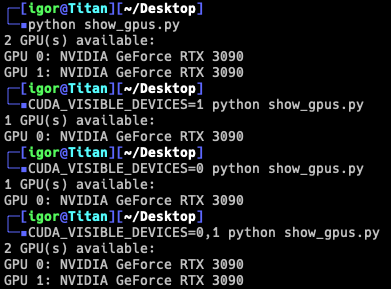
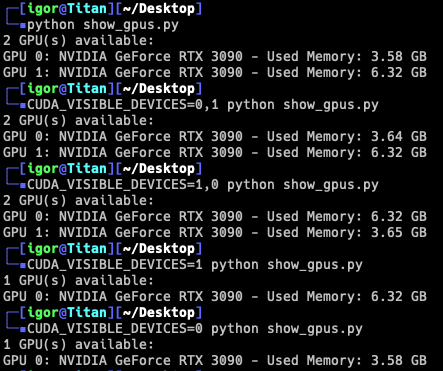
Update: CUDA_VISIBLE_DEVICES works fine, just not with Ollama (even though it should). As far as I can tell, this is only an issue with Ollama, bug report filed.
The context:
I’m building a AI rig for my homelab, running 2x3090s and 1x3090Ti on a Gigabyte X570 Aorus Master and a Ryzen 5700X, with a single 4TB nvme drive.
I’m running Ubuntu Server 24.04 LTS, with nvidia-driver-570-server, CUDA toolkit 12.8 installed.
- The 3090Ti (pcie 0000:09:00.0) is in the primary x16 PCIe slot, running at x8 Gen4, on a 10cm Gen4 riser cable
- One 3090 (pcie 0000:0a:00.0) is in the secondary x16 PCIe slot, running at x8 Gen4, on a 10cm Gen4 riser cable
- One 3090 ( pcie 0000:04:00.0) is in the tertiary x16slot, running at “x4” Gen4 from the Chipset (dmesg | grep -i pcie returned only x2 link for the card), on a 20cm Gen4 riser cable
Since I’m using every single lane, I reduced the unused PCIe devices as much as possible:
-
- physically removed the WiFi/BT add in card under the IO shield
-
- deactivated 1Gbit Ethernet port (using the 2.5Gbit only)
-
- deactivated Audio, SATA
My problem:
Checking with nvidia-smi, it shows the “slowest” GPU, the 3090 connected to the Chipset, as GPU0.
This introduces performance issues for me, especially in applications that can only utilize 1 GPU, as they often default to GPU0.
My understanding is that the PCIe device order is assigned at boot, depending on what card is detected first on the bus by the BIOS, and that order is then used to enumerate the GPUs.
I’ve combed through the BIOS, but could not find any way to force a specific order, and tried some settings (e.g. presence detect mode → AND) that could potentially impact detection order, but none of them produced any change.
I’ve also tried setting the environmental variables for the CUDA toolkit to specific device orders and device listings, no luck. Every application that uses CUDA and only 1 GPU, always seems to select the 3090 on the chipset slot, instead of the 3090Ti on the primary slot.
Does anyone know what might be going on here and if that is fixable? Or are there any workarounds at least for CUDA?
My suspicion is that the PCIe x4 special uplink lanes that the chipset is connected to get preferential treatment in boot order, and the Chipset (and connected peripherals) are then detected earlier than PCIe devices connected to regular PCIe lanes.
Also, let me know if this is not the right forum category for this topic. I just picked the place I thought would most likely be frequented by folks that might have dealt with similar issues building DIY AI rigs.
