Thanks for the new video @wendell! It’s quite timely for me. I’m setting up a new storage/Proxmox server using a bunch of the 2x18 SATA drives. I have 6 of the SATA drives and have been experimenting with different ways to configure them and which OS/GUI to use with them. The plan is to run Proxmox 8 on the bare metal and then pass the drives through (via an Adaptec HBA) to a VM that’s running on Proxmox. I currently have another machine that’s doing just this, albeit with TrueNAS core. It seems to work pretty well.
So these new dual actuator drives bring with them awesome performance potential but also some quirks that make it a bit more tricky to implement in TrueNAS and/or Houston. Neither of these “GUIs” will allow me to split the drives at the halfway point as is required to use them properly. At least I haven’t been able to find a way to make it work via their GUIs. What I ended up doing was using the script from @John-S to name the drive halves and then manually create a pool using the Linux command line zfs/zpool commands. This seems to work well and allows me to import the pool into either TrueNAS Scale or Houston.
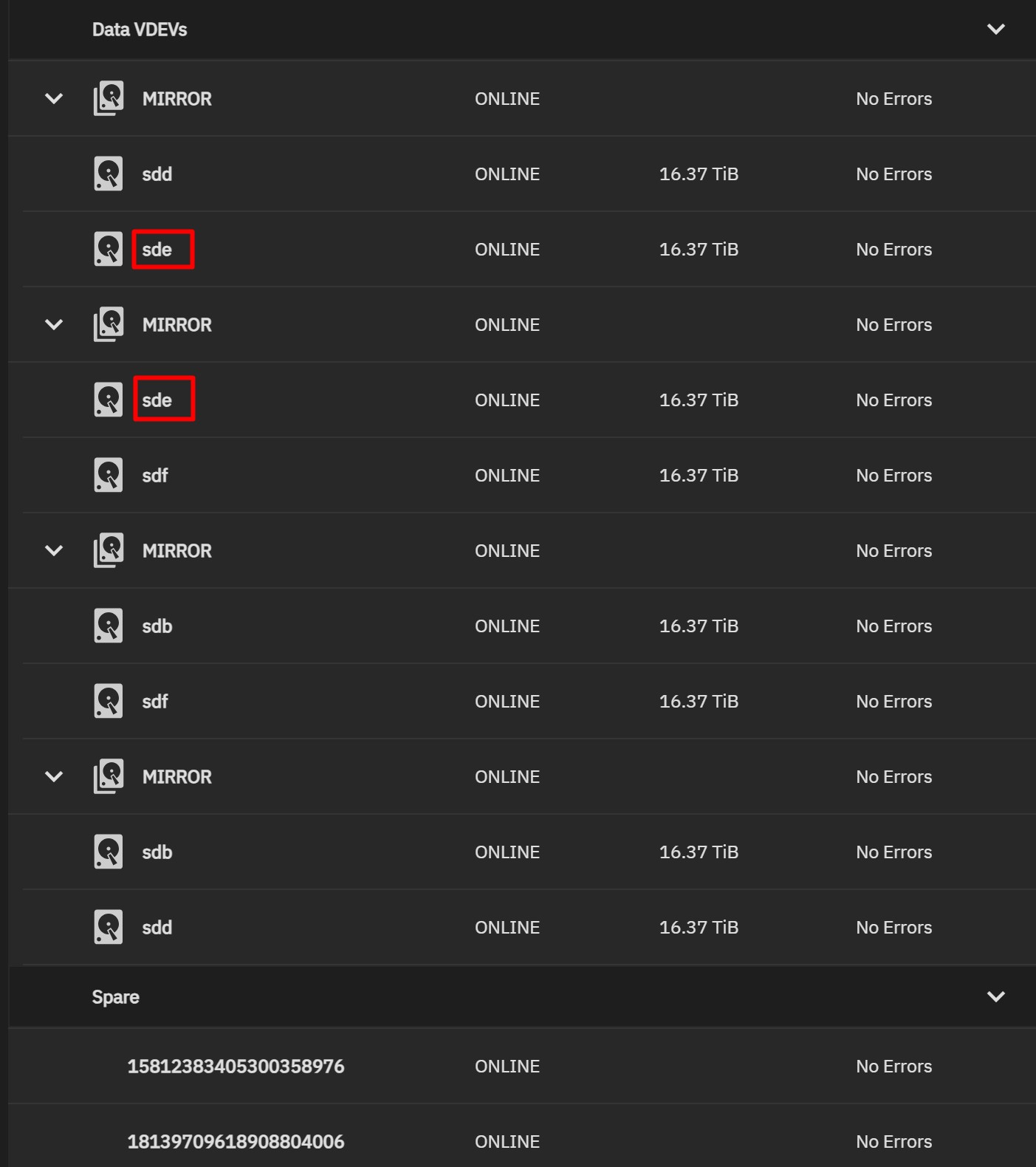
The issue with this method is that neither TrueNAS or Houston seems to understand what’s going on with the pool.
