Hi everyone, I just built a new threadripper system on the asrock x399m taichi. I recently added M.2 raid after seeing deb8urs build and some stuff from wendel on the youtube. I used the asrock addon m.2 x4 card to hold 3 512 970 pro m.2 drive and put another 3 on the motherboard. Its been interesting to do but I am still scratching my head on a few things.
First I could only get the array working as a boot drive using the 3.32 beta uefi bios. Once that was installed I set the MB to level 3 proformance enchanment and -.375 adaptive vcore and configured raid 0 on the six drive array. I then did a fresh install of windows 10 pro with the latest amd raid drivers. after windows was loaded and updated I got the latest platform drivers from AMD and it was off to the races to do some atto bechmarks. I also turned on memory interleving(Numa).
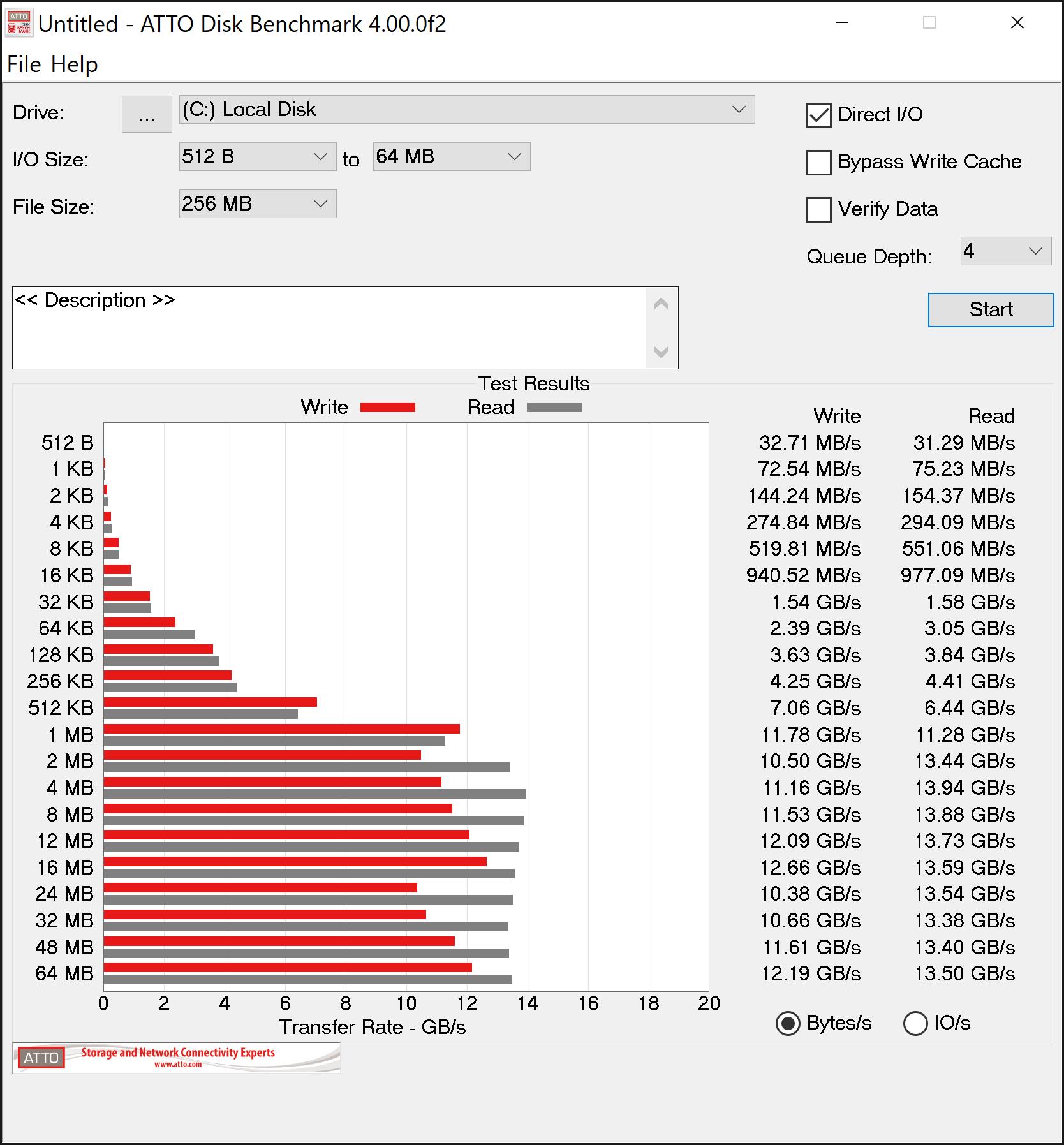
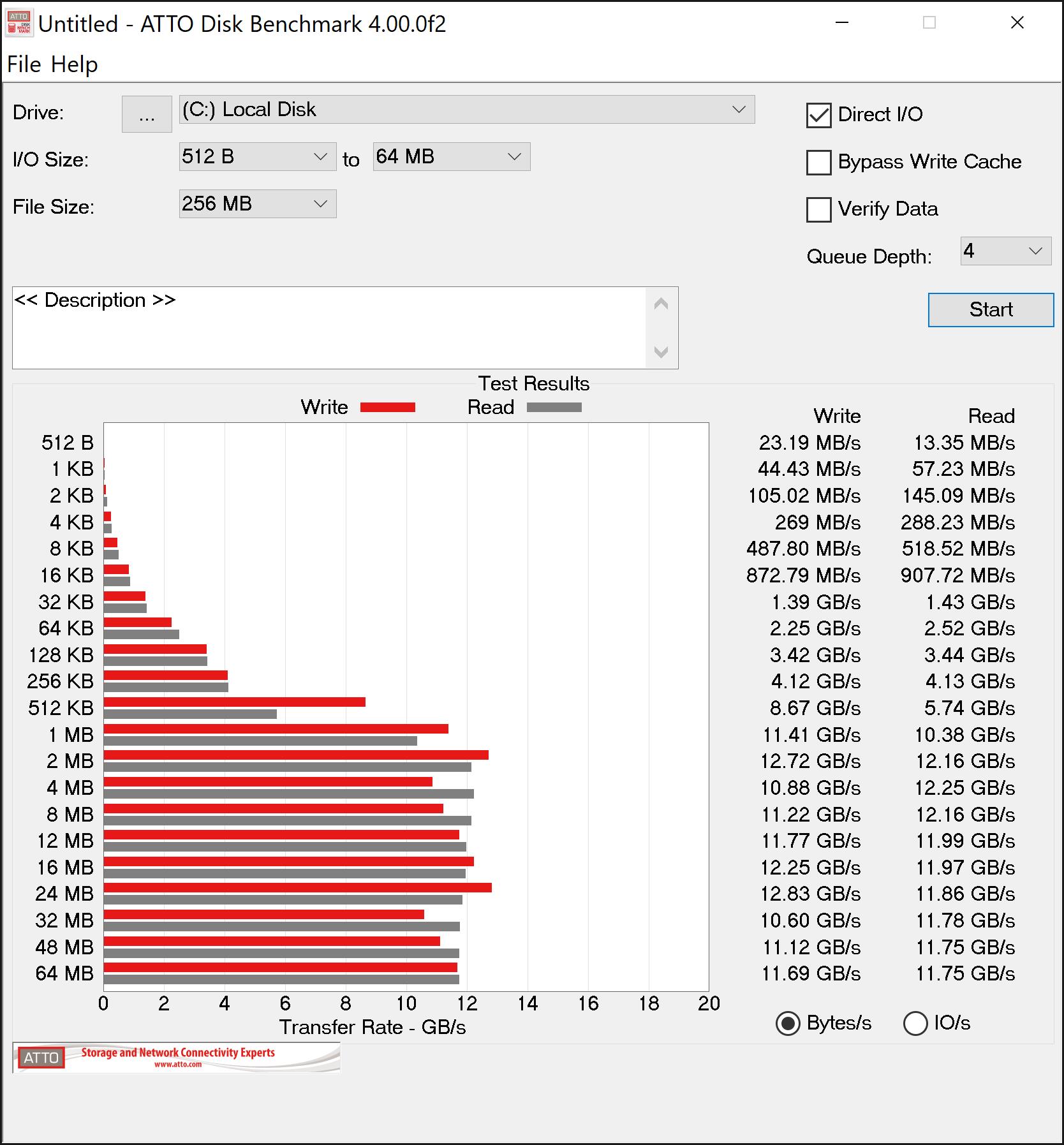
