I have not found an NVMe server/JBOF I like AND can afford, but I am curious if anyone has one floating around I could use or if someone is willing to test something for me.
I am still digging into everything, but it looks like one of the more fun and basic/easy wins is to leverage namespaces.
iirc people/vendors have been having good luck/results/cus satisfaction with 5 disk raidz1s in the field, so I will go off of that assumption for now.
5 NVMe disks with 5 = size name spaces each, setup in 5 vdevs. Use none as the default NVMe IO scheduler.
I would love to see an A/B of a single namespace vs the below layout.
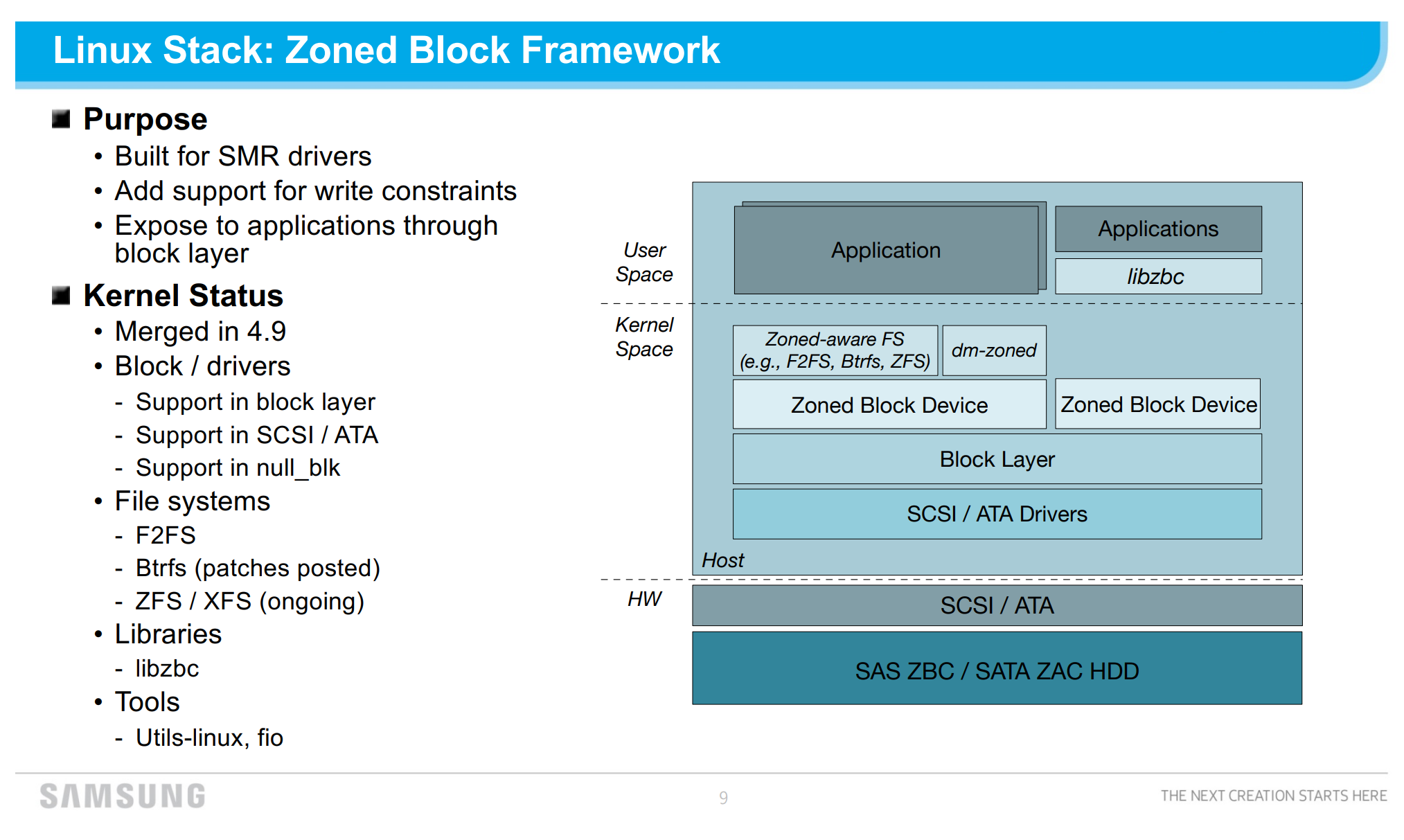
There is also Zoned Namespaces (ZNS), but I have not looked deeply into that yet, or if ZFS has a facility for it yet.