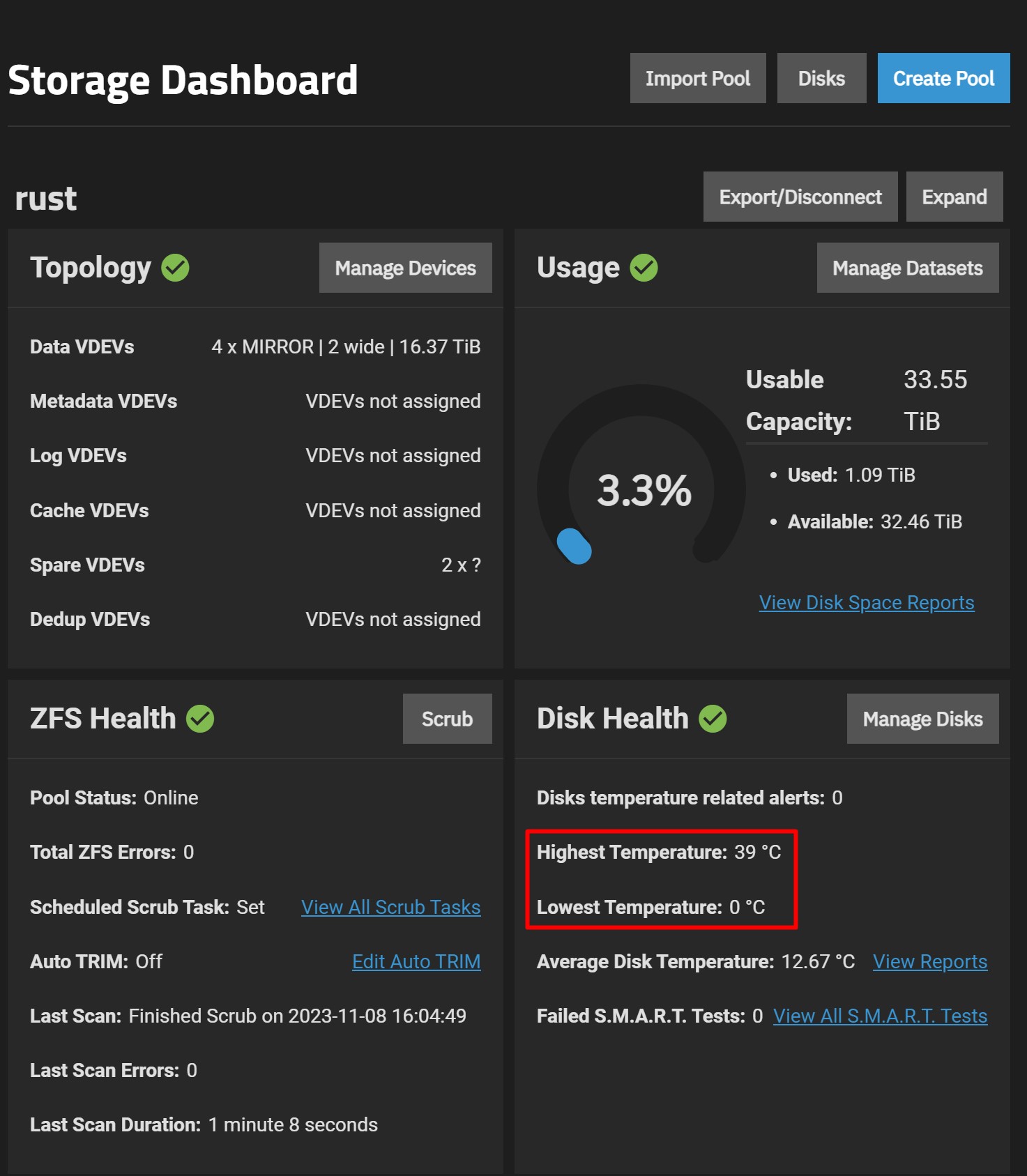
It seems to want to refer to the Vdev constituents as /dev/sdX, rather than the partitions that actually comprise the Vdevs. Also, the sizes shown are incorrect and each drive is shown twice. This also leads to weird readings for temperature. It does read the drive temperatures but seemingly sees half of them at zero degrees.
