Intro
In this guide I’m going to walk you through setting up the Proxmox virtualization environment, but a lot of the advice here applies if you are going to use VMWare or Windows 2019 as your host operating system.
Our system is configured for 256 threads – dual 64 core Epyc CPUs – so it’s a beast for prettymuch everything. With this many cores & threads, the highest and best use of this type of hardware is generally going to be a virtualization server. For things like Kubernetes on bare metal, it would also work well.
Note: For Windows as the host OS I strongly recommend Windows Server 2019, or later. Windows may also benefit from disabling SMT because, in general, Windows doesn’t really handle 128 threads per socket well at all in my testing. Your mileage may vary, of course, and for virtualization type workloads it may matter less than, say, SQL Server or IIS running on the host.
Our Config
The chassis is the
GIGABYTE R282-Z93
2 x EPYC 7742 CPUs
NVIDIA Tesla V100 32gb (For machine learning/CUDA tests)
512gb ram (16x32gb)
4x 8tb WD Red
256gb Sata SSD
2x1tb NVME
Memory Note: I used a few different memory configs for the video which is testing the impact of 2666/2933/3200 Registered ECC memory with Epyc. To summarize: Use the fastest memory that you possibly can with your Epyc system.
This chassis is configured for 12x 3.5" bulk storage, with the fast NVMe storage being configured as riser cards like the Liqid HHL. Chassis configured as 24x NVMe are available.
In general, I would recommend moving any type of mechanical/spinning rust type storage to an external disk shelf.
Inside the BIOS/UEFI
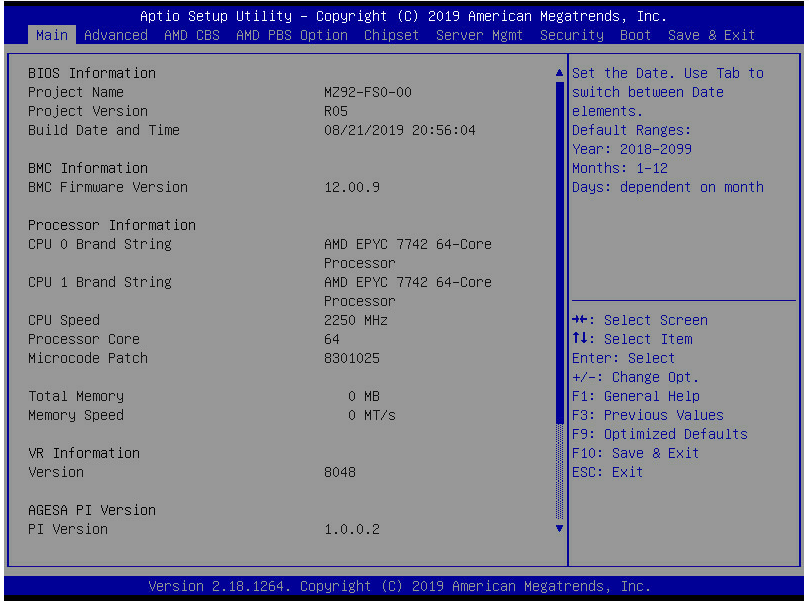
More POWERRRRRR [ AMD CBS > NB Common Options > SMU Options ]
The first thing you should absolutely do is set the cTDP on your Epyc CPUs to 240w. By default they’re configured for 225w and the extra bump in wattage makes them somewhat less power efficient, but they will be measurably faster. If you’re using this guide as a rough guide with another system not from GIGABYTE, it is possible this option is locked out for you and not supported.
I am not sure why, but on an older UEFI I had to set 480w on a 2 socket system to get 2x240w. I don’t think that’s the case anymore, though.
The Determinism Control is also useful if you prefer performance vs energy efficiency.
Prefer I/O?
If you are going to run a “full NVMe” config it seems like there is a wall around 28 gigabytes/sec when using 2933Mhz memory. I believe, but am not sure, this has something to do with the memory prefetcher constantly prefetching and using infinity fabric bandwidth. As such there is a UEFI option to configure an “I/O Priority” which will make the prefetcher a bit less aggressive, and with this option set I can get another 10 gigabytes/sec read performance from the NVMe array.
For my testing I used 12x Intel DC P4500 4.0TB SSDs. This array can easily clear 35 gigabytes/sec raw read throughput.
Overclocking!?
Not really. Well, kinda? You can overclock the infinity fabric, which might help you if you have really slow memory. You have to do some trickery with the SMU to really do true overclocking, but almost all Epyc motherboards top out around 350w per socket, so you don’t have much headroom anyway (4.4ghz all core on a Threadripper 3970X will consume about ~750w for comparison). Mostly you don’t need to worry about this, but I mention it because of two options: Gear Down Mode and Cmd2T. Disabling Gear Down Mode and making sure Cmd2T is disabled can improve memory performance significantly. CMD2t is required for some memory kits – in general steer clear of those, though. For you to enjoy the best performance on Epyc, you must pair it with the best memory.
PCIe Options? [AMD CBS > NBIO Common Options]
So I have some older/wonkier peripherals and PCIe ARI support has to be disabled for those peripherals. It seems it shuffles around what bits are used for downstream devices and is enabled by default on some bioses. I think AMD has moved to disable it by default in more recent bioses, but if you are experiencing issues (such as a multi-function device not showing up properly) try changing PCIe ARI Support, 10 bit tag support and ACS.
