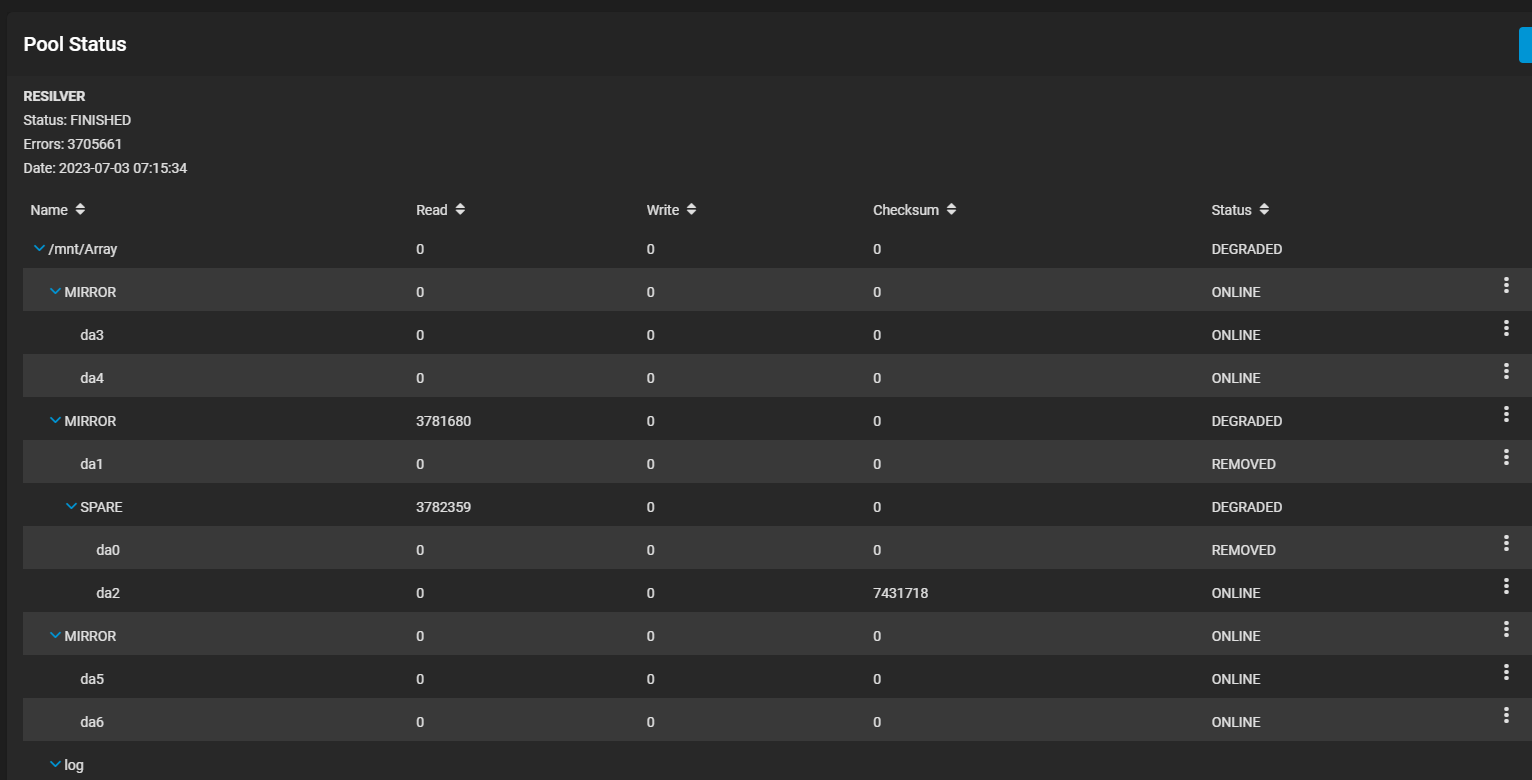
Some time this morning around 0715 EDT my TrueNAS ejected 2 drives in the same mirrored vdev. The failure seemed to be one drive kicked, ZFS tried to bring in the hot spare, and then the other drive kicked. This 4 hours and about 4 million errors later the TrueNAS motified me that there was an issue after the resilver failed.
Given how these passed their weekly smart test and scrubs a little over a week ago, I find it hard to believe that both drives totally died at the same time this morning. It seems exceptionally unlucky. I’m suspecting some kind of hardware issue, I think with the SAS card. Both these drives, and the spare actually, share a common connector channel on the SAS card. I have a backup to restore from if it comes to that, it’s an older backup but it checks out.
So really, I’m fine I guess, but what should I do now? How do I troubleshoot this situation? The server is on and up, and there’s a lot of metadata still cached in the main memory. How do I check if my pool is still there?
Maybe someone can answer my most pressing question? Is there anything I should do before I shut down this machine to check the hardware over?
I certainly had my share of NAS issues due to faulty cables or flaky backplanes; those are not fun to diagnose.
You can take one (or both) of the ejected drives, connect to another machine and read the SMART data off of it. That will give you additional datapoints, and help diagnose connection issues rather than internal failure or otherwise.
I did a short SMART test and found no errors. I decided to try onlining one of the removed disks. I onlined da1, it resilvered immediately (only took a minute) and brought da0 online too AND moved da2 back to spare. That was real weird. It still says there’s data corruption, but I’m running a scrub now and it’s not throwing a bunch of errors. We’ll see what happens in 2 hours when it’s done. I’m so confused.
Aside from tests you also may want to dig in to SMART attributes. A bad cable/backplane would likely cause thr attribute 199 (UltraDMA CRC Error Count) to go up.
1 Like
All zero on attribute 199. The scrub is done now and reported no errors. There were 10 repairable checksum errors on one drive, but everything is good now. I am very confused as to what happened that caused this all.
This happened again, I suspect there’s an issue with the SAS HBA. I’ve removed it for now for further troubleshooting, but I wasn’t as lucky as last time and I have some data corruption. The trouble is while I have been replicated to a remote mirror, I have no idea how to restore. I clicked the restore button under my replication task and it doesn’t seem to actually do anything. Help?