I can live with the weird temperature readings and constituent drive space size errors. I’m just wondering what the best OS/software infrastructure base for these drives would be (here in November 2023).
I looked into the kernels used for TrueNAS Scale and Houston and both of them are understandably using STABLE releases of the kernel/Linux distro. TrueNAS uses kernel 6.1 and is unlikely to be updated any time soon. Houston is to be run on Ubuntu 20.04LTS, if I’m reading things correctly.
Looks like from Linux kernel 6.3 and onward, there are optimizations implemented.
Updating the kernel underneath TrueNAS scale seems to be frowned upon. Not sure how Houston would deal with a newer kernel/OS version.
Then there’s the drive topology… with 6 of the 2x18 drives, I’m left with a bunch of options. For now, I have it set up as 4 mirror Vdevs with an offset in A/B pairs to provide more resilience against a whole drive failure:
rust pool
- Mirror1
**Drive 1A
**Drive 2B
- Mirror2
**Drive 2A
**Drive 3B
- Mirror3
**Drive 3A
**Drive 4B
- Mirror4
**Drive 4A
**Drive 1B
- Hot Spares
**Drive 5A
**Drive 5B
My concern is how ZFS will deal with a drive failure. If a whole physical drive fails, then my guess is that it will replace both partitions (i.e. Drive XA and Drive XB) with both partitions of the hot spare Drive 5A and Drive 5B. But what happens if one actuator fails? My assumption is Drive XA is replaced by Drive 5A. Does this leave me with my proverbial pants down if another drive fails?
And what about expanding the pool? If I were to add a single, dual actuator drive, they would both end up in the same mirror Vdev, thus not following the offset scheme to preserve some redundancy. If that new drive were to fail, it would take down the whole pool. Seems like it would require adding two more physical drives and making mirrors of opposite drive actuators (i.e. A1/B2 and A2/B1 mirrors). I suppose this isn’t really that much different than with conventional drives. To expand, you just add another mirrored Vdev.
Another possible scenario would be a mirror of stripes, as opposed to the stripe of mirrors as described above. Something like this:
rust pool
- Mirror1
** Stripe 1
*** A1, B1, A2, B2
** Stripe 2
*** A3, B3, A4, B4
Not even sure this is possible but I presume it is. BUT, it would seem to break the golden rule described in posts above of never having A and B actuators of the same drives in the same Vdev. Would a scenario like this be susceptible to the issue with queues? I’m showing my noobness here. I just don’t totally understand how that would work at a kernel level. Regarding hot spares in this scenario, it would seem that it’s more straightforward but again, I’m not sure how ZFS would deal with it.
But what about expansion in this scenario? Could a single physical drive be added? I don’t think so because if that new drive failed, it would take down both sides of the mirror.
- A1, B1, A2, B2, A5
- A3, B3, A4, B4, B5
So it would need a new pair of physical drives to be added:
- A1, B1, A2, B2, A5, B5
- A3, B3, A4, B4, A6, B6
@wendell Thanks again for the video and inspiration. You mentioned in the video at the end for us viewers to ask what we’d like to see regarding setups with these dual actuator SATA drives. I have a feeling there’s going to be more folks lurking around trying to figure out how to navigate all of this. So my suggestion for video and/or how-to content would be to address some of the intricacies I’ve raised above.
So what’s a geek to do? I don’t mind being on the bleeding edge, as it’s just a homelab and the data will be backed up using the 1-2-3 principle.
–EDIT to deal with adding drives in the second scenario of mirrored stripes.