What’s good, y’all? You guys heard about this thing called Borg Kubernetes? Sometimes spelled K8s because development practices from 80s are starting to come back (Agile, CI/CD, etc.).
I had a hellllluva time playing with Kubernetes. I even made a long write up and podcast episode about it! 
Table of Contents
- History of Kubernetes
- What I Thought Kubernetes Was (AKA What It Ain’t)
- My Setup
- Knowing Then What I Know Now
- Configuration
- Manifests and Images
- Podcast
- The Cloud! The Cloud!
History of Kubernetes
Kubernetes started out as a Google pet project. Google had an in-house cluster management system called Borg. My understanding of Borg is it was an automated system that ran scheduled tasked and chained everything together with shell scripts. It was a bit more sophisticated than that, due to the scale.
Google had jumped on the container bandwagon a long time ago due to their infrastructure utilization. You get a lot more mileage out of containers than VMs in certain workloads, and it was definitely that way for Google’s infrastructure. They looked to build a container management system, similar to Borg, but also facilitate the development across open source channels. They wanted anyone to be able to not only contribute and supply fixes, but take over project ownership if they wanted. This mentality is what led to RedHat’s OpenShift development, for example. Making the product open source also enabled Google to get more eyes on how their solution was going to be used across several industries.
This is a very compact overview. If you’re interested in Borg, the other Star Trek references at Google, and how Kubernetes showed up at Docker Con, definitely do your own research!
What I Thought Kubernetes Was (AKA What It Ain’t)
I ignored Kubernetes for the longest time due to some misconceptions I had and the nature of its complexity. First, I didn’t need it. I still don’t, but I am enjoying learning about it. Hearing the hype and enthusiasm bordering on fanaticism behind the program, I thought Kubernetes was a computer operating system targeted for data center clusters. Seeing it spring up on Digital Ocean, Amazon’s AWS, and Microsoft’s Azure platform made me more convinced that Kubernetes was, in fact, an operating system. I knew it was written in Go and at the OS Dev forums those crazy guys are writing systems and kernels in Go.
Lacking all sorts of context, I thought Kubernetes was an image you installed on a cluster of machines and it rolled out a network, fleet of systems, storage partitions, etc. The reality is a bit disappointing and lackluster after all of my expectations. Kubernetes is not the next ESXi or Nutanix, nor is it a variant of RedHat or Debian. It’s a container management platform that runs on top of an existing computer operating system. Some of you may already know this, and some of you might be laughing at my misguided beliefs. All I’m saying is at one point virtual machines were a completely foreign concept and now they’re the norm.
So, that being said, here is how I set everything up.
My Setup
Kubeadm is the option I decided to go with. You have several choices, but I really couldn’t figure out what the deal was with each, and Minikube was crashing a lot. I have four nodes that are running my Kubernetes cluster: A master node running on a RockPRO64 with Ubuntu 18.04 and three worker nodes running on KVM/QEMU virtual machines with CentOS 7. The network add on is through Weave Net, chosen because of its popularity and “industry standard” application. The documentation makes some recommendations on how to get things going.
What they don’t tell you is that Docker needs to be installed, enabled, and running before proceeding with the installation.
Just a piece of advice before you get too far along and can’t make heads or tails of the logs.
You need at least two vCPUs and two gigs of RAM. The ports you need open on master and worker nodes are listed in the docs.
kubelet, kubectl, and kubeadm have to be installed across the workers and master. Docker needs to be installed as well, as I mentioned earlier. A big consideration before you proceed is disabling swap. You can set a cron to run swapoff -a or just delete the entry in /etc/fstab.
If you are doing this on RHEL, CentOS, or Fedora, there are some strong considerations regarding SELinux and IPTables. Be sure to read the notes on your distribution. It was much easier doing this on Ubuntu versus CentOS.
Look at that footnote, at the bottom, AFTER YOU’VE PROBABLY RUN THE COMMANDS ABOVE. I get it, you need to read all of the documentation first before running commands, but seriously…
Knowing Then What I Know Now
-
Using hybrid/mixed architecture is probably a bad idea.
I have arm64 and AMD64 architecture in my cluster. This has caused a headache and some confusion more than once. The primary issue I had was building a Docker image on arm and deploying to AMD64. The logs provided little information, something about a formatting error. However, after some sleuthing and putting some pieces together, I tried building the image on a worker node and pushing the image – Son of a biscuit it worked. Shame on me, I guess. -
Going with various operating systems.