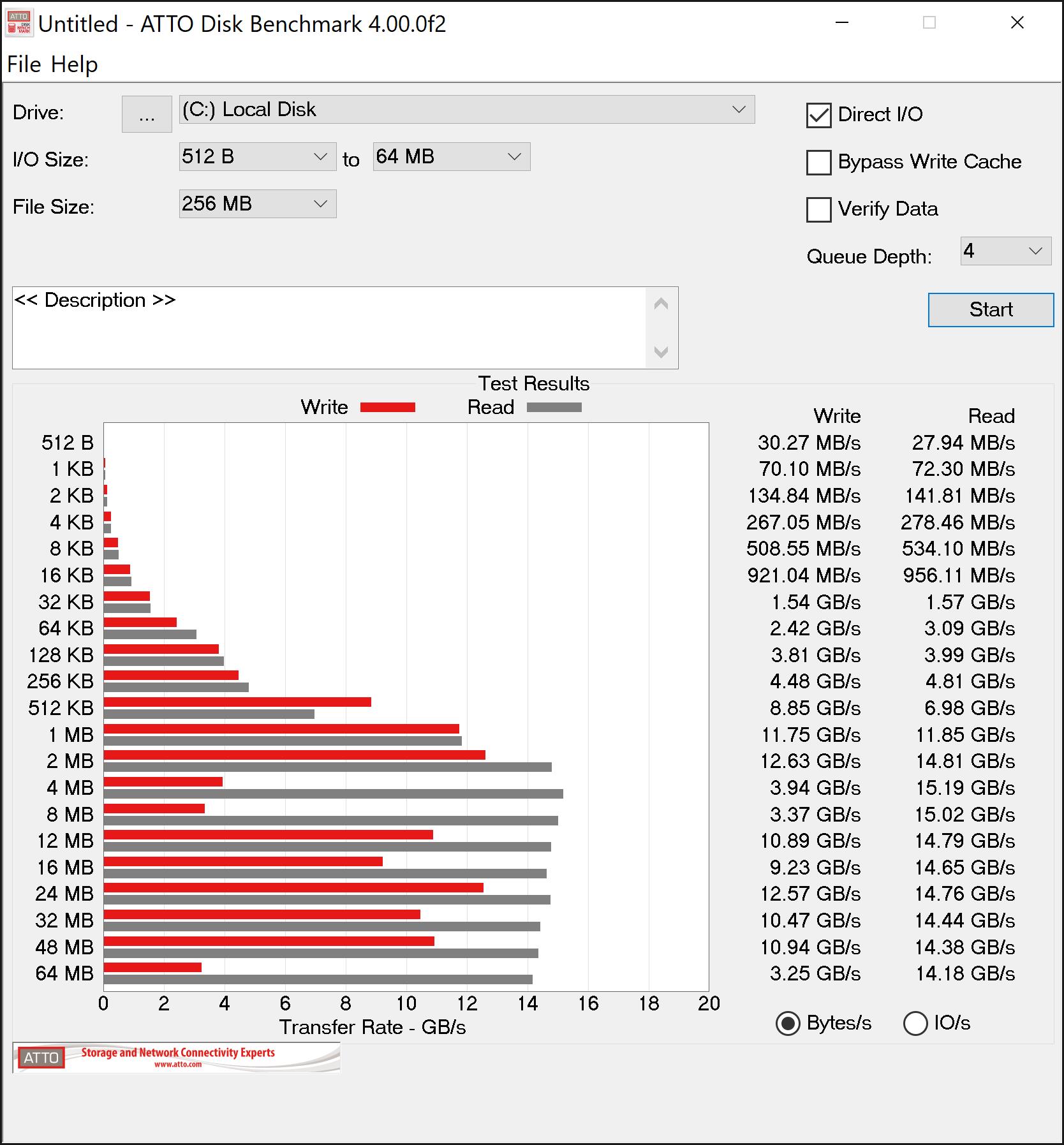
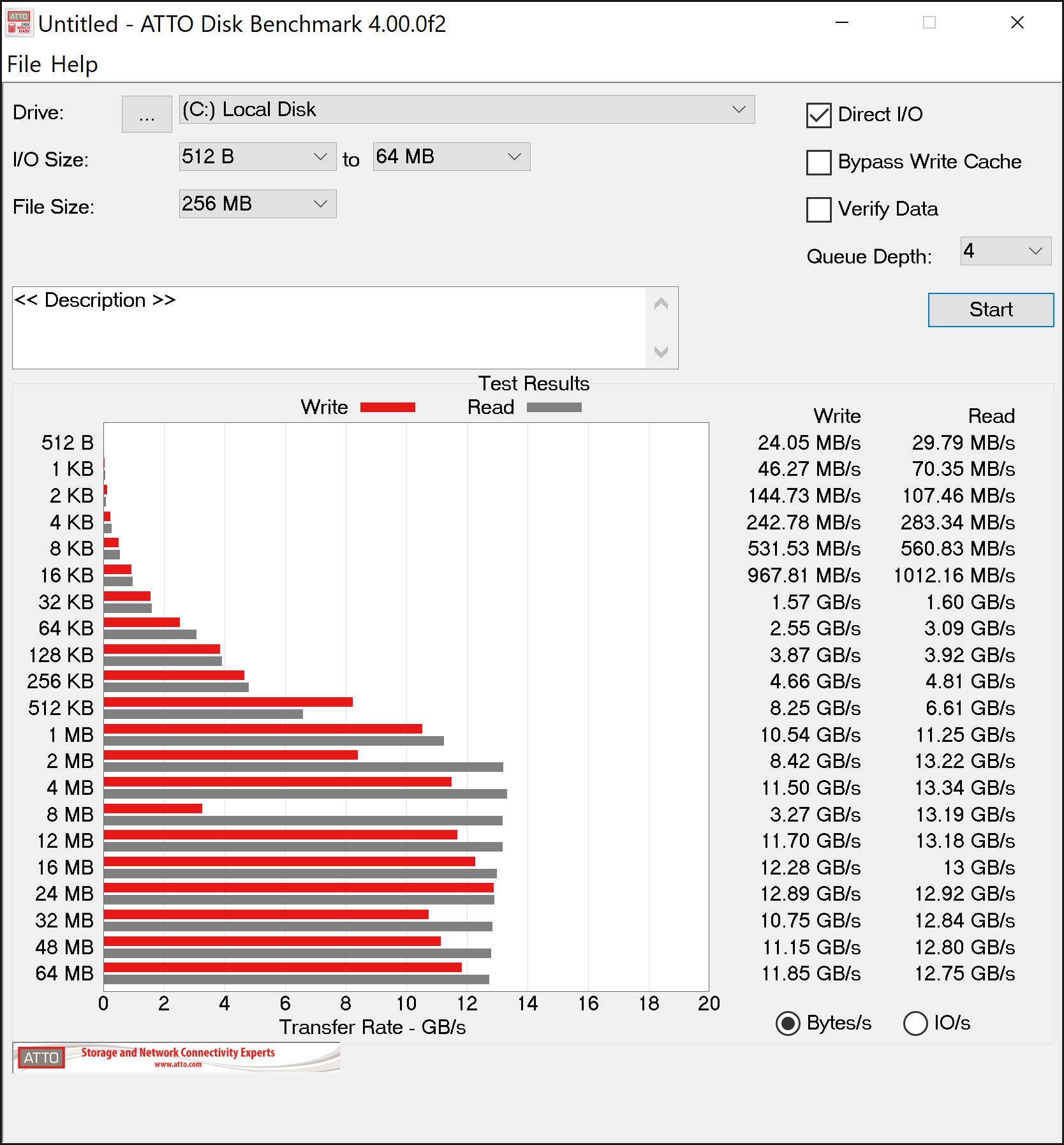
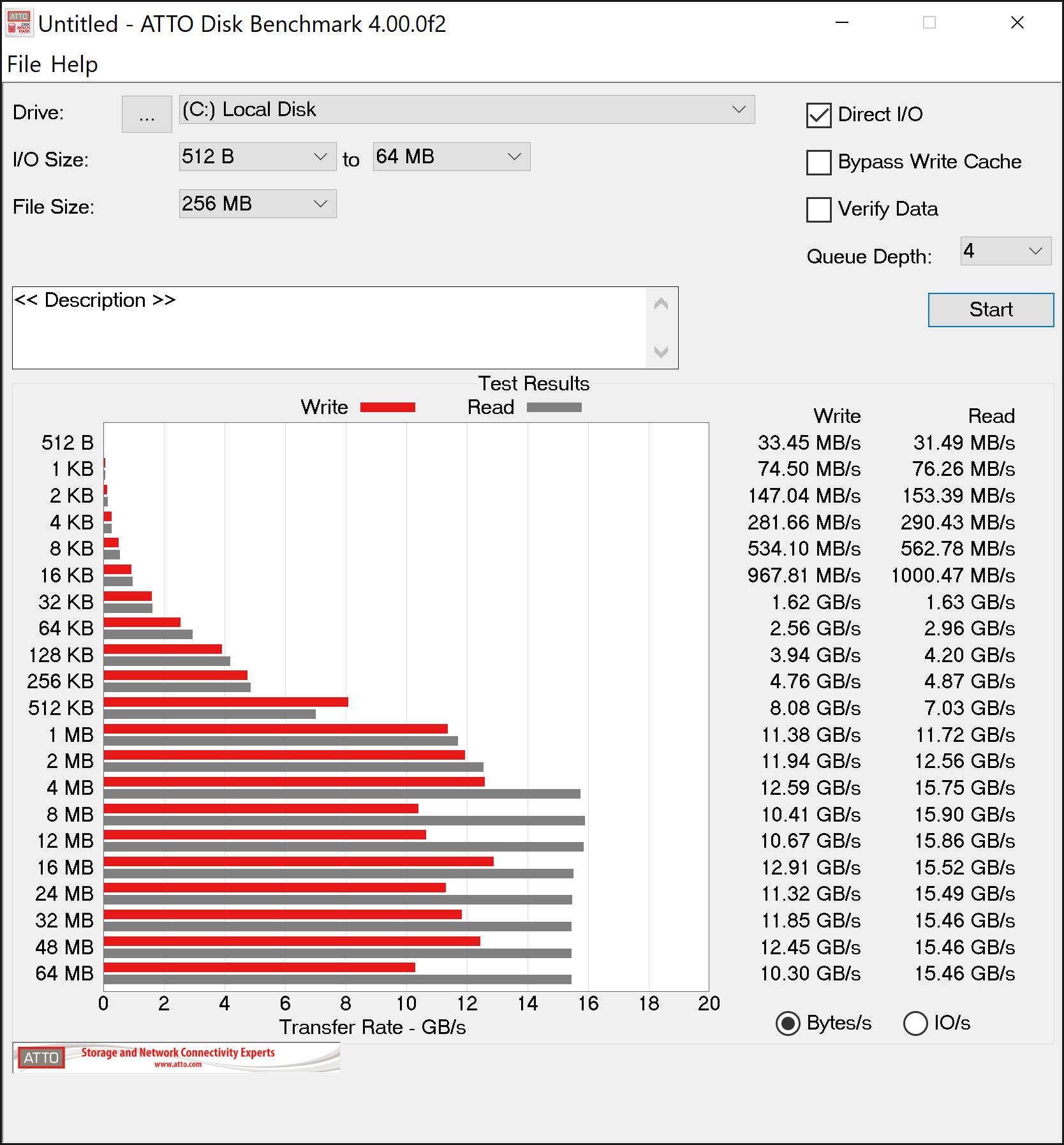
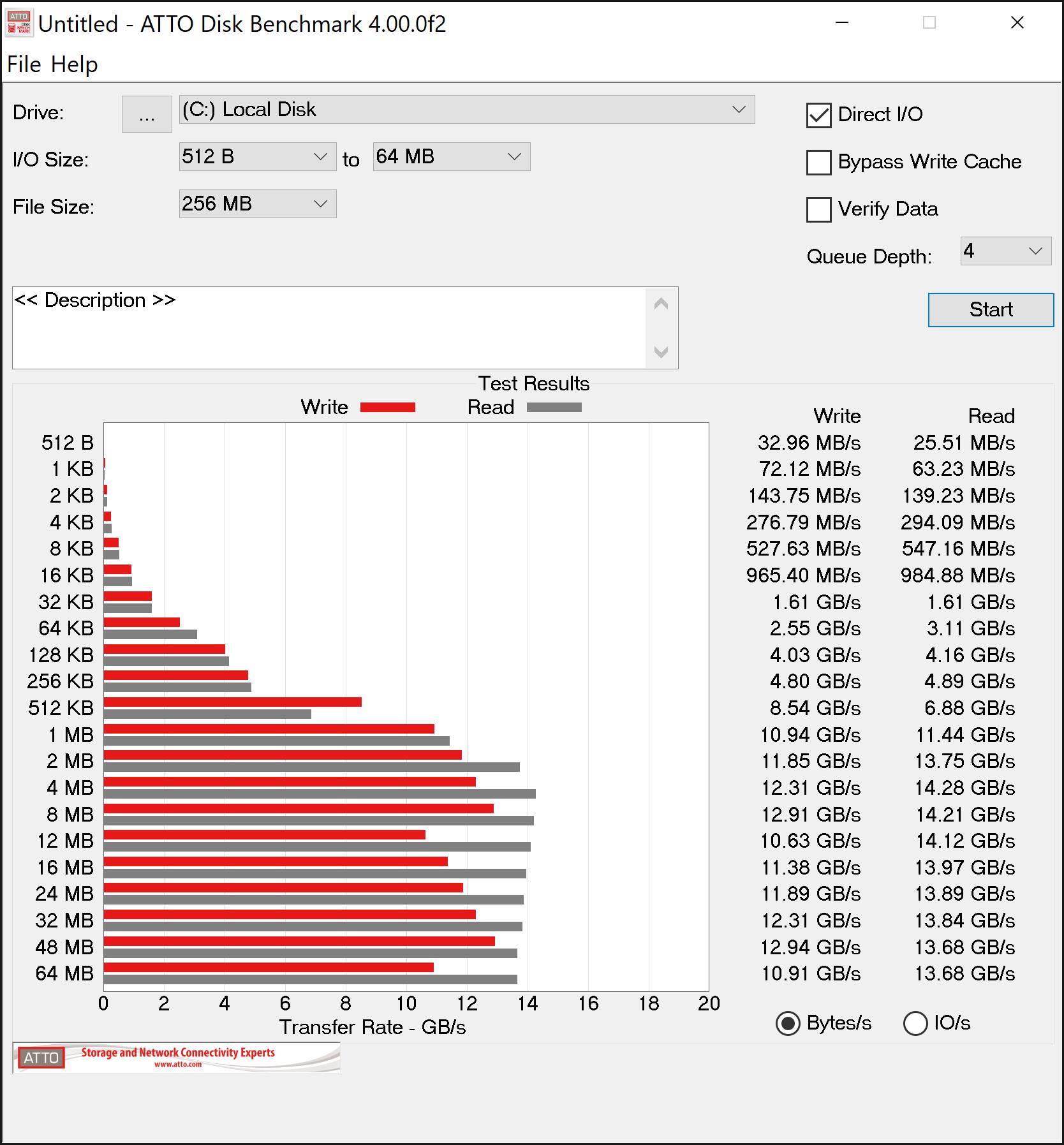
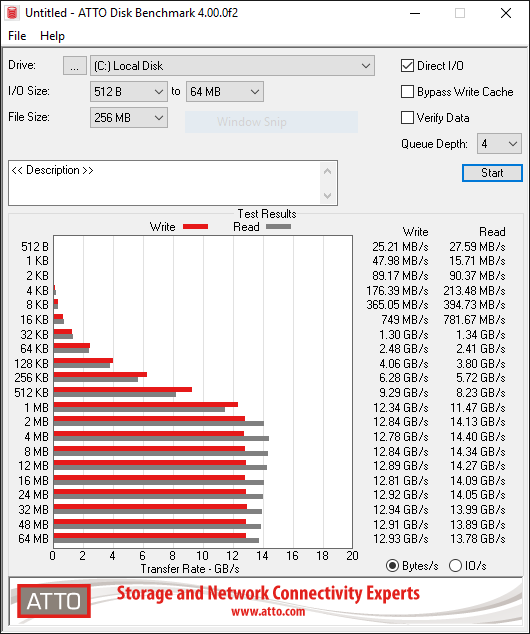
This is where it gets interesting. Deb8ur was getting like 27GB/s read speed on his 8 drive array which makes sense as 8 drives times 3.5 is a theoretical maximum of 28gb/s. On my six drive array I was only getting about 16GB/s well short of the 21GB/s thoretical maximum.