Below the complete results of sudo dmesg | grep -i pcie, in case that helps:
[ 2.413267] acpi PNP0A08:00: _OSC: OS now controls [PCIeHotplug SHPCHotplug PME AER PCIeCapability LTR DPC]
[ 2.414373] pci 0000:00:01.1: [1022:1483] type 01 class 0x060400 PCIe Root Port
[ 2.414682] pci 0000:00:01.2: [1022:1483] type 01 class 0x060400 PCIe Root Port
[ 2.415218] pci 0000:00:03.1: [1022:1483] type 01 class 0x060400 PCIe Root Port
[ 2.416186] pci 0000:00:03.2: [1022:1483] type 01 class 0x060400 PCIe Root Port
[ 2.416794] pci 0000:00:07.1: [1022:1484] type 01 class 0x060400 PCIe Root Port
[ 2.417196] pci 0000:00:08.1: [1022:1484] type 01 class 0x060400 PCIe Root Port
[ 2.418311] pci 0000:01:00.0: [1d97:1602] type 00 class 0x010802 PCIe Endpoint
[ 2.418825] pci 0000:02:00.0: [1022:57ad] type 01 class 0x060400 PCIe Switch Upstream Port
[ 2.419190] pci 0000:02:00.0: 31.506 Gb/s available PCIe bandwidth, limited by 16.0 GT/s PCIe x2 link at 0000:00:01.2 (capable of 126.024 Gb/s with 16.0 GT/s PC Ie x8 link)
[ 2.419770] pci 0000:03:02.0: [1022:57a3] type 01 class 0x060400 PCIe Switch Downstream Port
[ 2.420797] pci 0000:03:05.0: [1022:57a3] type 01 class 0x060400 PCIe Switch Downstream Port
[ 2.421801] pci 0000:03:08.0: [1022:57a4] type 01 class 0x060400 PCIe Switch Downstream Port
[ 2.422448] pci 0000:03:09.0: [1022:57a4] type 01 class 0x060400 PCIe Switch Downstream Port
[ 2.423075] pci 0000:03:0a.0: [1022:57a4] type 01 class 0x060400 PCIe Switch Downstream Port
[ 2.423827] pci 0000:04:00.0: [10de:2204] type 00 class 0x030000 PCIe Legacy Endpoint
[ 2.424314] pci 0000:04:00.0: 31.506 Gb/s available PCIe bandwidth, limited by 16.0 GT/s PCIe x2 link at 0000:00:01.2 (capable of 252.048 Gb/s with 16.0 GT/s PC Ie x16 link)
[ 2.424543] pci 0000:04:00.1: [10de:1aef] type 00 class 0x040300 PCIe Endpoint
[ 2.425069] pci 0000:05:00.0: [10ec:8125] type 00 class 0x020000 PCIe Endpoint
[ 2.426192] pci 0000:06:00.0: [1022:1485] type 00 class 0x130000 PCIe Endpoint
[ 2.426508] pci 0000:06:00.0: 31.506 Gb/s available PCIe bandwidth, limited by 16.0 GT/s PCIe x2 link at 0000:00:01.2 (capable of 252.048 Gb/s with 16.0 GT/s PC Ie x16 link)
[ 2.426753] pci 0000:06:00.1: [1022:149c] type 00 class 0x0c0330 PCIe Endpoint
[ 2.428861] pci 0000:06:00.3: [1022:149c] type 00 class 0x0c0330 PCIe Endpoint
[ 2.429406] pci 0000:07:00.0: [1022:7901] type 00 class 0x010601 PCIe Endpoint
[ 2.429782] pci 0000:07:00.0: 31.506 Gb/s available PCIe bandwidth, limited by 16.0 GT/s PCIe x2 link at 0000:00:01.2 (capable of 252.048 Gb/s with 16.0 GT/s PC Ie x16 link)
[ 2.430042] pci 0000:08:00.0: [1022:7901] type 00 class 0x010601 PCIe Endpoint
[ 2.430414] pci 0000:08:00.0: 31.506 Gb/s available PCIe bandwidth, limited by 16.0 GT/s PCIe x2 link at 0000:00:01.2 (capable of 252.048 Gb/s with 16.0 GT/s PC Ie x16 link)
[ 2.430688] pci 0000:09:00.0: [10de:2203] type 00 class 0x030000 PCIe Legacy Endpoint
[ 2.430973] pci 0000:09:00.0: 126.024 Gb/s available PCIe bandwidth, limited by 16.0 GT/s PCIe x8 link at 0000:00:03.1 (capable of 252.048 Gb/s with 16.0 GT/s P CIe x16 link)
[ 2.431130] pci 0000:09:00.1: [10de:1aef] type 00 class 0x040300 PCIe Endpoint
[ 2.431448] pci 0000:0a:00.0: [10de:2204] type 00 class 0x030000 PCIe Legacy Endpoint
[ 2.431730] pci 0000:0a:00.0: 126.024 Gb/s available PCIe bandwidth, limited by 16.0 GT/s PCIe x8 link at 0000:00:03.2 (capable of 252.048 Gb/s with 16.0 GT/s P CIe x16 link)
[ 2.431861] pci 0000:0a:00.1: [10de:1aef] type 00 class 0x040300 PCIe Endpoint
[ 2.432155] pci 0000:0b:00.0: [1022:148a] type 00 class 0x130000 PCIe Endpoint
[ 2.432544] pci 0000:0c:00.0: [1022:1485] type 00 class 0x130000 PCIe Endpoint
[ 2.432860] pci 0000:0c:00.1: [1022:1486] type 00 class 0x108000 PCIe Endpoint
[ 2.433133] pci 0000:0c:00.3: [1022:149c] type 00 class 0x0c0330 PCIe Endpoint
[ 2.486532] pcieport 0000:00:01.1: PME: Signaling with IRQ 28
[ 2.486694] pcieport 0000:00:01.2: PME: Signaling with IRQ 29
[ 2.486859] pcieport 0000:00:03.1: PME: Signaling with IRQ 30
[ 2.487016] pcieport 0000:00:03.2: PME: Signaling with IRQ 31
[ 2.487263] pcieport 0000:00:07.1: PME: Signaling with IRQ 33
[ 2.487323] pcieport 0000:00:07.1: AER: enabled with IRQ 33
[ 2.487475] pcieport 0000:00:08.1: PME: Signaling with IRQ 34
[ 2.487542] pcieport 0000:00:08.1: AER: enabled with IRQ 34