “first” one is changed
That’s pretty much it. Note that it is critical that you use dd to copy the ESPs the first time and not rsync etc. This is because the UUID of the partitions must be identical otherwise mounting the partition will fail. After the initial duplication you can sync the partitions using rsync or continue to use dd.
Note that if you have a LUKS partition sitting on top of your RAID array, there is a gotcha that you need to be aware of. Consider the paritioning scheme used by the test PC for example:
If a disk in the RAID array fails, it is important that you mark the corresponding parititions (/boot and /) as failed using mdadm before powering off the machine and pulling the disk. Do not simply power off the machine and pull the disk, as it will fail to boot.
EDIT 1
Post modified to reflect findings viz failing disks using mdadm prior to powering off PC.
EDIT 2
I have placed the Bash script that I use to sync my ESP partitions as mentioned above up on GitLab in the hope that others in the same situation as the OP find it useful. If you find any problems with it, or have any questions, please let me know.
That’s weird - I have not changed anything since I first uploaded it, and I can still access it here. I don’t think link capitalisation makes a difference, but please try the aforementioned link and let me know how you get on.