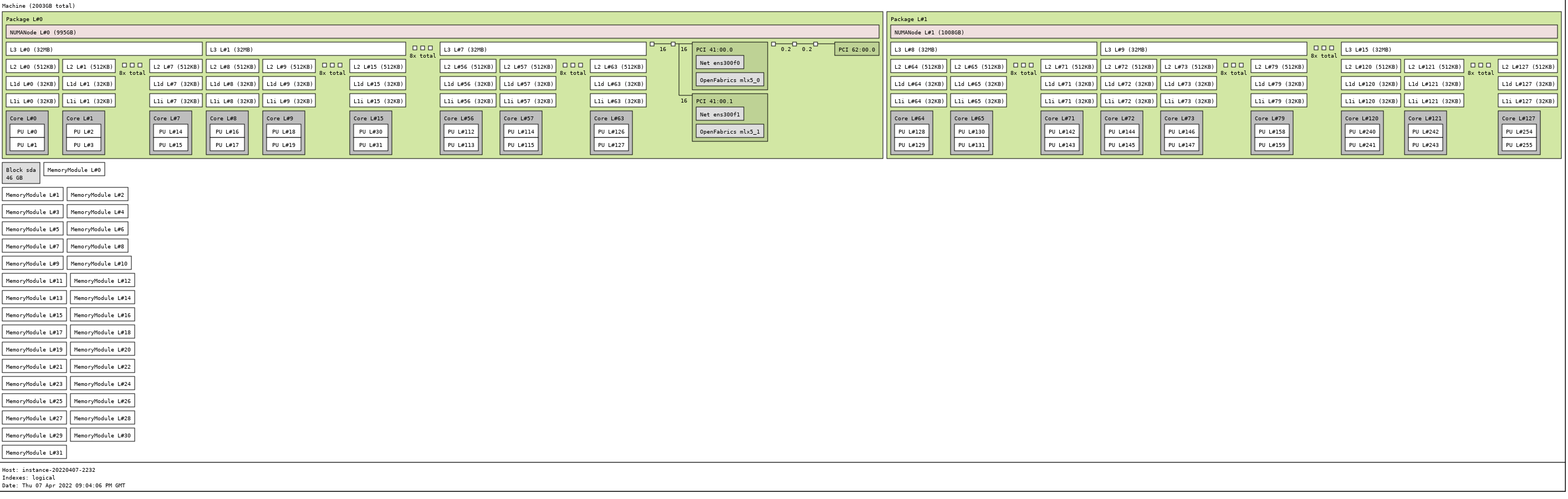
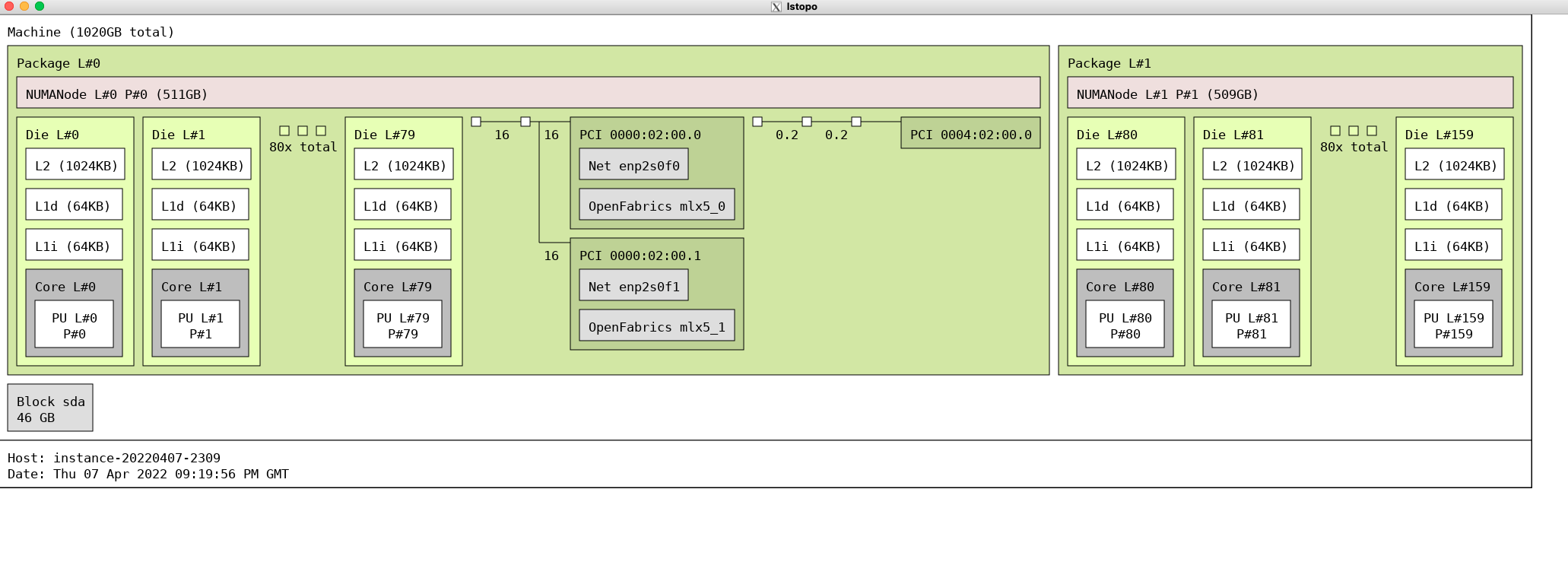
Introduction
This goes with a video we’re working on where we build systems around the Xeon 8380 and various AMD Epyc CPUs to see how each system handles building the Linux kernel.
Note this is different than the build benchmark in the Phoronix Test Suite – we are using kcbench and building all the modules.
The primary thing to understand is this breaks down into:
Which is better? One hundred duck-sized kernel builds, or one hore-sized kernel build?
It turns out that one hundred duck-sized builds is the best for multi-socket systems. For single-socket systems it only slightly favors the duck-sized builds over the singular horse-sized build.
Huh?
OK so kcbench will build the kernel with a certain number of make jobs (make -j # ). This is not perfectly linear scaling – especially with the kernel.
BUT kcbenchrate will allow us to specify how many parallel kernel builds we want, with an arbitrary number of threads for make to use.
This is very interesting because kcbench underestimates the performance of two-socket systems, both team blue and team red.
Let’s see the numbers!
kcbench -s 5.15 -m ✔
Processor: AMD EPYC 7713 64-Core Processor [128 CPUs]
Cpufreq; Memory: performance [acpi-cpufreq]; 64209 MiB
Linux running: 5.15.16-1-MANJARO [x86_64]
