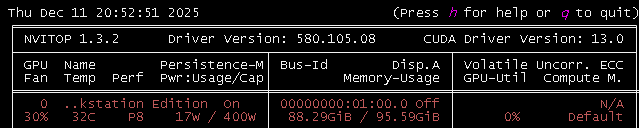
Hello everyone!
I’m trying to debug a strange NCCL P2P infinite hang on my new WRX90 workstation with 2× RTX PRO 6000 Blackwell Max Q. Maybe I am doing something completely wrong?
PyTorch CUDA P2P via torch.cuda.can_device_access_peer( ) returns true in both directions; NCCL test with P2P disabled also works fine, but NCCL with P2P enabled consistently hangs on the first collective, even after disabling ACS in BIOS.
I’d really appreciate any insight from people who have more experience with NCCL, or maybe someone has already overcome this issue.
Hardware
- CPU: AMD Ryzen Threadripper PRO 9965WX
- Motherboard: ASUS WRX90E-SAGE SE, BIOS with ACS disabled in setup
- GPUs: 2× NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition
- GPU0: PCI bus
0000:c1:00.0| VBIOS98.02.6A.00.03 - GPU1: PCI bus
0000:f1:00.0| VBIOS98.02.6A.00.03
- GPU0: PCI bus
GPUs work in PCIe Gen 5 x 16 mode. Resizable BAR and IOMMU are enabled. I also tried different PCIe slot combinations, but nothing worked for me.
GPU Topology via nvidia-smi topo -m:
GPU0 GPU1 CPU Affinity NUMA Affinity GPU NUMA ID
GPU0 X NODE 0-47 0 N/A
GPU1 NODE X 0-47 0 N/A
Software
- OS: Ubuntu 24.04
- Kernel:
6.14.0-29-generic - NVIDIA driver:
580.95.05 - CUDA version:
13.0(as reported bynvidia-smi) nvccreports:
nvcc: NVIDIA (R) Cuda compiler driver
Cuda compilation tools, release 13.0, V13.0.88
Build cuda_13.0.r13.0/compiler.36424714_0
NCCL built from current github master:
=== NCCL packages ===
ii libnccl-dev 2.28.9-1+cuda13.0 amd64 NVIDIA Collective Communication Library (NCCL) Development Files
ii libnccl2 2.28.9-1+cuda13.0 amd64 NVIDIA Collective Communication Library (NCCL) Runtime
ii libvncclient1:amd64 0.9.14+dfsg-1build2 amd64 API to write one's own VNC server - client library
libcuda / libnccl symlinks:
=== libcuda / libnccl symlinks ===
lrwxrwxrwx 1 root root 12 Oct 1 12:17 /usr/lib/x86_64-linux-gnu/libcuda.so -> libcuda.so.1
lrwxrwxrwx 1 root root 20 Oct 1 12:17 /usr/lib/x86_64-linux-gnu/libcuda.so.1 -> libcuda.so.580.95.05
-rw-r--r-- 1 root root 96276264 Oct 1 12:17 /usr/lib/x86_64-linux-gnu/libcuda.so.580.95.05
lrwxrwxrwx 1 root root 12 Dec 12 00:28 /usr/lib/x86_64-linux-gnu/libnccl.so -> libnccl.so.2
lrwxrwxrwx 1 root root 17 Dec 12 00:28 /usr/lib/x86_64-linux-gnu/libnccl.so.2 -> libnccl.so.2.28.9
-rw-r--r-- 1 root root 189918680 Dec 12 00:28 /usr/lib/x86_64-linux-gnu/libnccl.so.2.28.9
PyTorch: 2.9.1+cu130 (official cu130 wheels)
nccl-tests: current GitHub (nccl-tests version 2.17.6).
