Check the videos out here:


Buy Yours Here
SAS3
SATA3
What is script this for?
This script is for users of ZFS and dual actuator hard drives!
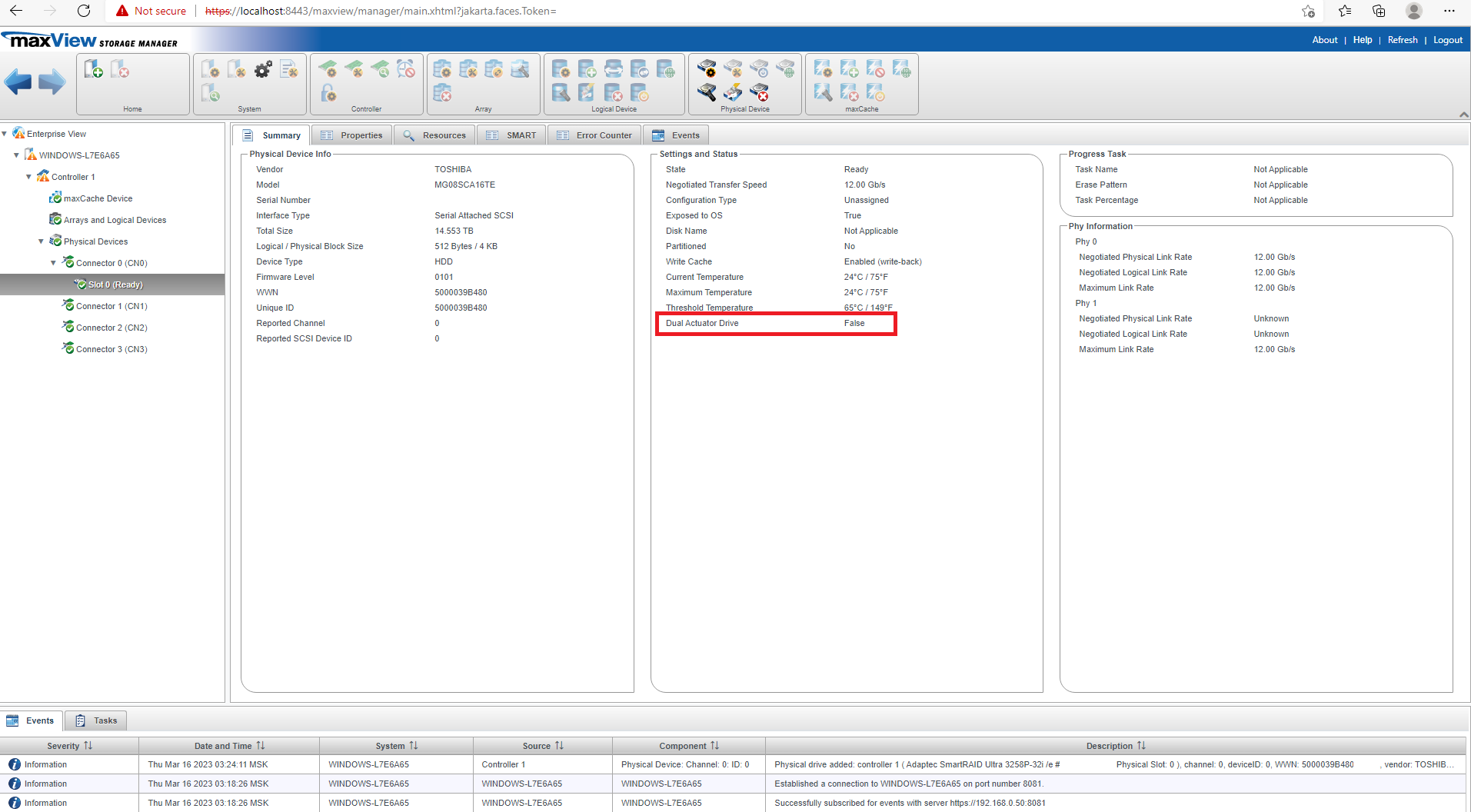
Behold – the latest innovation, long overdue, the DUAL ACTUATOR mechanical hard drive.

The Seagae Exos Mach.2 hard drive; the 18TB variant. Dual actuator you say?? What’s that?
These drives are basically perfect for ZFS – double the iops at a cost delta of maybe +$10 per drive? Sign me up! But since each drives presents as two in order to keep the complexity (and therefor cost) as low as possible we must be careful about our ZFS pool geometry – it would be handy if we could quickly determine optimal ZFS pool setups to maximize redundancy and to keep in mind that when a drive dies we could lose up to TWO device entries in our ZFS pool when just ONE physical device dies.