Compiler: gcc (GCC) 11.1.0
Linux compiled: 5.15.0 [/home/w/.cache/kcbench/linux-5.15/]
Config; Environment: allmodconfig; CCACHE_DISABLE="1"
Build command: make vmlinux modules
Filling caches: This might take a while... Done
Run 1 (-j 128): 281.52 seconds / 12.79 kernels/hour [P:11307%, 8673 maj. pagefaults]
Run 2 (-j 128): 281.69 seconds / 12.78 kernels/hour [P:11315%, 9014 maj. pagefaults]
Run 3 (-j 139): 280.99 seconds / 12.81 kernels/hour [P:11367%, 8969 maj. pagefaults]
Run 4 (-j 139): 361.59 seconds / 9.96 kernels/hour [P:8868%, 9538 maj. pagefaults]
Run 5 (-j 64): 321.06 seconds / 11.21 kernels/hour [P:6112%, 7854 maj. pagefaults]
Run 6 (-j 64): 320.78 seconds / 11.22 kernels/hour [P:6112%, 9128 maj. pagefaults]
kcbenchrate -s 5.15 -m -w 4 -j 32
10m 35s w@wkctest
Processor: AMD EPYC 75F3 32-Core Processor [128 CPUs]
Cpufreq; Memory: performance [acpi-cpufreq]; 515885 MiB
Linux running: 5.15.16-1-MANJARO [x86_64]
Compiler: gcc (GCC) 11.1.0
Linux compiled: 5.15.0 [/home/w/.cache/kcbench/linux-5.15/]
Config; Environment: allmodconfig; CCACHE_DISABLE="1"
Build command: make vmlinux modules
Starting 4 workers (each compiling with '-j 32'): .... All launched, starting to measure.
4 workers completed 4 kernels so far (avrg: 750.07 s/run) with a rate of 19.20 kernels/hour (each compiling with '-j 32').