What works:
- Simple PyTorch P2P test between GPU0 and GPU1:
import torch
print("Torch:", torch.__version__)
print("torch.version.cuda:", torch.version.cuda)
print("CUDA available:", torch.cuda.is_available())
print("Device count:", torch.cuda.device_count())
for i in range(torch.cuda.device_count()):
p = torch.cuda.get_device_properties(i)
print(f"GPU {i}: {p.name}, {p.total_memory/1024**3:.1f} GB, CC {p.major}.{p.minor}")
print("P2P 0->1:", torch.cuda.can_device_access_peer(0, 1))
print("P2P 1->0:", torch.cuda.can_device_access_peer(1, 0))
returns correct information:
=== CUDA P2P test via PyTorch ===
Torch: 2.9.1+cu130
torch.version.cuda: 13.0
CUDA available: True
Device count: 2
GPU 0: NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition, 95.0 GB, CC 12.0
GPU 1: NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition, 95.0 GB, CC 12.0
P2P 0->1: True
P2P 1->0: True
2.NCCL single-GPU all_reduce (g=1) both P2P enabled or disabled
Executing ./build/all_reduce_perf -b 8 -e 64M -f 2 -g 1 works wihout issues
# nccl-tests version 2.17.6 nccl-headers=22809 nccl-library=22809
# Collective test starting: all_reduce_perf
# nThread 1 nGpus 1 minBytes 8 maxBytes 67108864 step: 2(factor) warmup iters: 1 iters: 20 agg iters: 1 validation: 1 graph: 0
#
# Using devices
# Rank 0 Group 0 Pid 10657 on wlad-hedt device 0 [0000:c1:00] NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition
NCCL version 2.28.9+cuda13.0
#
# out-of-place in-place
# size count type redop root time algbw busbw #wrong time algbw busbw #wrong
# (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s)
8 2 float sum -1 2.62 0.00 0.00 0 0.09 0.08 0.00 0
16 4 float sum -1 2.64 0.01 0.00 0 0.10 0.16 0.00 0
32 8 float sum -1 2.58 0.01 0.00 0 0.10 0.33 0.00 0
64 16 float sum -1 2.58 0.02 0.00 0 0.10 0.65 0.00 0
128 32 float sum -1 2.58 0.05 0.00 0 0.10 1.33 0.00 0
256 64 float sum -1 2.60 0.10 0.00 0 0.10 2.60 0.00 0
512 128 float sum -1 2.56 0.20 0.00 0 0.09 5.50 0.00 0
1024 256 float sum -1 2.63 0.39 0.00 0 0.10 10.59 0.00 0
2048 512 float sum -1 2.68 0.76 0.00 0 0.09 22.24 0.00 0
4096 1024 float sum -1 2.62 1.56 0.00 0 0.09 43.74 0.00 0
8192 2048 float sum -1 2.59 3.16 0.00 0 0.09 87.99 0.00 0
