Hi
I built a new system back in august and lately i’ve been having different errors pop up, and i am not yet skilled enough in linux to track down the cause. So, i was hoping i could get some advice.
My system:
Ryzen 9 3900x
Gigabyte Aorus master with F5n BIOS (i did change some settings per a thread on here about optimizing ryzen chips). I turned off PBO, and set the cpu voltage manually, but other than that, settings should be baseline, and no OC’ing.
32GB Crucial Ballistix RAM
2 nvme Adata sx8200Pro.
/boot and /boot/efi on separate partitions on #1. /, /home, and /swap are on RAID 0 on both drives.
Fedora 30
the most recent error is a kernel panic when i installed the latest kernel update. 5.3.11-200. “broken padding”. So far, this happens everytime i try to start this kernel.
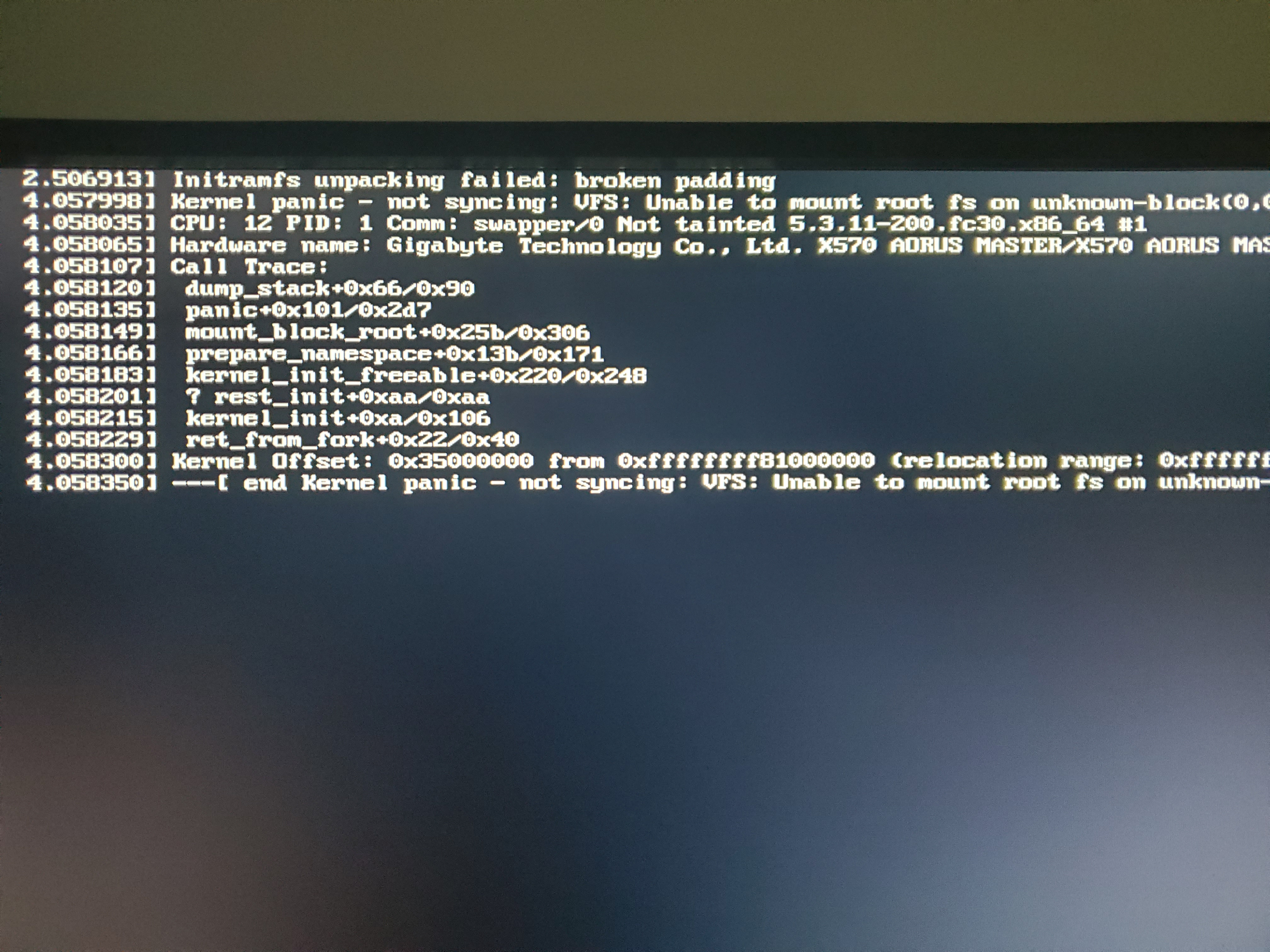
But, i can load into the previous kernel 5.3.8-200. And also, last week, when i updated to 5.3.8-200, i had the same problem. I could load into the previous kernel (5.2.18-200), but not the current one. Kernel panic again, but a slightly different message. (don’t have a picture of this error)
On November 15, i had the following error
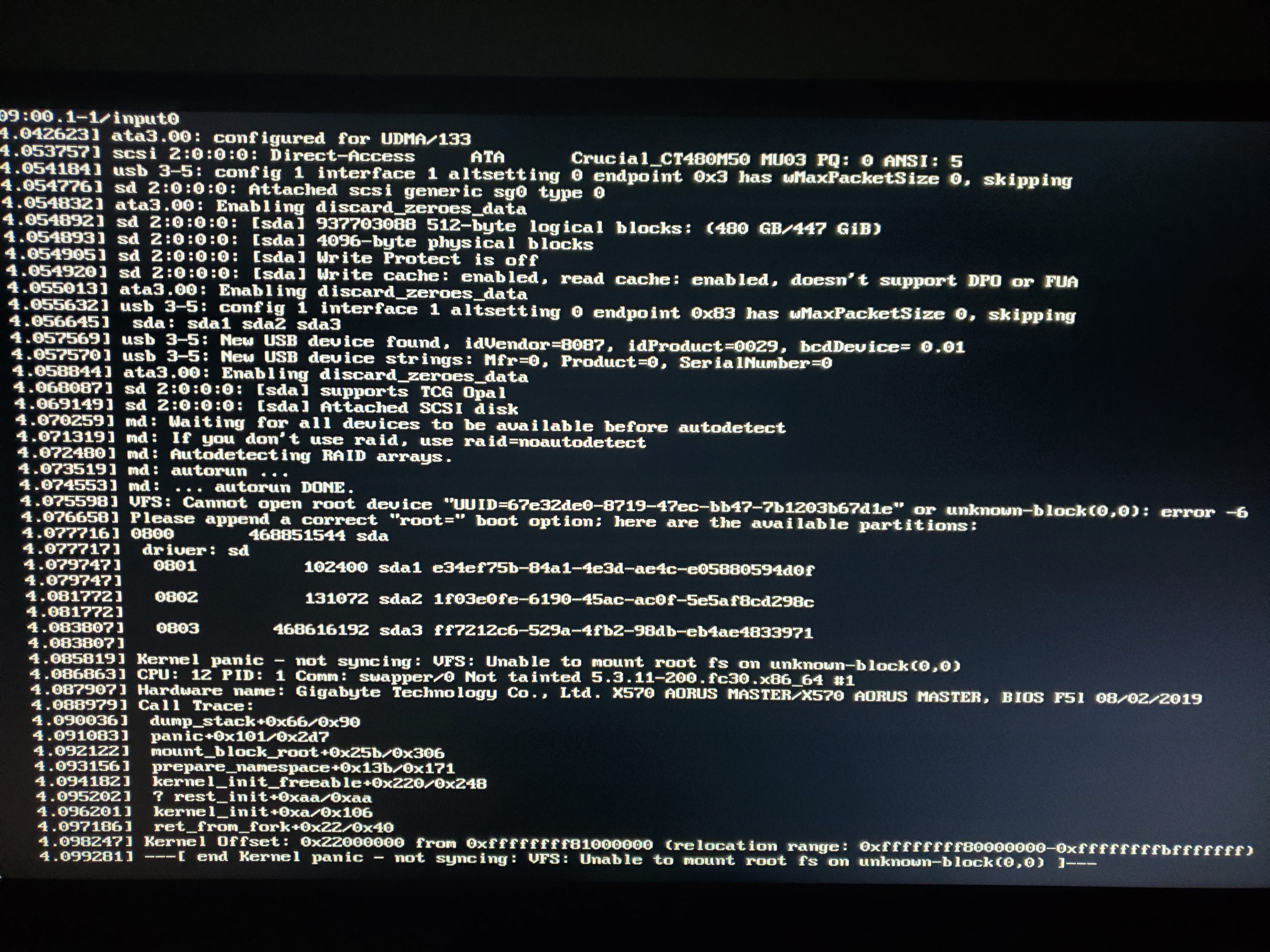
A couple of days ago i had this pop on in problem reporting
WARNING: CPU: 10 PID: 0 at arch/x86/kernel/cpu/common.c:1678 debug_stack_reset.cold+0xc/0xf
Also, on the same day this error
traps: ImgDecoder #12[23873] general protection fault ip:7fc101127e6a sp:7fc0e5ffa698 error:0 in libxul.so[7fc0fe2f5000+38be000]
2 weeks ago i had this error
BUG: Bad rss-counter state mm:00000000f54264e1 idx:1 val:3
Then, also 2 weeks ago, several errors of this nature, different cpu ids, but same error
watchdog: BUG: soft lockup - CPU#16 stuck for 22s! [kworker/16:0:3292]
On googling the kernel panics, i have seen reports that say it’s the initramfs that the problem, others say its the ram, others the hard drive. But given the CPU lockups, i’m am also concerned that i might have a bad processor.
Tried running memtest86 this morning, but it’s telling me it doesn’t work on EFI systems. I ran memtester for about 50 passes, but everything came back ok.
So, what i would really like is help to figure out what exactly is the issue. If it’s hardware, then i need answers so i can get warranty service. If it’s something else, then i of course, i just want to get it fixed.
Any advice or direction would be appreciated.
Thanks for reading