That means spreading the redundancy across multiple raidz1 vdevs (so that if a drive fails catastrophically we are GUARANTEED the failing vdev component drives are not in the same vdev).
It is really easy to do that with this handy script!
More Background
Be aware that these drives are available in both SAS and SATA variants. Since SATA drives don’t support logical unit numbers, it’s just an LBA block range that determines which actuator you get (front half of the drive is one actuator, back half is the other).
For SAS, the drive presents as two logical units.
Even though the SAS version of the drive is not super atypical, basically all hardware raid controllers will not work with dual-actuator drives.
ZFS, on the other hand, is made for these drives. They work together great!
Dual Actuator Drives in the Wild
Understanding The Script
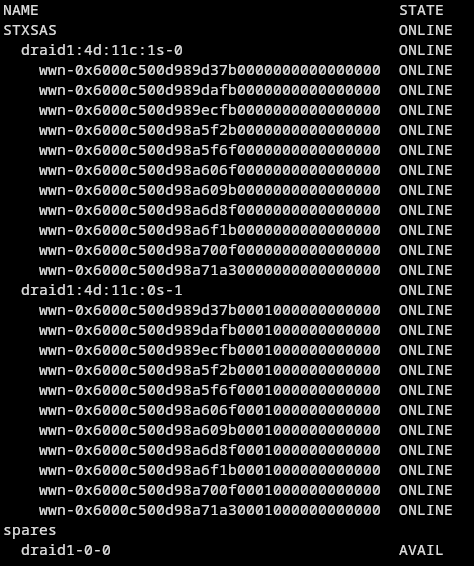
ls /dev/disk/by-id/
You should have output similar to the following:
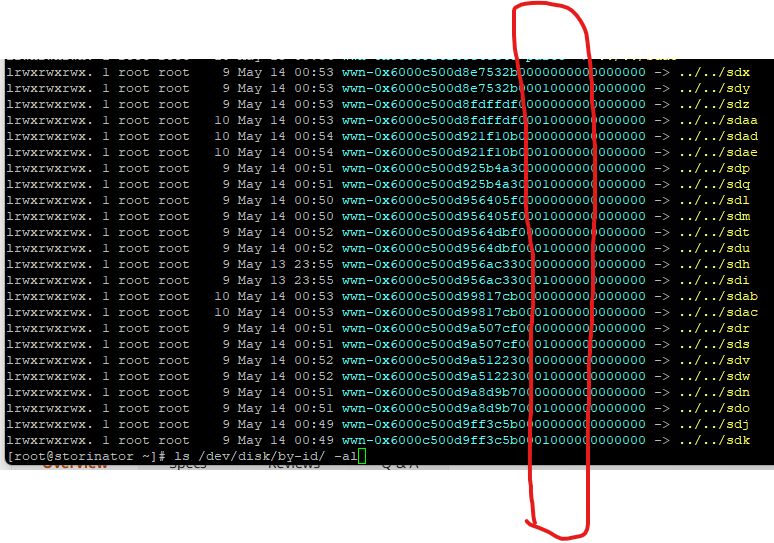
The # indicate unique drives with the 1 or 0 column indicating the logical unit number (in the case of SAS drives).
The yellow part indicates where the disk device is.
The Script
#!/bin/bash
# Directories
DIR=/dev/disk/by-id
# Array for devices
declare -a DEVICES_00=()
declare -a DEVICES_01=()
# Iterate over each wwn device
# 6000c500d is dual actuator wwn prefix
# last char is 0 to avoid -part devices that
# may appear here as well
for FILE in ${DIR}/wwn-0x6000c500d*0; do
# Extract the last two characters of the wwn
LAST_TWO_CHARS=$(basename $FILE | cut -c25-26)
# Check which array to add the device to based two characters of the wwn
if [ $LAST_TWO_CHARS == "00" ]; then
DEVICES_00+=("/dev/disk/by-id/$(basename $FILE)")
elif [ $LAST_TWO_CHARS == "01" ]; then
DEVICES_01+=("/dev/disk/by-id/$(basename $FILE)")
fi
done
# Ideally you have at least *3* devices (6 entries) you are using with this script
# base command
echo "zpool create mach2tank -o ashift=12 \ "
# raidz1 vdev made of the top halves of drives
if [ ${#DEVICES_00[@]} -gt 3 ]; then
echo " raidz1 ${DEVICES_00[@]} \ "
fi
echo -e "\n"
# raidz1 vdev made of the bottom halves of drives
if [ ${#DEVICES_01[@]} -gt 3 ]; then
echo " raidz1 ${DEVICES_01[@]} \ "
fi
echo -e "\n"
echo "if you would rather have one big raidz2 vdev..."
