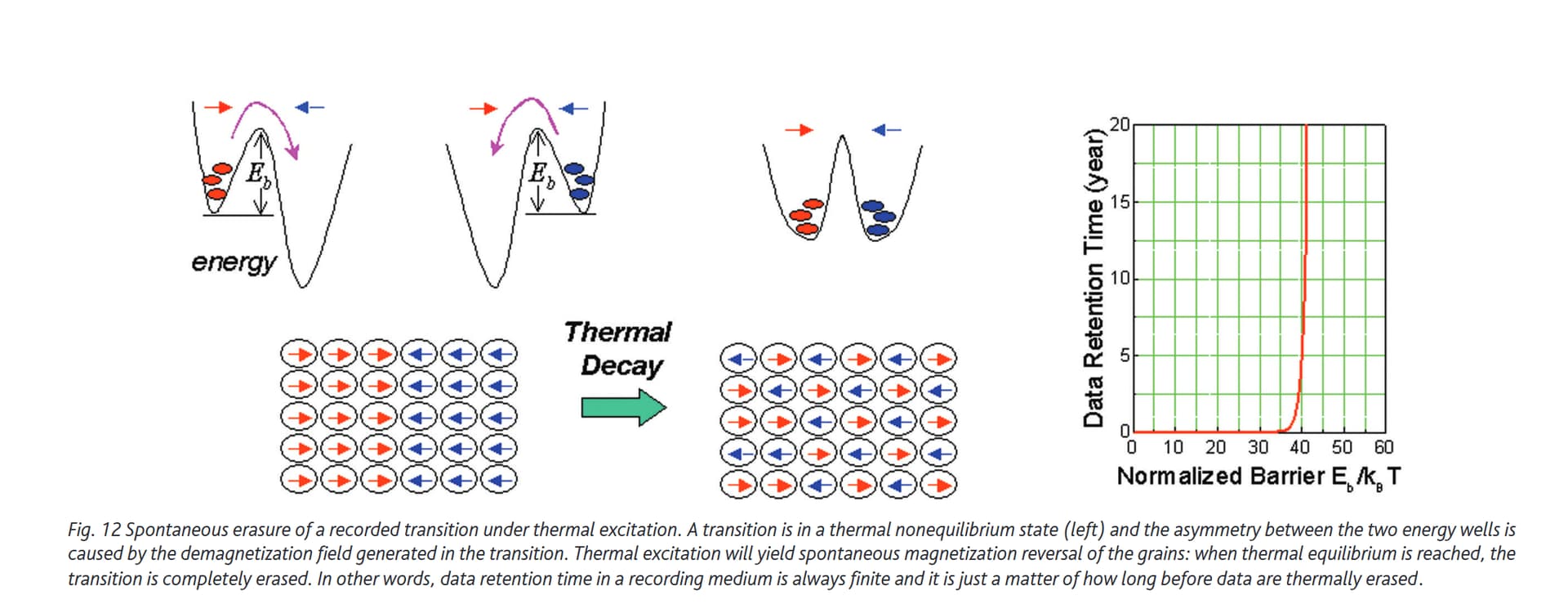
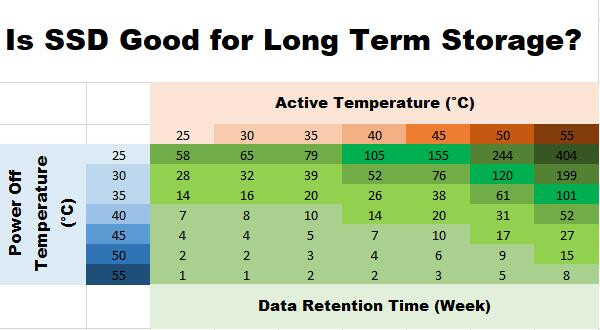
All point wendel hammers through are true and entire storage industry acts in accordance. Modular hardware raid for high speed storage is dead end for all the reasons stated above.
Same crowd that now preaches ZFS has made me try “glorious” BTRFS.
It was supposed to be a miracle. MIracle that everyone needs because … a bitrot ?
You didn’t do your research first? FFS there are no miracle technologies and btrfs is not stable solution, something widely known since 2010 even.
It might have become the next ZFS, but sun aquisition and oracle shaenagians led to development de-funding and project pretty much died.
HE still haven’t explained how is ZFS supposed to do data integrity check (T10-PI)
He did, in detail. Review videos and pay attention to details.
This isnt about trust, this is about capability. New high performance hardware raid is not being developed, as there is zero industry use for it. Older ones are absolutely incapable handling even older single enterprise nvmes, much less whole arrays of them.
Attempts like graid solution while faster are strictly worse that old enterprise solutions and do not offer any additional capability vs pure software approach. They are actually riskier.
So we dont need it, it would strictly lower performance when implemented vs what is done today - software handles parity and consistency and access direct nvme access or over switched fabrics for minimal performance loss.
That doesn’t mean hardware raid for high performance is impossible, its just is going to be hellishly complex and expensive due to speeds and latencies involved. The silicon would have to monstrous and might not even be feasible for acceptable latency cost.
Modern nvme performance is that high, that any intermediary processing element can and does incurs major performance penalties.
And since there isnt any pressing need for it, we are back to square one. Hardware raid is dead outside legacy or low cost applications. And low cost application will never have budget for good hardware raid implementation.
If there were technical and business case, broadcom would have already had a product on the market. Instead everyone is going DPU and direct access.
QED.