ACS and IOMMU go together – you may have to enable both of them for the best possible IOMMU layouts. I generally disable ARI support explicitly.
I would love more documentation about how these work, and what they do…
Chipset [ Chipset ]
There are some more PCIe options here. “Compliance Mode: Off” sounds fishy, especially for older PCIe cards that are notoriously grumpy. Be aware of these options if you’re using older PCIe devices.
OS Ready
We are now ready for the OS installation.
The installation is straightforward. You can use the IPMI to load the ISO, or make a USB stick. The IPMI is quite a bit slower install process than the USB stick option, but I tested both without issue or any caveats or notes to share.
ZFS & Proxmox = Panics?
ZFS is a great resillient filesystem. In general I highly recommend it.
I set it up as part of our “get the most out of GIGABYTE/Epyc” server video, but there are sometimes issues.
I was helping LTT and was disturbed to find kernel panics. Okay, well not full panics, warnings, but ZFS performance absolutely tanks when this happens, so it is not acceptable. It’s a known issue, and I would not consider it harmless. So the [SOLVED] there is not really solved, imho.
As of December 27, it is fixed upstream, but hasn’t trickled down to Proxmox Updates (yet) at the time of this writing.
How do you know if you are having this issue? Run dmesg from the Proxmox console while doing heavy file/IO operations. If you see warnings and debug information, you’re affected. The bad news is that if you have this issue, your I/O performance to the ZFS pool is going to be utter crap (at least, in the two configs I’ve tested with Proxmox VE 6.1). Your options are to install an older kernel, apply the patch from github, or wait for the github patch to be mainstreamed into Proxmox updates. ( I am expecting the patch to be available via apt update no later than January 20, 2020…)
Tuning Proxmox for Performance
TODO
Remember, this system is a MONSTER. On VMWare, I was able to consolidate 20 1p and 2p Xeon 26xx series systems into a single box. As such, it is new bleeding-edge hardware and there are some tweaks you can do to improve responsiveness of the system when switching between heavily-loaded VMs.
This resource should also be bookmarked and inspected periodically.
https://pve.proxmox.com/wiki/Performance_Tweaks
Kernel Parameters
sysctl-proxmox-tune.conf
After doing some testing on the GIGABYTE Chassis, with 256 threads, here’s what I’d recommend for Kernel parameters:
# https://tweaked.io/guide/kernel/
# Don't migrate processes between CPU cores too often
kernel.sched_migration_cost_ns = 5000000
# Kernel >= 2.6.38 (ie Proxmox 4+)
kernel.sched_autogroup_enabled = 0
# Don't slow network - save congestion window after idle
# https://github.com/ton31337/tools/wiki/tcp_slow_start_after_idle---tcp_no_metrics_save-performance
net.ipv4.tcp_slow_start_after_idle = 0
# try not to swap
vm.swappiness = 1
# max # connections
net.core.somaxconn = 512000
net.ipv6.conf.all.disable_ipv6 = 1
# https://www.serveradminblog.com/2011/02/neighbour-table-overflow-sysctl-conf-tunning/
net.ipv4.neigh.default.gc_thresh1 = 1024
net.ipv4.neigh.default.gc_thresh2 = 2048
net.ipv4.neigh.default.gc_thresh3 = 4096
# close TIME_WAIT connections faster
net.ipv4.tcp_fin_timeout = 10
net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 15
# more ephermeral ports
net.ipv4.ip_local_port_range = 10240 61000
# https://major.io/2008/12/03/reducing-inode-and-dentry-caches-to-keep-oom-killer-at-bay/
vm.vfs_cache_pressure = 10000
Scheduler
# https://tweaked.io/guide/kernel/
# Don't migrate processes between CPU cores too often
kernel.sched_migration_cost_ns = 5000000
# Kernel >= 2.6.38 (ie Proxmox 4+)
kernel.sched_autogroup_enabled = 0
You can do some experiments, but with Epyc, in the default config, is one NUMA node per socket. There is a hidden cost for moving processes around cores even within one socket, however. You CAN expose 4 “near” nodes per socket with a UEFI setting, but generally it isn’t necessary. The better fix, IMHO, is to just tell proxmox not to try to move processes around unless it really needs to.
ZFS Cache
Adjust zfs cache pressure so that ZFS ARC consumes 1/4 to 1/3 your available ram, at most. This may be something your monitor and adjust over time.
Networking
The GIGABYTE chassis has the option for OCP3 mezzanine cards. This works with everything from dual 10 gig adapters up through Intel’s new 400 gig standard. For Intel-based nics, generally no tuning is required. If you have Mellanox adapters that you plan to use, some tuning is recommended.
Here are the settings we used for the Level1 Video Storage Server:
TODO
Samba
If you plan to use Samba with your new server, Enable SMB Multichannel (see our other vid on that).
Migrated VMs
For our migration, we first did full machine migrations. There is an important distinction between full virtualization and containers, however – containers are much lighter. If you have a VM running a simple job such as Webserver, Database server, etc consider whether that job could be performed via a container of some type. Promox supports Docker and other containerization technologies. Because containers have a fraction of the overhead of a full virtual machine, you can efficiently run a lot more of them on a single host.
For our migration & consolidation, we did an evaluation of what the virtual machine was doing. Could it be combined with another VM? Could it be containerized to lower the maintenance requirement? We had a few Python and PHP applications that fit the bill – so we converted them to containers. This may be an option for you.

 ) for all this very useful info!
) for all this very useful info!