# base command
echo "zpool create mach2tank -o ashift=12 \ "
# raidz2 or 3 is an option for these drives which does NOT require more than one vdev
echo " raidz2 ${DEVICES_00[@]} \ "
echo " ${DEVICES_01[@]} \ "
echo -e "\n\n"
echo " For additional redundancy you could use raidz2 with 2 devs, raidz3 with 1 vdev, and so on. "
echo " You can use the output above to make a manual selection about vdevs and device mapping as well."
for my 12 drive setup that creates:
# zpool create mach2tank -o ashift=12 \
> raidz1 /dev/disk/by-id/wwn-0x6000c500d8e7532b0000000000000000 /dev/disk/by-id/wwn-0x6000c500d8fdffdf0000000000000000 /dev/disk/by-id/wwn-0x6000c500d921f10b0000000000000000 /dev/disk/by-id/wwn-0x6000c500d925b4a30000000000000000 /dev/disk/by-id/wwn-0x6000c500d956405f0000000000000000 /dev/disk/by-id/wwn-0x6000c500d9564dbf0000000000000000 /dev/disk/by-id/wwn-0x6000c500d956ac330000000000000000 /dev/disk/by-id/wwn-0x6000c500d99817cb0000000000000000 /dev/disk/by-id/wwn-0x6000c500d9a507cf0000000000000000 /dev/disk/by-id/wwn-0x6000c500d9a512230000000000000000 /dev/disk/by-id/wwn-0x6000c500d9a8d9b70000000000000000 /dev/disk/by-id/wwn-0x6000c500d9ff3c5b0000000000000000 \
> raidz1 /dev/disk/by-id/wwn-0x6000c500d8e7532b0001000000000000 /dev/disk/by-id/wwn-0x6000c500d8fdffdf0001000000000000 /dev/disk/by-id/wwn-0x6000c500d921f10b0001000000000000 /dev/disk/by-id/wwn-0x6000c500d925b4a30001000000000000 /dev/disk/by-id/wwn-0x6000c500d956405f0001000000000000 /dev/disk/by-id/wwn-0x6000c500d9564dbf0001000000000000 /dev/disk/by-id/wwn-0x6000c500d956ac330001000000000000 /dev/disk/by-id/wwn-0x6000c500d99817cb0001000000000000 /dev/disk/by-id/wwn-0x6000c500d9a507cf0001000000000000 /dev/disk/by-id/wwn-0x6000c500d9a512230001000000000000 /dev/disk/by-id/wwn-0x6000c500d9a8d9b70001000000000000 /dev/disk/by-id/wwn-0x6000c500d9ff3c5b0001000000000000 \
>
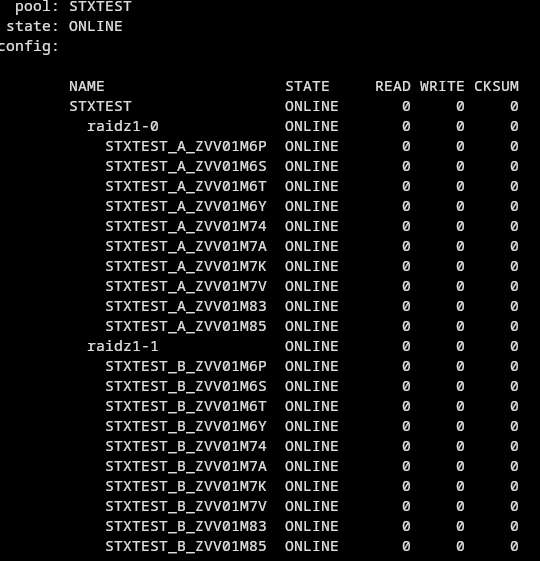
[root@storinator ~]# zpool status
pool: mach2tank
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
mach2tank ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
wwn-0x6000c500d8e7532b0000000000000000 ONLINE 0 0 0