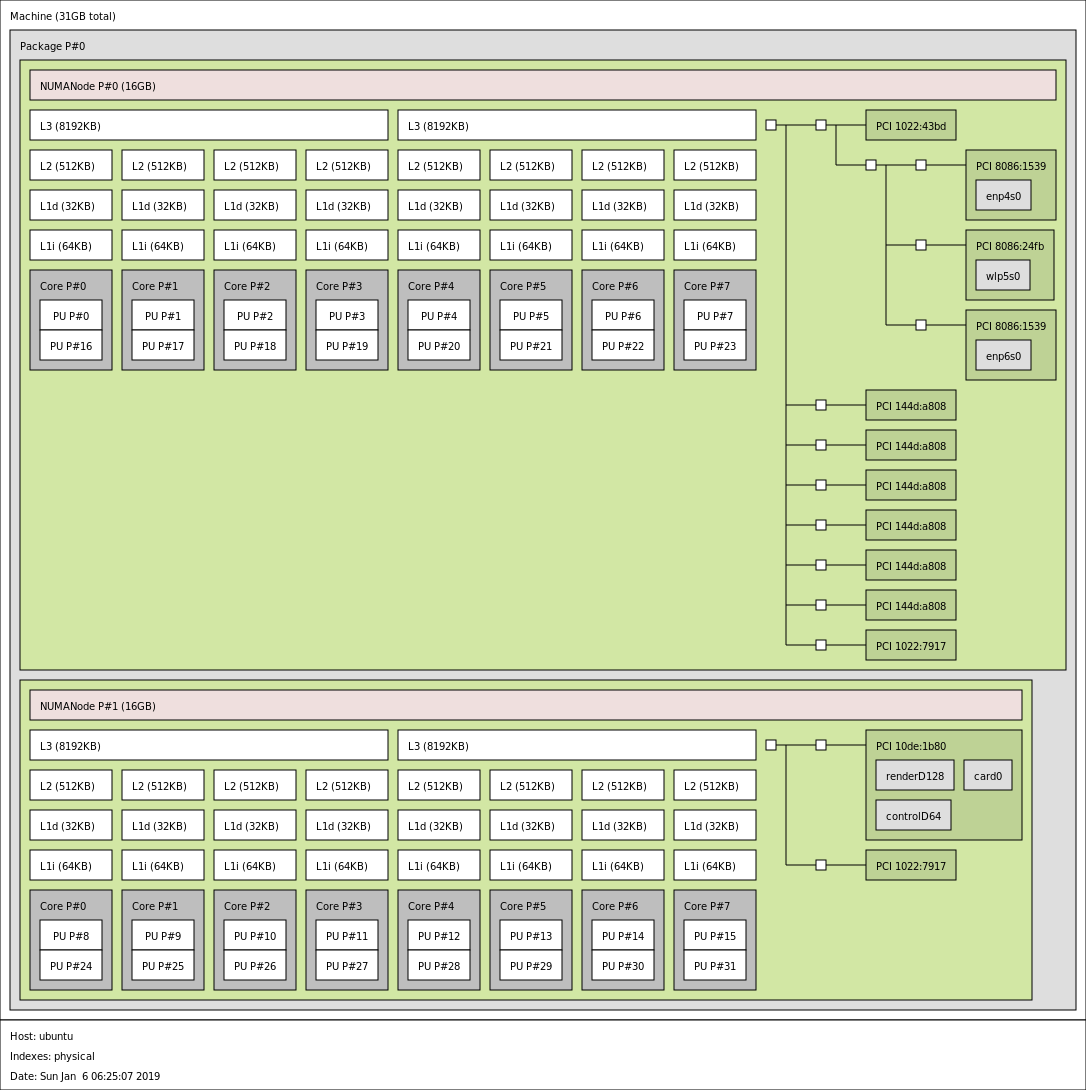
The fist thing I thought was ballancing the array accross the 2 numa nodes of the 2950x so I installed umbuntu and ran lstopo…I disovered that all the drives were on the same node…No worries…I switched things around between my graphics card and m.2 card and presto…3 drives on each of the numa nodes…I went back into windows and ran atto again…now with drives ballaenced arross the numa nodes I am only getting 14GB/s reads…Not sure what to make of that because everyone says they need to be split accross the nodes for best proformance but the result were repetable even after several switches and flipping between umbuntu and windows…Other than raid and o/c and numa everything in bios is default…The memory I am using is dd4 3200 14,14,14,36 running at the listed speed…I will continue to poke around but so far all my testing puts me well below what I have seen else where…its also weirs that the fastest speed is when all 6 drives are on the same numa node…
Please feel free to make any suggestions or to ask any questions as I would love to figure out what might be keeping this raid from reaching its true potential.
It may also be worth noting that I have a small case but I am using ek heatsinks on all the m.2 drives and while I have a small form factor case I have 2 140mm intake fans on the front and two more 140 intake fans on the bottom and two 140 at the top exhausting airflow. The temps seem great on all the testing I have done before the heat sink and extra fans I was never throttling. I haven’t tested after but not sure how to read temps in the raid. The oc also was extensively tested for hours with asus realbench and everything is rock solid stable. ….I suspect its the state of the drivers and beta bios but maybe I am overlooking a setting or two in the bios that can resolve the performance issues…Its super fast but truthfully I like to make things work to their full potential and I like to geek out on this kind of stuff as I find it super interesting.
