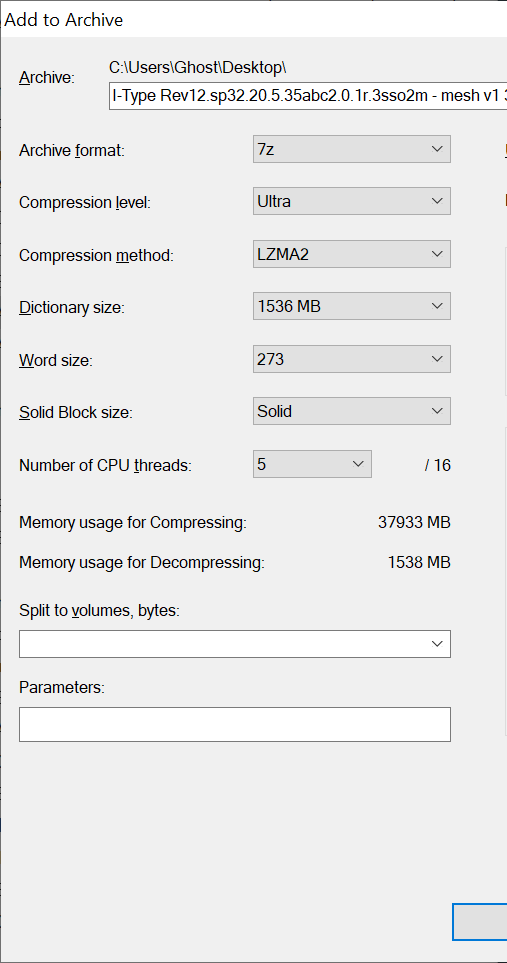
I feel kind of dumb I never noticed this sooner, but I just realized when I vary the thread count used to compress files, their compression ratio wildly varies.
I have a series of 130GB mostly sparse matrix files that will compress down to 34.2GB if I use 5 threads to compress and down to 16.5GB is I use 3 threads on a solid block, 1.5GB dictionary sized lzma2 compression algorithm.
It would be helpful to specify what program you are using specifically, and maybe the exact command that you are using (assuming this is on the command line) and/or the configuration of the program you are using.
If you can afford to rerun the test at other thread counts, that would be useful information, on the off chance that only 5 threads triggers this bug. It would also give a better sense of trend here; for example, if reduced threads really do increase compression, is a setting of 2 or 1 thread even better?
I do not have a Windows install to play with at the moment, so I will be mainly speculating here.
What currently piques my interest is the memory usage statistic. ~38000 MiB (37 GiB) is a substantial amount of RAM; is there a chance that multiple threads is leaving each thread more RAM-constrained than before? How much RAM do you have? How much is used by the 7zip process or processes during compression?
If your processes are being starved for RAM, I imagine under a certain thread limit the compressed result will stay constant, but above that, the resulting file will continue to increase in size as the thread count increases.
Please be aware that with LZMA as well, I have no expert knowledge, I am merely speculating off of general knowledge; if I made a compression program, silently changing the amount of compression in response to RAM constraints would not be an acceptable feature.
The gui to 7zip is pretty cool, it’ll give you fairly accurate estimates of memory used to compress and decompress as one plays with the compression settings.
The Ram usage to compress is mostly a function of the dictionary size and thread count. That ~38GB to compress with 5 threads is accurate, it really takes that much memory to compress with that large of a dictionary. I only have 64GB of ram on the machine I was compressing with and if I run out of ram during compression the process quits.
I was changing compression settings in response to how much free ram I had at a given time… which is why I compressed with a reduced thread count and noticed this seemingly strange behavior.
This makes logical sense to me, I figured this must be why ram usage goes up linearly with the number of threads used to compress… but then the results (end compression ratio) between different thread counts ended up being different which is what surprised me.
After doing this I thought to actually try compression on smaller files so I would get results in a more reasonable amount of time and lo and behold thread count isn’t affecting the final compression size when I try to compress a copy of libreoffice… I guess there is something particular to this type of dataset going on.
Most compression algorithms perform multithreaded compression by splitting the file into chunks, and compressing the individual chunks. This usually means they have different dictionaries, and your compression ratio will suffer to a degree. For large files the ratio reduction is usually insignificant.
This is the only documentation for 7z that I can find referencing this behaviour -m (Set compression Method) switch. It might explain what you’re seeing above.
I’d also suggest you give zstd a go, it’s a more modern compression program with some interesting changes in how it handles things. Though in practise I find xz / lzma always beats it at max settings. Zstd is usually faster for a given output size.
You’ll find that application-specific encoding / compression will almost always beat general compression algorithms. If you’re talking about a sparse mathematical matrix, a file listing coordinates and values will probably be the smallest encoding you can get. If your program can’t output this, you might need to write your own. If you mean some other kind of matrix then could you give us more details?
Other techniques might be run length encoding for columns and/or rows if there are lots of zeros.
I gave zstd a try, you’re right it is faster, but it only reached a 50.3% compression ratio (at level 22) as opposed to LZMA2 at 12.7% (when <3 threads) on the 130GB sparse matrix file.
Yes, these are largish sparse mathematical matrices, but there are multiple evolutions of the same geometric matrix in the file, which really lend to being compressed since the zeros between the different evolutions of the geometric matrices almost always align. These files will only ever be uncompressed and looked at if I need to go back into them to extract more subtle convergence data, so I won’t be accessing them readily which is why I wanted to compress them as much as possible since I have many hundreds of these files.
The issue is specific to the LZMA2 compression method (possibly others?) and the manual mentions the superior behavior happening in 1-2 threads (even though 3 threads seems to be the cut off for me, I think this is the same mechanism). From my limited understanding on the way the compression works: It’s not that the mode is changing between thread counts, its that the way the data is chunked into work packages for the CPU to process changes between thread counts.
LZMA2 uses: 1 thread for each chunk in x1 and x3 modes; and 2 threads for each chunk in x5, x7 and x9 modes. If LZMA2 is set to use only such number of threads required for one chunk, it doesn’t split stream to chunks. So you can get different compression ratio for different number of threads. You can get the best compression ratio, when you use 1 or 2 threads.