The OS assigns 2 threads per disk, in NVMe land, each namespace is treated as an independent disk, so to take advantage of the large amount of parallelism in NVMe vs what a normal kernel/file system is going to do, we can present each physical disk/controller as several namespaces, think of it like having 5 ssds behind a raid controller/HBA.
I might be able to assist in a week or two (note that I’m an absolute beginner regarding ZFS so would need idiot-proof guidances):
Am in the process of looking at AM5 motherboard AMD “chipset” software RAID with 6 Samsung 990 PRO SSDs that support NVMe 2.0 (for whatever that’s worth, 4 x 2 TB, 2 x 4 TB models). Each SSD gets 4 PCIe Gen4 lanes directly from the CPU.
When that’s done I can play with these SSDs for a while, but only in AM4 motherboards (likely an ASUS Pro WS X570-ACE with a 5950X) where due to the AM4 platform of course only 5 NVMe SSDs can be operated at full speed with native CPU PCIe Gen4 x4 interfaces.
Don’t have any PCIe Gen5 NVMe SSDs yet since I currently consider them to be useless due to still having stronger disadvantages than advantages (one of my maxims is always to increase the number of physical drives to have redundancy instead of faster individual drives).
This makes a lot of sense to me, and it seems like a lot of software that interfaces with storage need to be reconsidered because it probably makes assumptions based on the previous era of HDD, for example y-cruncher recently adding tuning values that have different defaults for HDD vs SSD.
The quote below from this User Guides - Swap Mode seems like it implements a very similar idea
When the lane multiplier is larger than 1, the framework will treat each path as if they were multiple independent drives and will stripe them accordingly. Accesses will then be parallelized across the lanes resulting in parallel access to the same path. … The motivation here is for drives that require I/O parallelism and high queue depth to achieve maximum bandwidth. (namely SSDs)
Also below are some other potentially interesting quotes about other SSD optimizations y-cruncher employs
Workers/lane is 2 for SSDs because SSDs require I/O parallelism (and a queue depth) to achieve the high bandwidth. … Each worker consists of an I/O buffer and a thread. … Increasing the # of workers increases the amount of I/O parallelism at the cost of higher CPU overhead and less sequential access. Some SSD-based arrays will find that 4 workers/lane to be better than the default of 2.
For SSDs, it is quite easy to saturate memory bandwidth from just I/O. … If this is the case, the buffer size should be small enough to fit comfortably in the CPU cache … Otherwise, a larger buffer size (> 8 MB) may be beneficial to reduce OS API overhead.
Thanks for the link. I was looking for “official” documentation in this regard.
In the presentation, namespaces were presented as different from partitions, but in my experience I see the same performance lift using partitions as with using namespaces.
I think the main benefit of namespaces over partitions is that they appear as separate devices, which is important for applications that only accept devices (not partitions) as input, such as VMware.
I have been using nvme partitions in zfs vdevs for a couple of years. However, I use nvme devices only as accelerators for HDD based pools.
In my tests, configuring 3-4 partitions as special or l2arc vdevs yield optimal performance.
To increase redundancy, your proposed scheme works well.
So, for my use cases I cannot see a performance difference between regular partitions and namespaces. However, partitions are more flexible compared to namespaces. Tools such as gparted can dynamically resize partitions without data loss. I am not aware of tools with similar functionality for namespaces. In my home lab I find that change is the only constant. That is typically not the case in enterprise use cases.
You’ll find that consumer nvmes don’t expose multiple namespaces (I am not aware of a single one). Intel Optane devices also don’t support multiple namespaces.
There are good discussions around namespaces on this forum. I encourage you to search.
Yes, I have been wondering why y-cruncher by default configures 4 threads. The micron presentation seems to explain this.
In my tests different configurations did not show improved performance.