Terve!
I recently redid my NAS, moving it from Freenas to Openmediavault.
Now the system sent me a notification about bad sectors. Should I replace the drive immediately or can I wait with it?
The drives are running in RAID5.
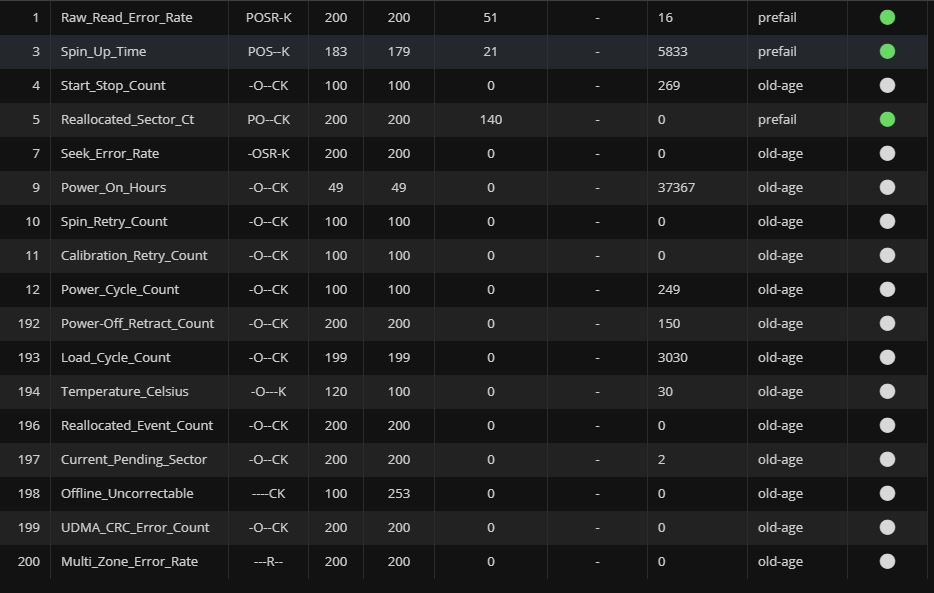
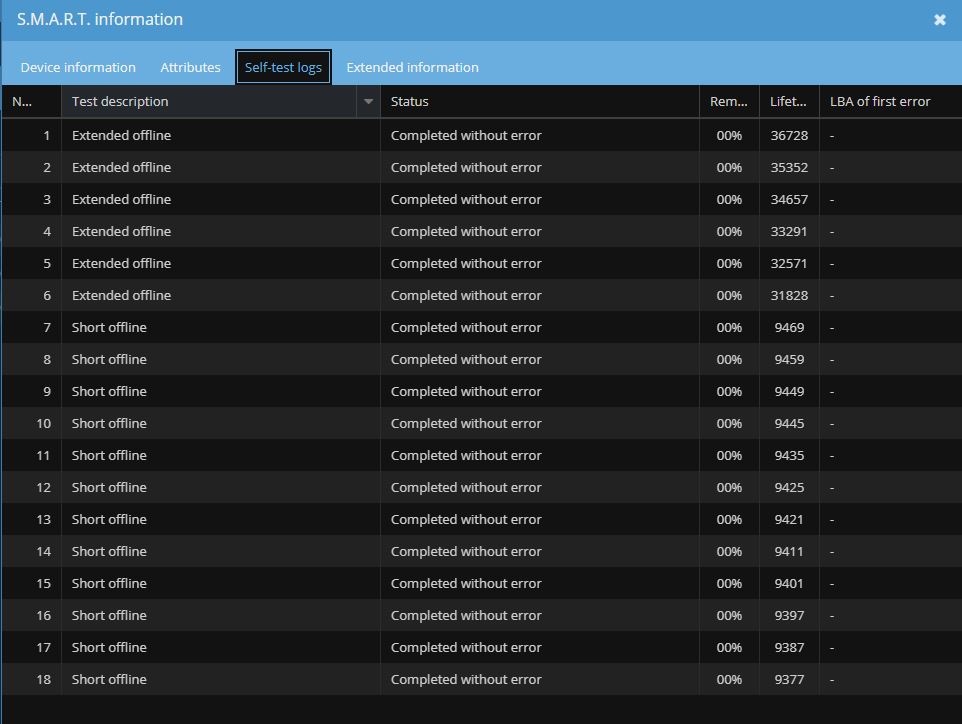
Edit: all the tests that are logged under the drive are “completed without error” and there’s no warnings under “attributes” (containing things like reallocated sector count, in case that’s not a standard thing)
Hardware is:
Mainboard: ASUS P9X-D
CPU: Intel Xeon V1225V3
RAM 4x8GB ECC RAM (Kingston Value RAM)
HDDs: 3x 3TB WD red
OS is on a new 120GB Kingston SSD
Mail content: (please let me know if you need syslog)
This message was generated by the smartd daemon running on:
host name: openmediavault
DNS domain: local
The following warning/error was logged by the smartd daemon:
Device: /dev/disk/by-id/ata-WDC_WD30EFRX-68EUZN0_WD-WCC4N1FP4CV3 [SAT], 2 Currently unreadable (pending) sectors
You can also use the smartctl utility for further investigation.
The original message about this issue was sent at Sat May 30 04:43:31 2020 CEST
Another message will be sent in 24 hours if the problem persists.
That’s the basic smart data. You can test the drive. As of now it seems as though you don’t have any reallocations, just 2 pending. The drive is still in ok shape but you should expect and prepare for failure in the near future. Sometimes drives will keep chugging along like this for years, and sometimes they develop more and more reallocations in a month until you get failure.
I’m not very familiar with OMV but it should have some capacity to do smart tests. If you don’t have a backup then the time to replace is now.
Terve!
Here’s an other picture. All the tests were okay without issues.
Since I have a backup, I’ll wait with the replacement.
The chance of 2/3 HDDs failing alongside the backup HDD is rather small I think.
I personally have old-ass Seagate Barracuda 500gb drive that one wonderful day like 5 years ago caught 2k bad sectors. And that was it. Nothing else ever happened since that. And this drive overall is like dunno 14 years old? something among those lines. It was completely random encounter.
It really is hit or miss. One 9 years old Hitachi died on me last friday. But if you’d see its SMART results you’d cry XD I knew it’s gonna fail but i kept it regardless since i wanted to test btrfs RAID1 behavior. But that drive:
a) - had realloc sectors
b) - had spinup failures
c) - failed billion of SMART self-tests
d) - made so hardcore clicking noises I can hear it over listening to music
e) - randomly crashed with i/o error and puked dmesg blk_update errors to logs
AND last thursday it failed so badly btrfs finally refused to mount AND i was still in fact able to recover data from it when I mounted disk with ro,recovery,degraded flags (though it was punking with blk_update errors all the time and it probably entered some ultra hardcore recovery mode since i/o speed dropped to like 1MB/s sequential).