wwn-0x6000c500d8fdffdf0000000000000000 ONLINE 0 0 0
wwn-0x6000c500d921f10b0000000000000000 ONLINE 0 0 0
wwn-0x6000c500d925b4a30000000000000000 ONLINE 0 0 0
wwn-0x6000c500d956405f0000000000000000 ONLINE 0 0 0
wwn-0x6000c500d9564dbf0000000000000000 ONLINE 0 0 0
wwn-0x6000c500d956ac330000000000000000 ONLINE 0 0 0
wwn-0x6000c500d99817cb0000000000000000 ONLINE 0 0 0
wwn-0x6000c500d9a507cf0000000000000000 ONLINE 0 0 0
wwn-0x6000c500d9a512230000000000000000 ONLINE 0 0 0
wwn-0x6000c500d9a8d9b70000000000000000 ONLINE 0 0 0
wwn-0x6000c500d9ff3c5b0000000000000000 ONLINE 0 0 0
raidz1-1 ONLINE 0 0 0
wwn-0x6000c500d8e7532b0001000000000000 ONLINE 0 0 0
wwn-0x6000c500d8fdffdf0001000000000000 ONLINE 0 0 0
wwn-0x6000c500d921f10b0001000000000000 ONLINE 0 0 0
wwn-0x6000c500d925b4a30001000000000000 ONLINE 0 0 0
wwn-0x6000c500d956405f0001000000000000 ONLINE 0 0 0
wwn-0x6000c500d9564dbf0001000000000000 ONLINE 0 0 0
wwn-0x6000c500d956ac330001000000000000 ONLINE 0 0 0
wwn-0x6000c500d99817cb0001000000000000 ONLINE 0 0 0
wwn-0x6000c500d9a507cf0001000000000000 ONLINE 0 0 0
wwn-0x6000c500d9a512230001000000000000 ONLINE 0 0 0
wwn-0x6000c500d9a8d9b70001000000000000 ONLINE 0 0 0
wwn-0x6000c500d9ff3c5b0001000000000000 ONLINE 0 0 0
errors: No known data errors
Perfecto! It’s raidz1, but even though its raidz1, it’s still fully redundant. You don’t have to use the wwn devices, but there is no harm in it.
Let’s pull a drive!

[root@storinator ~]# zpool status
pool: mach2tank
state: DEGRADED
status: One or more devices could not be used because the label is missing or
invalid. Sufficient replicas exist for the pool to continue
functioning in a degraded state.
action: Replace the device using 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-4J
scan: scrub repaired 0B in 00:00:01 with 0 errors on Sun May 14 03:42:13 2023
config:
NAME STATE READ WRITE CKSUM
mach2tank DEGRADED 0 0 0
raidz1-0 DEGRADED 0 0 0
wwn-0x6000c500d8e7532b0000000000000000 ONLINE 0 0 0
wwn-0x6000c500d8fdffdf0000000000000000 ONLINE 0 0 0
wwn-0x6000c500d921f10b0000000000000000 ONLINE 0 0 0