4 workers completed 8 kernels so far (avrg: 750.09 s/run) with a rate of 19.20 kernels/hour (each compiling with '-j 32').
rocessor: AMD EPYC 7763 64-Core Processor [256 CPUs]
Cpufreq; Memory: performance [acpi-cpufreq]; 515845 MiB
Linux running: 5.15.12-1-MANJARO [x86_64]
Compiler: gcc (GCC) 11.1.0
Linux compiled: 5.15.0 [/home/w/.cache/kcbench/linux-5.15/]
Config; Environment: allmodconfig; CCACHE_DISABLE="1"
Build command: make vmlinux modules
Filling caches: This might take a while... Done
Run 1 (-j 256): 154.74 seconds / 23.26 kernels/hour [P:19352%, 16302 maj. pagefaults]
Run 2 (-j 256): 153.63 seconds / 23.43 kernels/hour [P:19576%, 15873 maj. pagefaults]
Run 3 (-j 271): 154.49 seconds / 23.30 kernels/hour [P:19434%, 16735 maj. pagefaults]
Run 4 (-j 271): 153.34 seconds / 23.48 kernels/hour [P:19632%, 15888 maj. pagefaults]
Run 5 (-j 128): 170.21 seconds / 21.15 kernels/hour [P:11004%, 17576 maj. pagefaults]
Run 6 (-j 128): 170.05 seconds / 21.17 kernels/hour [P:11005%, 18344 maj. pagefaults]
Run 7 (-j 140): 167.19 seconds / 21.53 kernels/hour [P:12001%, 15410 maj. pagefaults]
Run 8 (-j 140): 167.43 seconds / 21.50 kernels/hour [P:11953%, 16770 maj. pagefaults]
rocessor: AMD EPYC 7763 64-Core Processor [256 CPUs]
Cpufreq; Memory: performance [acpi-cpufreq]; 515845 MiB
Linux running: 5.15.12-1-MANJARO [x86_64]
Compiler: gcc (GCC) 11.1.0
Linux compiled: 5.15.0 [/home/w/.cache/kcbench/linux-5.15/]
Config; Environment: allmodconfig; CCACHE_DISABLE="1"
Build command: make vmlinux modules
Filling caches: This might take a while... Done
Run 1 (-j 256): 154.74 seconds / 23.26 kernels/hour [P:19352%, 16302 maj. pagefaults]
Run 2 (-j 256): 153.63 seconds / 23.43 kernels/hour [P:19576%, 15873 maj. pagefaults]
Run 3 (-j 271): 154.49 seconds / 23.30 kernels/hour [P:19434%, 16735 maj. pagefaults]
Run 4 (-j 271): 153.34 seconds / 23.48 kernels/hour [P:19632%, 15888 maj. pagefaults]
Run 5 (-j 128): 170.21 seconds / 21.15 kernels/hour [P:11004%, 17576 maj. pagefaults]
Run 6 (-j 128): 170.05 seconds / 21.17 kernels/hour [P:11005%, 18344 maj. pagefaults]
Run 7 (-j 140): 167.19 seconds / 21.53 kernels/hour [P:12001%, 15410 maj. pagefaults]
Run 8 (-j 140): 167.43 seconds / 21.50 kernels/hour [P:11953%, 16770 maj. pagefaults]
cbenchrate -s 5.15 -m -w 8 -j 32 127 ✘ 5m 58s
WARNING: Rate run still experimental. Use at your own risk!
Processor: AMD EPYC 7763 64-Core Processor [256 CPUs]
Cpufreq; Memory: performance [acpi-cpufreq]; 515845 MiB
Linux running: 5.15.12-1-MANJARO [x86_64]
Compiler: gcc (GCC) 11.1.0
Linux compiled: 5.15.0 [/home/w/.cache/kcbench/linux-5.15/]
Config; Environment: allmodconfig; CCACHE_DISABLE="1"
Build command: make vmlinux modules
Starting 8 workers (each compiling with '-j 32'): ........ All launched, starting to measure.
8 workers completed 8 kernels so far (avrg: 990.62 s/run) with a rate of 29.07 kernels/hour (each compiling with '-j 32').
8 workers completed 16 kernels so far (avrg: 991.16 s/run) with a rate of 29.06 kernels/hour (each compiling with '-j 32').
