Hello fellow nerdy peeps,
On links with friends today Wendell mentioned using a loacl ai model to help with coding.
I was wondering if any of ya’ll have any recommendations for which models might be good to play around with?
1 Like
I’ve heard of localGPT and starcoder2 in the last Linux Unplugged podcasts.
1 Like
One of the requirements is CUDA.
- Can this run on AMD? (6750XT)
- If not, would ZLUDA make it work?
GitHub - vosen/ZLUDA: CUDA on AMD GPUs
I think this is the hot one right now…
There is also GitHub - janhq/jan: Jan is an open source alternative to ChatGPT that runs 100% offline on your computer and their backend GitHub - janhq/nitro: An inference server on top of llama.cpp. OpenAI-compatible API, queue, & scaling. Embed a prod-ready, local inference engine in your apps. Powers Jan but not sure if/when they might support the new Starcoder 2.
Also not sure how easy it is to add a coding model because there are a few ways to approach it. Auto-complete models where it integrates with things like VS Code or your editor of choice vs the chat models of back and forth Q&A. Jan supports the chat style but again I’m not sure if it has coding models (usually the instruct variants) supported at the moment.
I find ollama excellent as a framework to run many different models easily locally. Look also into the excellent open-webui:
2 Likes
Also for reference, giving a code base to context window and having it work on open issues in a repo
1 Like
There are some of ai model that help in coding
ChatGPT
CodeBERT
GitHub Copilot
Huggingface.
I’ve been tinkering around with CodeLlama using Windows Subsystem for Linux (WSL). Follow this page up to the Ollama installation. After Ollama is installed, enter:
ollama run codellama:7b
You can then enter prompts and get answers locally in the terminal. The ‘7b’ model is the smallest, you could do the 34b model…it’s 19GB. Anytime you open up WSL and enter the ‘ollama run codellama:##’ it will display the prompt for you to enter your request. I’m just scratching the surface of figuring out on-prem LLM on a small scale…Ideally I want to use a pre-existing model but train it with my own data.
answered some of my own questions. it appears ollama does now support AMD!
so I started poking. at first ollama service wouldn’t start
ollama[18396]: Error: could not create directory mkdir /var/lib/ollama: permission denied
so we make the dir and give permissions (after finding the user in the service)
$ sudo mkdir /var/lib/ollama
$ sudo chown -R ollama:ollama /var/lib/ollama/
success! service starts but falls back to cpu. At first glance my 6750XT [gfx1031] looks not supported:
ollama[30982]: time=2024-03-15T17:45:38.102-06:00 level=INFO source=amd_linux.go:88 msg="detected amdgpu versions [gfx1031]"
ollama[30982]: time=2024-03-15T17:45:38.104-06:00 level=WARN source=amd_linux.go:114 msg="amdgpu [0] gfx1031 is not supported by /tmp/ollama1209781978/rocm [gfx1030 gfx1100 gfx1101 gfx1102 gfx900 gfx906 gfx908 gfx90a gfx940 gfx941 gfx942]"
As a test I ran basic ollama run llama2 and it worked but was a little slow…
However we can workaround it by adding this line under [Service] Environment="HSA_OVERRIDE_GFX_VERSION=10.3.0"
to the ollama service: /etc/systemd/system/ollama.service
Restart the service and:
systemctl restart ollama.service
Warning: The unit file, source configuration file or drop-ins of ollama.service changed on disk. Run ‘systemctl daemon-reload’ to reload units.
okay… we’ll reload the reload the daemons then try again:
$ systemctl daemon-reload
$ systemctl restart ollama.service
and… VIOLA! ![]() It works:
It works:
ollama[44620]: time=2024-03-15T19:43:25.001-06:00 level=INFO source=amd_linux.go:88 msg="detected amdgpu versions [gfx1031]"
ollama[44620]: time=2024-03-15T19:43:25.001-06:00 level=INFO source=amd_linux.go:246 msg="[0] amdgpu totalMemory 12272M"
ollama[44620]: time=2024-03-15T19:43:25.001-06:00 level=INFO source=amd_linux.go:247 msg="[0] amdgpu freeMemory 12272M"
llama2 test is is now significantly faster. didn’t run benchmarks but the difference is night and day.
Great success!
So it looks like the 6750XT is not officially supported but does totally work after applying the HSA_OVERRIDE_GFX_VERSION=10.3.0 work around.
now to try to set up for coding…
3 Likes
got the web ui up and running!
codellama 7b and 13b run fine on this machine (5900x | x570 | 32GB RAM | 6750XT)
34b chokes up the machine bad. not even gonna bother trying 70b on this hardware.
Looks like nvtop also supports AMD cards:
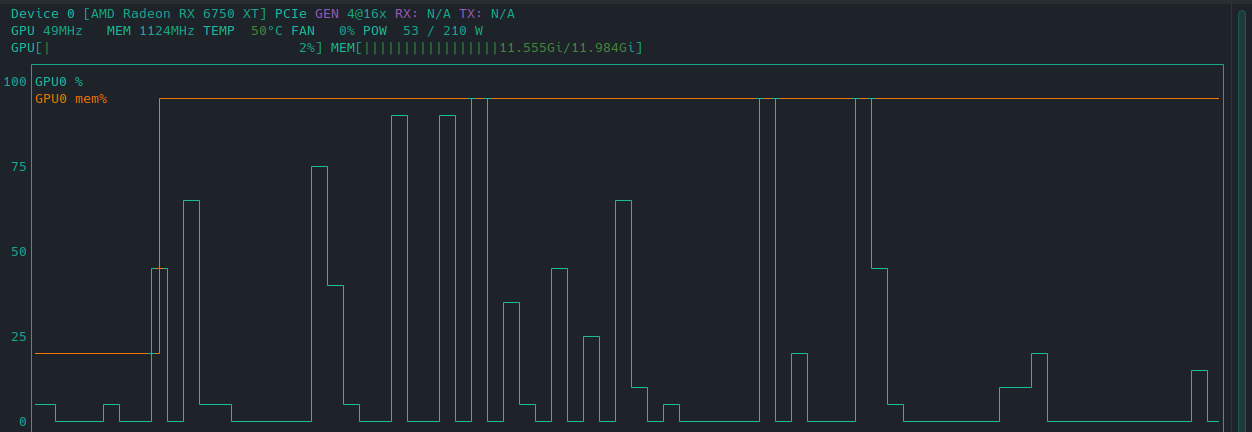
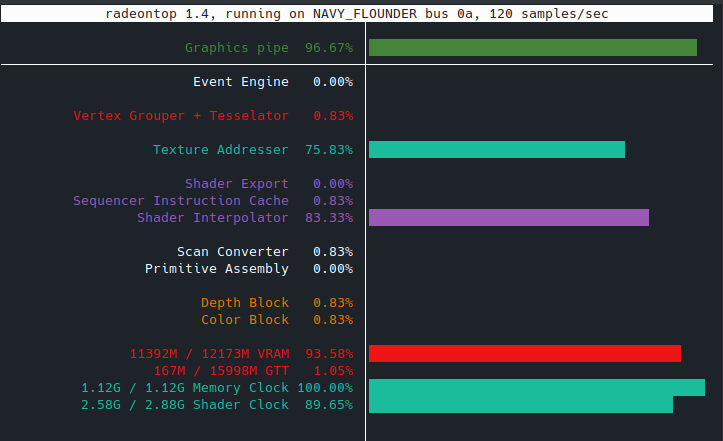
1 Like
The experience varies wildly.
I’m about to open a topic in terms of my adventures in this field.