Ubuntu and CentOS, two systems that are regularly used across all sorts of development and enterprise efforts. But there were more than a few hiccups along the way. Doing it again, I’d likely just go with Ubuntu. I’m pretty sure that’s what Google used when developing Borg and Kubernetes, so why not share the love. When attempting to do the high availability cluster, I had more weird issues across Fedora server. -
Taking notes along the way before doing the installation.
This probably goes without saying for some of you, but I definitely need to make a habit of reading the documentation and taking some notes, then proceeding through the installation and configuration.
Configuration
I have a pretty standard configuration. The networking is deployed across the master, with some redundancy across the worker nodes. I have a service I creatively called “network” with a public IP and a load balancer to bounce between the two pods of my application.
Some of the terminology is a bit strange, but you can think of pod as the collection of containers and services that are required to run your application. IE a pod of 3 containers: two with nodejs and one with PostgreSQL. A service is a method to access the pods, such as a network address or load balancer (or both). Then you have a deployment, which is a way to manage the health checks, self-healing, and scaling of your pods.

You can use certain arguments to see all of the pods, including those for the master service, and see what workers are running what:
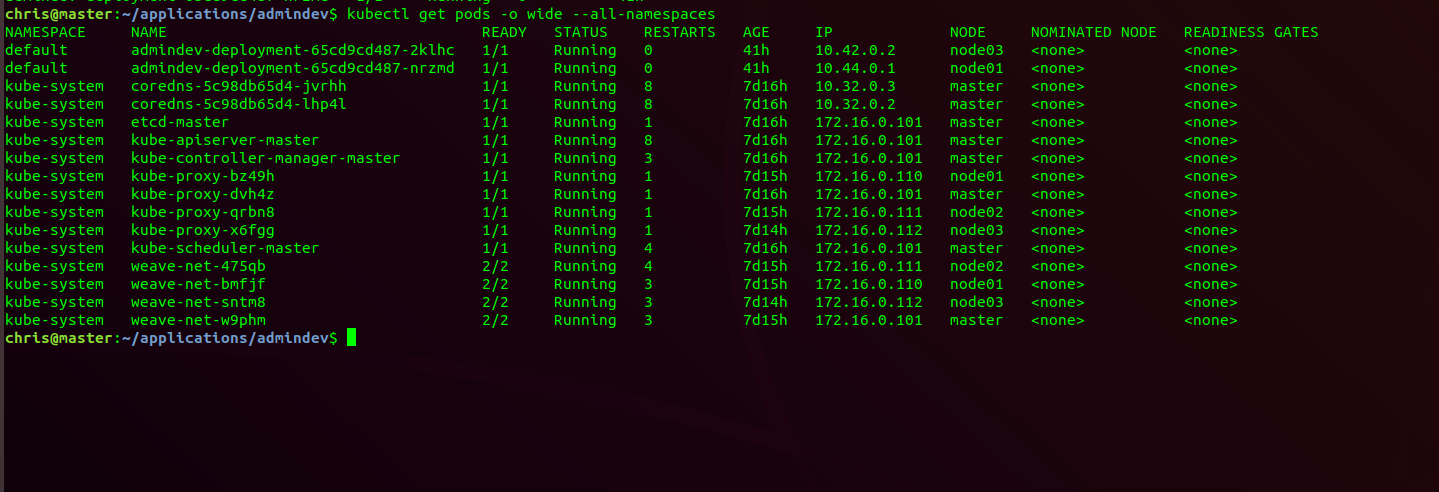
You do have a lot more control than I initially suspected, which is nice. You can define the network and role based authentication to allow certain tokens into certain nodes or perform certain actions.
Manifests and Images
I created an image out of my website and pushed it to Docker Hub. All things considered, it’s pretty simple:
FROM node:12.9.1-alpine
WORKDIR /var/www/html/admindev
COPY package*.json ./
RUN npm install
COPY . .
EXPOSE 3000
CMD [ "npm", "start" ]
The Kubernetes Manifests were a lot more interesting, but similar in structure to Docker-Compose or even something like CloudFormation. Although, not as complex as something like CloudFormation.
Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: admindev-deployment
spec:
selector:
matchLabels:
app: admindev
replicas: 2
template:
metadata:
labels:
app: admindev
spec:
containers:
- name: admindev
image: sysopsdev/admindev:latest
ports:
- containerPort: 3000
Service
apiVersion: v1
kind: Service
metadata:
name: network
spec:
type: LoadBalancer
ports:
- name: http
protocol: TCP
port: 80
targetPort: 3000
selector:
app: admindev
externalIPs:
- 172.16.0.101
I plan to add more to this once I experiment and git gud.
Podcast
The Cloud! The Cloud!
I got K8s up on Digital Ocean, too