~ kcbench -s 5.15 -m ✔ 7s
Processor: AMD EPYC 7763 64-Core Processor [256 CPUs]
Cpufreq; Memory: performance [acpi-cpufreq]; 515845 MiB
Linux running: 5.15.12-1-MANJARO [x86_64]
Compiler: gcc (GCC) 11.1.0
Linux compiled: 5.15.0 [/home/w/.cache/kcbench/linux-5.15/]
Config; Environment: allmodconfig; CCACHE_DISABLE="1"
Build command: make vmlinux modules
Filling caches: This might take a while... Done
Run 1 (-j 256): 154.74 seconds / 23.26 kernels/hour [P:19352%, 16302 maj. pagefaults]
Run 2 (-j 256): 153.63 seconds / 23.43 kernels/hour [P:19576%, 15873 maj. pagefaults]
Run 3 (-j 271): 154.49 seconds / 23.30 kernels/hour [P:19434%, 16735 maj. pagefaults]
Run 4 (-j 271): 153.34 seconds / 23.48 kernels/hour [P:19632%, 15888 maj. pagefaults]
Run 5 (-j 128): 170.21 seconds / 21.15 kernels/hour [P:11004%, 17576 maj. pagefaults]
Run 6 (-j 128): 170.05 seconds / 21.17 kernels/hour [P:11005%, 18344 maj. pagefaults]
Run 7 (-j 140): 167.19 seconds / 21.53 kernels/hour [P:12001%, 15410 maj. pagefaults]
Run 8 (-j 140): 167.43 seconds / 21.50 kernels/hour [P:11953%, 16770 maj. pagefaults]
WARNING: Rate run still experimental. Use at your own risk!
Processor: AMD EPYC 7763 64-Core Processor [256 CPUs]
Cpufreq; Memory: performance [acpi-cpufreq]; 515845 MiB
Linux running: 5.15.12-1-MANJARO [x86_64]
Compiler: gcc (GCC) 11.1.0
Linux compiled: 5.15.0 [/home/w/.cache/kcbench/linux-5.15/]
Config; Environment: allmodconfig; CCACHE_DISABLE="1"
Build command: make vmlinux modules
Starting 8 workers (each compiling with '-j 32'): ........ All launched, starting to measure.
8 workers completed 8 kernels so far (avrg: 990.62 s/run) with a rate of 29.07 kernels/hour (each compiling with '-j 32').
8 workers completed 16 kernels so far (avrg: 991.16 s/run) with a rate of 29.06 kernels/hour (each compiling with '-j 32').
Can a workstation work?
Yes, but for this job if you only care about max # kernels/hour, then you need two sockets. Best value? One socket system by a wide margin. [Can you use distcc for max performance / $? oh probably … ]
kcbenchrate -s 5.15 -m -w 4 -j 32 ✔
WARNING: Rate run still experimental. Use at your own risk!
Processor: AMD Ryzen Threadripper PRO 3995WX 64-Cores [128 CPUs]
Cpufreq; Memory: performance [acpi-cpufreq]; 515676 MiB
Linux running: 5.15.16-1-MANJARO [x86_64]
Compiler: gcc (GCC) 11.1.0
Linux compiled: 5.15.0 [/home/w/.cache/kcbench/linux-5.15/]
Config; Environment: allmodconfig; CCACHE_DISABLE="1"
Build command: make vmlinux modules
Starting 4 workers (each compiling with '-j 32'): .... All launched, starting to measure.
4 workers completed 4 kernels so far (avrg: 927.43 s/run) with a rate of 15.53 kernels/hour (each compiling with '-j
32').
4 workers completed 8 kernels so far (avrg: 927.08 s/run) with a rate of 15.53 kernels/hour (each compiling with '-j
32').