wwn-0x6000c500d925b4a30000000000000000 ONLINE 0 0 0
wwn-0x6000c500d956405f0000000000000000 ONLINE 0 0 0
wwn-0x6000c500d9564dbf0000000000000000 ONLINE 0 0 0
wwn-0x6000c500d956ac330000000000000000 ONLINE 0 0 0
wwn-0x6000c500d99817cb0000000000000000 ONLINE 0 0 0
wwn-0x6000c500d9a507cf0000000000000000 ONLINE 0 0 0
wwn-0x6000c500d9a512230000000000000000 ONLINE 0 0 0
wwn-0x6000c500d9a8d9b70000000000000000 UNAVAIL 0 0 0
wwn-0x6000c500d9ff3c5b0000000000000000 ONLINE 0 0 0
raidz1-1 DEGRADED 0 0 0
wwn-0x6000c500d8e7532b0001000000000000 ONLINE 0 0 0
wwn-0x6000c500d8fdffdf0001000000000000 ONLINE 0 0 0
wwn-0x6000c500d921f10b0001000000000000 ONLINE 0 0 0
wwn-0x6000c500d925b4a30001000000000000 ONLINE 0 0 0
wwn-0x6000c500d956405f0001000000000000 ONLINE 0 0 0
wwn-0x6000c500d9564dbf0001000000000000 ONLINE 0 0 0
wwn-0x6000c500d956ac330001000000000000 ONLINE 0 0 0
wwn-0x6000c500d99817cb0001000000000000 ONLINE 0 0 0
wwn-0x6000c500d9a507cf0001000000000000 ONLINE 0 0 0
wwn-0x6000c500d9a512230001000000000000 ONLINE 0 0 0
wwn-0x6000c500d9a8d9b70001000000000000 UNAVAIL 0 0 0
wwn-0x6000c500d9ff3c5b0001000000000000 ONLINE 0 0 0
errors: No known data errors
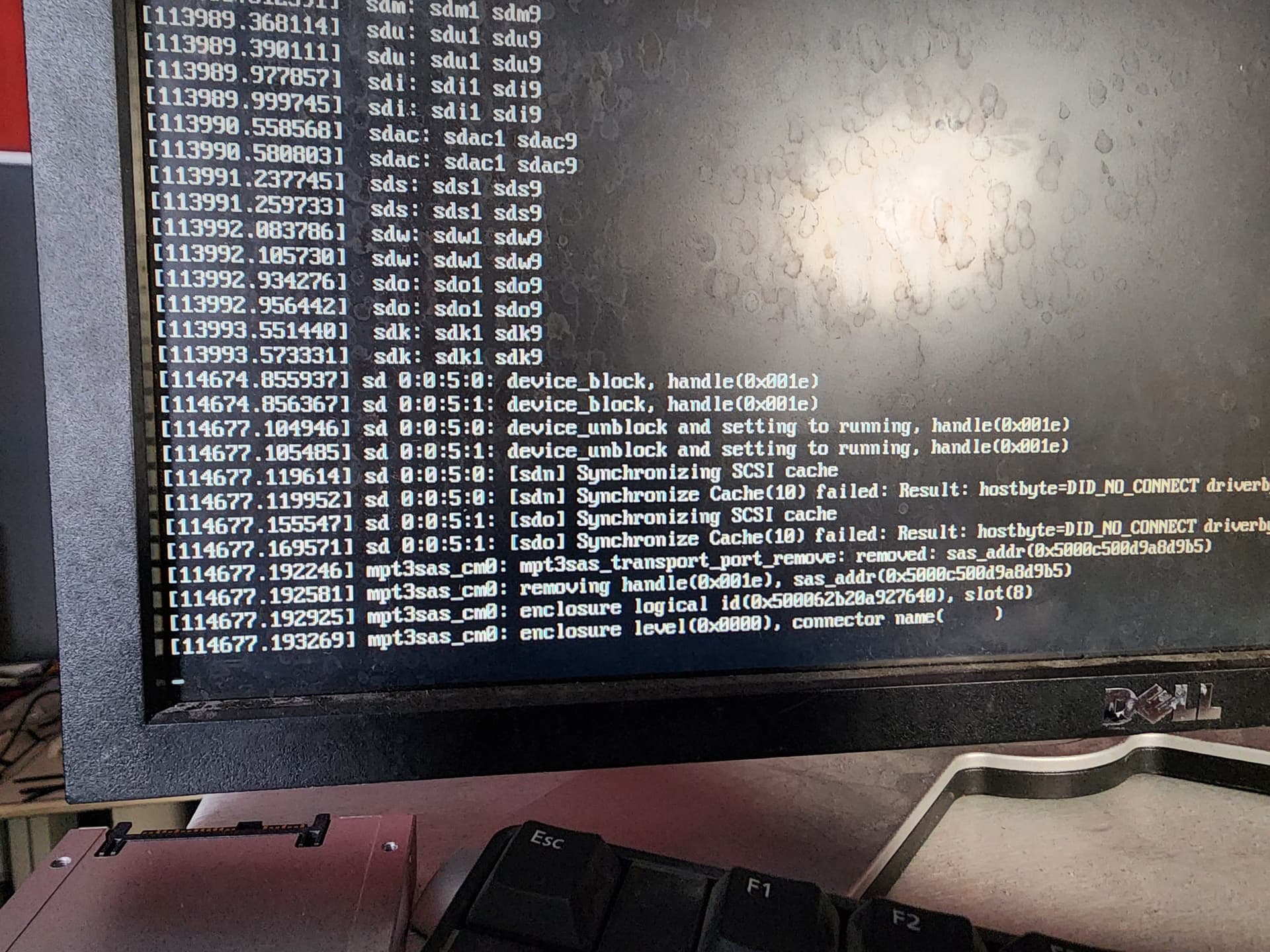
With just one drive pulled, the pool is still operational, and exactly one component is missing from each vdev. Even though technically we’ve suffered two failures our zfs pool is still fully operational since the failures are guaranteed to be spread across more than one vdev with this setup method.
What about SATA drives?
SATA drives can’t present as two logical units, so you have to use partitions to get the extra speed. See below for the post from John-S
Performance
The performance of this array is quite good, even with just two raidz1 vdevs:
2147479552 bytes (2.1 GB, 2.0 GiB) copied, 0.967566 s, 2.2 GB/s
for sequential read and write. This would nearly saturate a 25 gigabit ethernet connection. With some performance tuning and giving up a little more space for redundancy, it is possible to achieve nearly 5 gigabytes per second performance from just 12 mechanical drive. Record breaking, I’m sure.