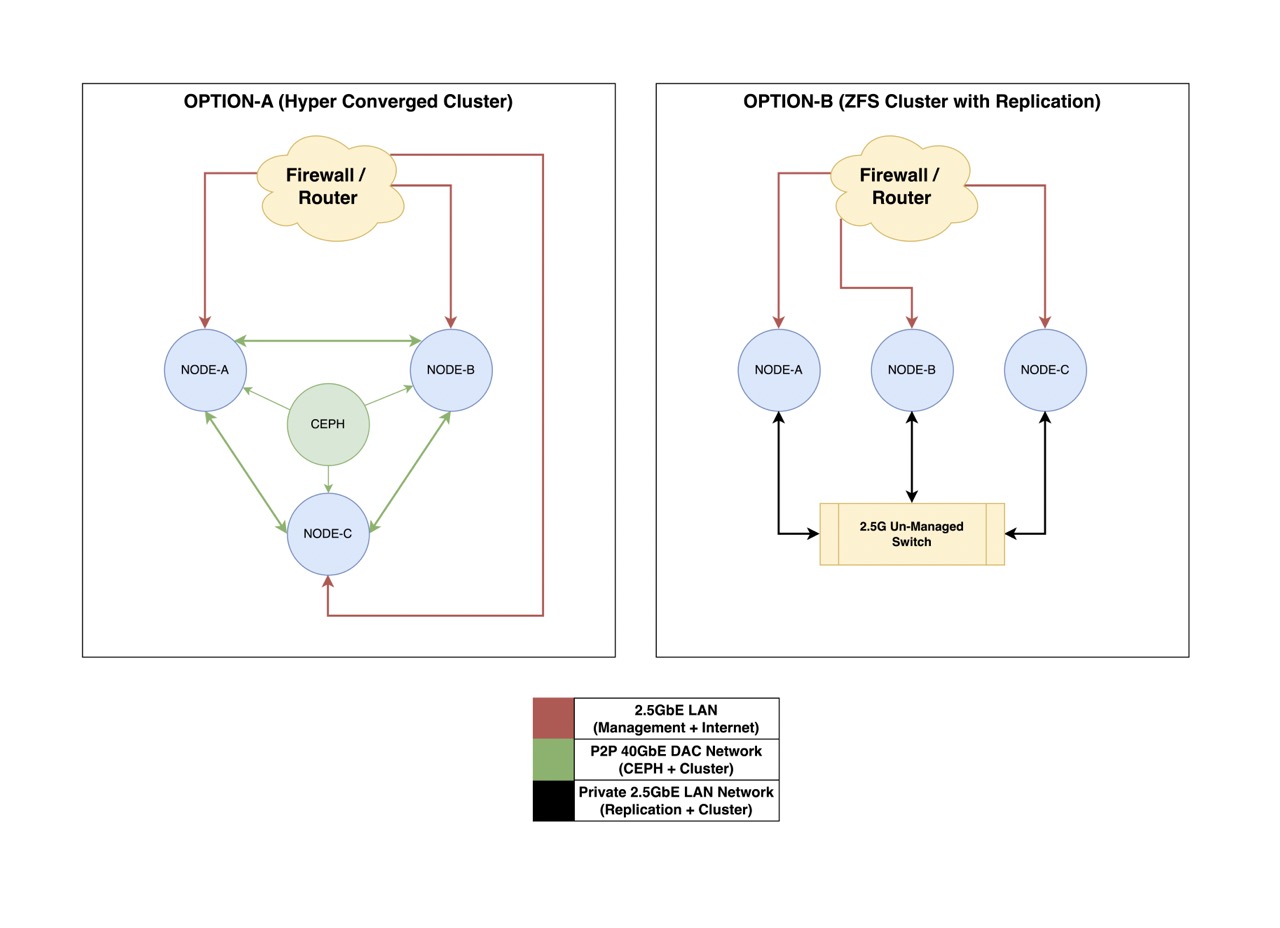
If performance doesn’t matter (even a slow ceph can satisfy a decent amount of workload), but you want the redundancy (and the fanciness) of hyperconverged clusters, go with Ceph. If you want performance, go with option C.
Option B will be very manual and replicating and balancing the data will be a struggle, even with ZFS send. With 2 nodes, it wouldn’t be a big deal, but with 3, that’s a bit much. Say you have 6 servers:
- 1 and 2 run on A: 1 gets replicated to B and 2 to C
- 3 and 4 run on B: 3 gets replicated to A and 4 to C
- 5 and 6 run on C: 5 gets replicated to A and 6 to B
This is the best configuration when it comes to both resource and storage load balancing, because if 1 node fails, the load gets distributed equally on the other 2.
Even if we’re being generous and say you have enough resources for a single server to handle the loads of 2 (which is a complete waste of idle resources) and say you replicate all the services from A to B, B to C and C to A, it’s still going to be a manual procedure configuring them.
Option C.
Get 3 hypervisor hosts and 2 NASes. Replicate the ZFS pool from one NAS to the other. Trust me™, I’ve ran more than 2 dozen VMs off of a single md RAID 10 spinning rust on HP proliant microservers gen 8s and they were still working well (heck, I had one of these with Samsung 860 Pros in RAID 10 and the CPU and the 8 GB of RAM weren’t even used and the SSDs weren’t even sweating - on a bond mode 6 on 2x giagbit NICs).
Have all the services run from a single NAS and in case one fails, have the other failover. If you’re feeling fancy, you can also load balance them by splitting half the services to run on one share in NAS 1 and the other half in another share in NAS 2. Both shares get replicated to each other.
While I haven’t tried this, you could probably just use NFS shares on a VIP and using something like keepalived, do a hot failover to the other NAS. But someone with more experience needs to show their thoughts (or you should test in a VM as a POC before building all this). Otherwise, you might need to use corosync and pacemaker and make the 3 proxmox hosts just voters in the quorum between the 2 NASes (all of them will obviously vote the same, because it’s just an OR statement when one NAS is down - then you can have a hard rule to prefer NAS 1 for share 1 and NAS 2 for share 2).
Now, the question with replication comes to mind: how will the hypervisor handle a share migration to another NAS when a VM or container is running? How about the services themselves? I’ve no experience with this, but I can guarantee with Ceph it wouldn’t be an issue.
If you pull the rug from under NAS 1, I think it will be enough of a delay for NAS 2 to become the active one for the share 1, that either the service will crash or error out because of a failed read or write (or worse, kernel panic), or the hypervisor will be smart enough to notice the failed read or write, the missing access to the share and pause/suspend the VM. On the resume after the delay, typically hypervisors are smart enough to resume the VM, but I was never faced with such a scenario. Live migration from a host to another, or simple disk migration from a NAS to another wasn’t a problem in proxmox, it was smart enough to pause and resume the VM just in time to have everything synced up - but not sure how it handles unexpected rug pulls.
Option C is easier to handle than B when it comes to replication and load balancing, but you need more hardware for it. Thankfully, the hardware doesn’t need to be very fast, a stripped zfs mirror will behave well on any low end hardware. With the SSDs, you might need something beefier to keep up though.
Conclusion time. A Ceph cluster will basically ensure that data is always accessible at all time from any host. Option B or C, with replicated storage, is not entirely certain what will happen when the active storage goes down (at least to my knowledge, I’d love for someone to educate me). But in my experience, this happens way less frequently than hypervisors going down, which happen less frequently than the service misbehaving randomly.