~ kcbench -s 5.15 -m ✔ 25s
Processor: AMD Ryzen Threadripper PRO 3995WX 64-Cores [128 CPUs]
Cpufreq; Memory: performance [acpi-cpufreq]; 515676 MiB
Linux running: 5.15.16-1-MANJARO [x86_64]
Compiler: gcc (GCC) 11.1.0
Linux compiled: 5.15.0 [/home/w/.cache/kcbench/linux-5.15/]
Config; Environment: allmodconfig; CCACHE_DISABLE="1"
Build command: make vmlinux modules
Filling caches: This might take a while... Done
Run 1 (-j 128): 251.49 seconds / 14.31 kernels/hour [P:11182%, 8233 maj. pagefaults]
Run 2 (-j 128): 251.33 seconds / 14.32 kernels/hour [P:11197%, 8465 maj. pagefaults]
Run 3 (-j 139): 250.54 seconds / 14.37 kernels/hour [P:11261%, 8571 maj. pagefaults]
Run 4 (-j 139): 250.84 seconds / 14.35 kernels/hour [P:11236%, 8255 maj. pagefaults]
Run 5 (-j 64): 294.60 seconds / 12.22 kernels/hour [P:6096%, 6148 maj. pagefaults]
Run 6 (-j 64): 295.11 seconds / 12.20 kernels/hour [P:6093%, 6375 maj. pagefaults]
Run 7 (-j 72): 289.05 seconds / 12.45 kernels/hour [P:6816%, 6805 maj. pagefaults]
Run 8 (-j 72): 289.13 seconds / 12.45 kernels/hour [P:6813%, 7088 maj. pagefaults]
Notice that even in a single socket system, we get a small but measurable underestimate of compile rate with multiple parallel jobs.
Yes, there is work underway to speed this up however with things like LTS kernels… we’re going to be doing it this way for at least 6 more years.
What abou Dual Xeon 8380s for this job?!
Here’s the Xeon 8380 – very impressive for 80 cores/160 threads:
~ kcbench -s 5.15 -m ✔
Processor: Intel(R) Xeon(R) Platinum 8380 CPU @ 2.30GHz [160 CPUs]
Cpufreq; Memory: performance
powersave [intel_pstate]; 515605 MiB
Linux running: 5.15.16-1-MANJARO [x86_64]
Compiler: gcc (GCC) 11.1.0
Linux compiled: 5.15.0 [/home/w/.cache/kcbench/linux-5.15/]
Config; Environment: allmodconfig; CCACHE_DISABLE="1"
Build command: make vmlinux modules
Filling caches: This might take a while... Done
Run 1 (-j 160): 218.45 seconds / 16.48 kernels/hour [P:13747%, 9128 maj. pagefaults]
Run 2 (-j 160): 220.40 seconds / 16.33 kernels/hour [P:13785%, 9134 maj. pagefaults]
Run 3 (-j 172): 220.84 seconds / 16.30 kernels/hour [P:13836%, 9146 maj. pagefaults]
Run 4 (-j 172): 221.20 seconds / 16.27 kernels/hour [P:13840%, 8680 maj. pagefaults]
Run 5 (-j 80): 245.99 seconds / 14.63 kernels/hour [P:7511%, 7638 maj. pagefaults]
Run 6 (-j 80): 246.10 seconds / 14.63 kernels/hour [P:7508%, 7478 maj. pagefaults]
Run 7 (-j 89): 240.70 seconds / 14.96 kernels/hour [P:8303%, 8166 maj. pagefaults]
Run 8 (-j 89): 240.88 seconds / 14.95 kernels/hour [P:8293%, 8026 maj. pagefaults]
~ kcbenchrate -s 5.15 -m -w 4 -j 32 ✔ 34m 44s
WARNING: Rate run still experimental. Use at your own risk!
Processor: Intel(R) Xeon(R) Platinum 8380 CPU @ 2.30GHz [160 CPUs]
Cpufreq; Memory: performance [intel_pstate]; 515605 MiB
Linux running: 5.15.16-1-MANJARO [x86_64]
Compiler: gcc (GCC) 11.1.0
Linux compiled: 5.15.0 [/home/w/.cache/kcbench/linux-5.15/]
Config; Environment: allmodconfig; CCACHE_DISABLE="1"
Build command: make vmlinux modules
Starting 4 workers (each compiling with '-j 32'): .... All launched, starting to measure.
4 workers completed 4 kernels so far (avrg: 828.40 s/run) with a rate of 17.38 kernels/hour (each compiling with '-j 32').
4 workers completed 8 kernels so far (avrg: 829.02 s/run) with a rate of 17.37 kernels/hour (each compiling with '-j 32').