16384 4096 float sum -1 2.62 6.25 0.00 0 0.06 272.61 0.00 0
32768 8192 float sum -1 2.57 12.74 0.00 0 0.06 532.38 0.00 0
65536 16384 float sum -1 2.62 25.00 0.00 0 0.06 1090.4 0.00 0
131072 32768 float sum -1 2.82 46.49 0.00 0 0.09 1392.2 0.00 0
262144 65536 float sum -1 2.87 91.43 0.00 0 0.14 1817.9 0.00 0
524288 131072 float sum -1 3.03 173.32 0.00 0 0.09 5628.4 0.00 0
1048576 262144 float sum -1 3.06 342.21 0.00 0 0.10 10963 0.00 0
2097152 524288 float sum -1 3.30 636.28 0.00 0 0.10 20520 0.00 0
4194304 1048576 float sum -1 4.79 875.97 0.00 0 0.10 41880 0.00 0
8388608 2097152 float sum -1 6.78 1238.0 0.00 0 0.10 84605 0.00 0
16777216 4194304 float sum -1 9.69 1731.7 0.00 0 0.09 181082 0.00 0
33554432 8388608 float sum -1 16.76 2002.5 0.00 0 0.17 198254 0.00 0
67108864 16777216 float sum -1 31.30 2144.2 0.00 0 0.06 1e+06 0.00 0
# Out of bounds values : 0 OK
# Avg bus bandwidth : 0
#
# Collective test concluded: all_reduce_perf
3.NCCL multi-GPU all_reduce with P2P disabled (g=2, NCCL_P2P_DISABLE=1)
Works as expected
# nccl-tests version 2.17.6 nccl-headers=22809 nccl-library=22809
# Collective test starting: all_reduce_perf
# nThread 1 nGpus 2 minBytes 8 maxBytes 67108864 step: 2(factor) warmup iters: 1 iters: 20 agg iters: 1 validation: 1 graph: 0
#
# Using devices
# Rank 0 Group 0 Pid 10695 on wlad-hedt device 0 [0000:c1:00] NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition
# Rank 1 Group 0 Pid 10695 on wlad-hedt device 1 [0000:f1:00] NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition
NCCL version 2.28.9+cuda13.0
#
# out-of-place in-place
# size count type redop root time algbw busbw #wrong time algbw busbw #wrong
# (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s)
8 2 float sum -1 7.32 0.00 0.00 0 7.21 0.00 0.00 0
16 4 float sum -1 15.18 0.00 0.00 0 10.83 0.00 0.00 0
32 8 float sum -1 17.41 0.00 0.00 0 12.91 0.00 0.00 0
64 16 float sum -1 10.57 0.01 0.01 0 16.86 0.00 0.00 0
128 32 float sum -1 17.19 0.01 0.01 0 7.79 0.02 0.02 0
256 64 float sum -1 7.42 0.03 0.03 0 8.39 0.03 0.03 0
512 128 float sum -1 8.15 0.06 0.06 0 8.43 0.06 0.06 0
1024 256 float sum -1 8.41 0.12 0.12 0 8.38 0.12 0.12 0
2048 512 float sum -1 8.35 0.25 0.25 0 8.42 0.24 0.24 0