“My raid only reads 14GBs max” #FirstWorldProblems#HumbleBrag
I may be way off base but it sounds like your bus speed may be your limiting factor (16GB). What speed does your bus run at?
As for loosing speed by splitting nodes this sounds like pipelining issues if it is cross platform then it’s probably in the way your board support package (bsp) accesses the bus. If it’s not cross platform then mabey the bus driver.
My bus is running at default of 100. I think you may be correct that it has something to do with AMD infinity fabric and the mb implementation. I hit a wall at around 14ish when evenly split on nodes and 16ish when all on the same node.
I haven’t check performance in other benchmark apps nor have I checked in umbuntu because I am a super Linux noob and could barely figure out how to install it and get hwloc setup…turned out to be easy but it took me a long time to figure that out.
I wonder ….If I am hitting a wall because the infinity fabric numa connections are saturated then I could test for that…If I lower my mem speed then infinity fabric speed will be lower as well…the result I expect would be that the max Wall I keep hitting would be even more limiting of my max speed without impacting the lower speeds…If my max speed stays nearly the same with say 2666 speed then the infinity fabric is not the limiting factor…The hard part will be if I mess up the setting and have to reset bios I have to pull video card to get to the clear cmos button… but I guess no risk…no reward.
Sure enough the wall at 2666 is 12gb/s…It looks to be saturating the infinity fabric…It would be interesting to switch the cards and see if being on the same numa node is also impacted to the same degree…One thing seems clear so far and that is that memory speed has a powerful impact on m.2 raids and speed should be prioritized over latency…also the m.2 raid appears to work best on the same node instead of what all the reviewers are saying…Of course that might in fact be correct for the higher end 24/32 core cpu’s but for the 2950x I would say stick to the same node and probably no more than 5 (3.5 gbps) drives for raid 0 as I don’t think infinity fabric can handle the thoughput…… I will do some more testing and post the results here.
It looks like the max speed of the drives scales with memory speed at the same timings but in all cases being on the same node in numa mode is faster. Not sure why its so limited as it looks like infinity fabric has 50GBs between nodes at 3200 cl14…even if that is split between the 4 core segements of the node that is still 25GBs per segment.
I also tried this with Uma mode and the results are similar.
I also tried both with up to QD32 and again similar results.
Have no idea what to test or change next. If anyone has a suggestion please post here and I will give it a try. I have to go back to work coding some HL7 nonsense Monday but I will be revisiting my testing next weekend.
I did some more follow up testing on the drives to determine the limiting factor of the raid and found some interesting results.
I tried every setting combination I could in the bios and I believe almost everything that was selectable was tried in each possible state. Nothing I changed in the bios seemed to impact performance positively except for setting the memory interleaving to channel and the pcie to gen3.
After exhaustively testing the bios I finally broke down the raid. I reinstalled windows with NVME raid turned on in the bios and the amd NVME raid driver installed. No raid was configured but each individual drive appeared as an individual raid array in the amd web raid interface.
When testing the drives one at a time all 6 would test at full bandwidth.
When testing two or more at a time they seemed to eat into each others maximum bandwidth potential at 1mb throughput testing and higher and seemed to get worse as the number of drives tested at the same time was increased. It also got worse as file size increased beyond 1mb file size.
Wondering if this was simply a limitation of the platform I turned off NVME raid and reinstalled windows without the amd raid drivers. All 6 drives could hit their full bandwidth when simultaneously tested.
I then enabled nvme raid again and again I reinstalled windows but I did not configure a raid and I did not install the amd raid drivers. All drives could still hit their full bandwidth when simultaneously tested. It was only when I installed the raid drivers that the bandwidth limitation appeared again even with no raid configured.
I believe the testing I have done indicates that the performance limitations are limitations from the amd raid driver implementation rather than any inherent hardware or platform limitation. The good news is that a amd raid driver update is likely all that is needed to resolve the limitations. The current version from October 2018 is stable but I think its fair to say that the driver has a lot of room for performance improvements.
One other interesting thing of note is that the cache settings are shamefully broken. Most of the testing I did was with writeback cache enabled and read ahead cache disabled. The stair step pattern you see in the results is from the cache being enabled. When it is disabled that pattern disappears and everything is consistently faster at about 256kb file sizes and larger. Sigh…I wish the AMD driver team could improve their product but I will say this driver has been rock solid stable so there is that at least. Maybe optimal is an unreasonable expectation and this was delivered for free in a superior platform implementation. The platform team did an excellent amazing job with the hardware…I just wish the driver team could keep up.