3970X Threadripper, Older Intel Broadwell and 7402P Comparison Systems
$ ./kcbench -s 5.15 -o /dev/shm/ -m
Processor: AMD EPYC 7502P 32-Core Processor [48 CPUs]
Cpufreq; Memory: Unknown; 257618 MiB
Linux running: 4.19.0-17-amd64 [x86_64]
Compiler: gcc (Debian 8.3.0-6) 8.3.0
Linux compiled: 5.15.0 [/home/gregkh/.cache/kcbench/linux-5.15/]
Config; Environment: allmodconfig; CCACHE_DISABLE="1"
Build command: make vmlinux modules
Filling caches: This might take a while... Done
Run 1 (-j 48): 401.67 seconds / 8.96 kernels/hour [P:4428%]
Run 2 (-j 48): 401.83 seconds / 8.96 kernels/hour [P:4427%]
Run 3 (-j 54): 401.65 seconds / 8.96 kernels/hour [P:4452%]
Run 4 (-j 54): 401.49 seconds / 8.97 kernels/hour [P:4454%]
Run 5 (-j 24): 560.51 seconds / 6.42 kernels/hour [P:2391%]
Run 6 (-j 24): 558.85 seconds / 6.44 kernels/hour [P:2399%]
Run 7 (-j 29): 505.41 seconds / 7.12 kernels/hour [P:2876%]
Run 8 (-j 29): 505.59 seconds / 7.12 kernels/hour [P:2878%]
$ ./kcbench -o ~/tmp/ -s 5.15 -m
Processor: Intel Core Processor (Broadwell) [40 CPUs]
Cpufreq; Memory: Unknown; 120740 MiB
Linux running: 5.15.11-200.fc35.x86_64 [x86_64]
Compiler: gcc (GCC) 11.2.1 20211203 (Red Hat 11.2.1-7)
Linux compiled: 5.15.0 [/home/gregkh/.cache/kcbench/linux-5.15/]
Config; Environment: allmodconfig; CCACHE_DISABLE="1"
Build command: make vmlinux modules
Filling caches: This might take a while... Done
Run 1 (-j 40): 1087.33 seconds / 3.31 kernels/hour [P:3662%, 8851 maj. pagefaults]
Run 2 (-j 40): 1091.40 seconds / 3.30 kernels/hour [P:3649%, 9283 maj. pagefaults]
Run 3 (-j 46): 1088.90 seconds / 3.31 kernels/hour [P:3690%, 7156 maj. pagefaults]
Run 4 (-j 46): 1093.40 seconds / 3.29 kernels/hour [P:3681%, 7469 maj. pagefaults]
$ ./kcbench -s 5.15 -o /dev/shm/ -m
Processor: AMD Ryzen Threadripper 3970X 32-Core Processor [64 CPUs]
Cpufreq; Memory: schedutil [acpi-cpufreq]; 257679 MiB
Linux running: 5.16.2-arch1-1 [x86_64]
Compiler: gcc (GCC) 11.1.0
Linux compiled: 5.15.0 [/home/gregkh/.cache/kcbench/linux-5.15/]
Config; Environment: allmodconfig; CCACHE_DISABLE="1"
Build command: make vmlinux modules
Filling caches: This might take a while... Done
Run 1 (-j 64): 390.46 seconds / 9.22 kernels/hour [P:5806%, 12974 maj. pagefaults]
Run 2 (-j 64): 391.27 seconds / 9.20 kernels/hour [P:5803%, 12972 maj. pagefaults]
Run 3 (-j 71): 399.18 seconds / 9.02 kernels/hour [P:5725%, 11822 maj. pagefaults]
Run 4 (-j 71): 391.20 seconds / 9.20 kernels/hour [P:5844%, 11629 maj. pagefaults]
Run 5 (-j 32): 488.53 seconds / 7.37 kernels/hour [P:3156%, 9134 maj. pagefaults]
Run 6 (-j 32): 488.95 seconds / 7.36 kernels/hour [P:3150%, 8448 maj. pagefaults]
Run 7 (-j 38): 461.76 seconds / 7.80 kernels/hour [P:3722%, 8009 maj. pagefaults]
Run 8 (-j 38): 461.32 seconds / 7.80 kernels/hour [P:3723%, 7662 maj. pagefaults]
It is worth noting that depending on your motherboard and bios version you might see between 2.3 and 2.91 boost clocks running this job. I was running a later bios with better performance – the earlier bios wasn’t as good because the CPUs would taper off to 2.3ghz after a short time and this test usually runs for ~2 hours.
Wendell
 thanks!
thanks!