4096 1024 float sum -1 8.45 0.48 0.48 0 8.36 0.49 0.49 0
8192 2048 float sum -1 8.66 0.95 0.95 0 8.65 0.95 0.95 0
16384 4096 float sum -1 8.67 1.89 1.89 0 8.66 1.89 1.89 0
32768 8192 float sum -1 9.75 3.36 3.36 0 18.54 1.77 1.77 0
65536 16384 float sum -1 12.25 5.35 5.35 0 11.89 5.51 5.51 0
131072 32768 float sum -1 16.97 7.72 7.72 0 23.75 5.52 5.52 0
262144 65536 float sum -1 26.98 9.72 9.72 0 26.82 9.77 9.77 0
524288 131072 float sum -1 47.34 11.07 11.07 0 46.57 11.26 11.26 0
1048576 262144 float sum -1 59.87 17.51 17.51 0 59.81 17.53 17.53 0
2097152 524288 float sum -1 91.29 22.97 22.97 0 91.83 22.84 22.84 0
4194304 1048576 float sum -1 223.24 18.79 18.79 0 157.01 26.71 26.71 0
8388608 2097152 float sum -1 414.08 20.26 20.26 0 283.28 29.61 29.61 0
16777216 4194304 float sum -1 725.69 23.12 23.12 0 546.07 30.72 30.72 0
33554432 8388608 float sum -1 1249.43 26.86 26.86 0 1072.41 31.29 31.29 0
67108864 16777216 float sum -1 2166.72 30.97 30.97 0 2122.39 31.62 31.62 0
# Out of bounds values : 0 OK
# Avg bus bandwidth : 8.94738
#
# Collective test concluded: all_reduce_perf
What is broken:
NCCL multi-GPU all_reduce with P2P ENABLED (g=2, NCCL_P2P_DISABLE=0)
Using:
export NCCL_SOCKET_IFNAME=lo # also tried default, same result
export NCCL_P2P_DISABLE=0
export NCCL_DEBUG=INFO
./build/all_reduce_perf -b 8 -e 64M -f 2 -g 2
Leads to the infinite hang with 100% dual gpu load:
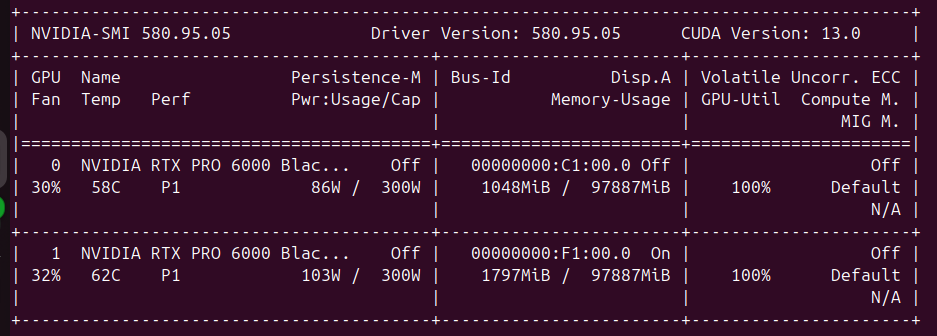
Logs tell:
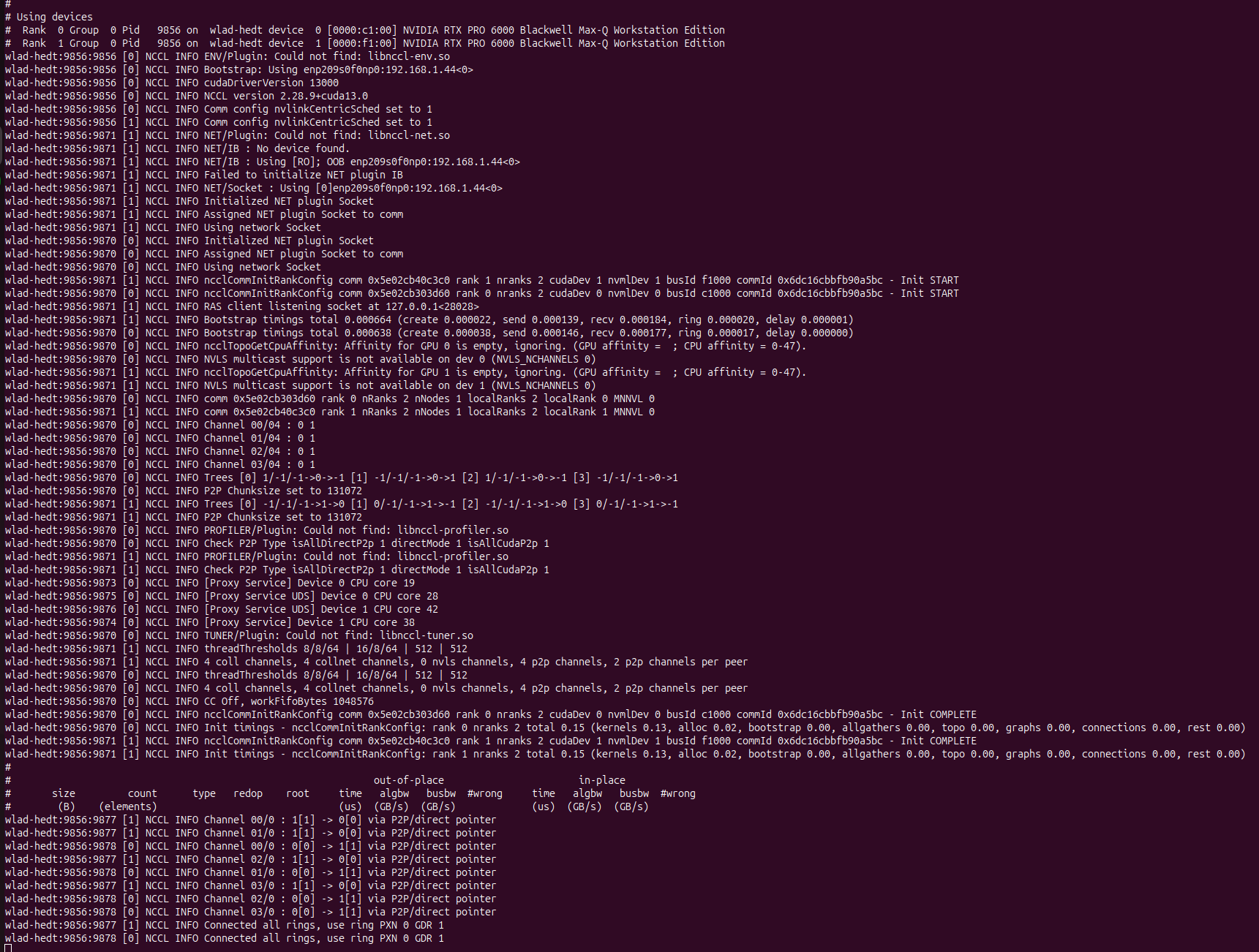
It always hangs immediately after:
- P2P is detected as fully direct (
isAllDirectP2p=1,isAllCudaP2p=1), - channels are set to
via P2P/direct pointer, - and after
Connected all rings, use ring PXN 0 GDR 1.
Same behavior with:
- ACS enabled vs disabled in BIOS,
- VPN on/off.
Questions
-
Has anyone seen a similar NCCL P2P hang on WRX90 / Threadripper PRO + RTX 6000 Blackwell (or other Blackwell Pro GPUs)?
-
Is this a known issue (or expected limitation) with NCCL 2.28.x + CUDA 13.0 + driver 580.95.05 on Blackwell?
-
Am I missing something obvious?

I would be very grateful for any recommendation or tools&drivers version combination that makes NCCL P2P work for your PRO blackwell gpus ![]()