Gotcha.
That must be nice.
They didn’t offer that for the 100 Gbps layer. Grrr…
Same. I got into 100 Gbps IB because of a Linus Tech Tips video which was talking about how you can buy those NICs now off of eBay for 1/2 of the retail cost.
And whilst $350 might still be a lot of money to some, but in terms of $/Gbps(/port), it’s actually VERY cost effective, even if you might not be able to make full use of it (yet).
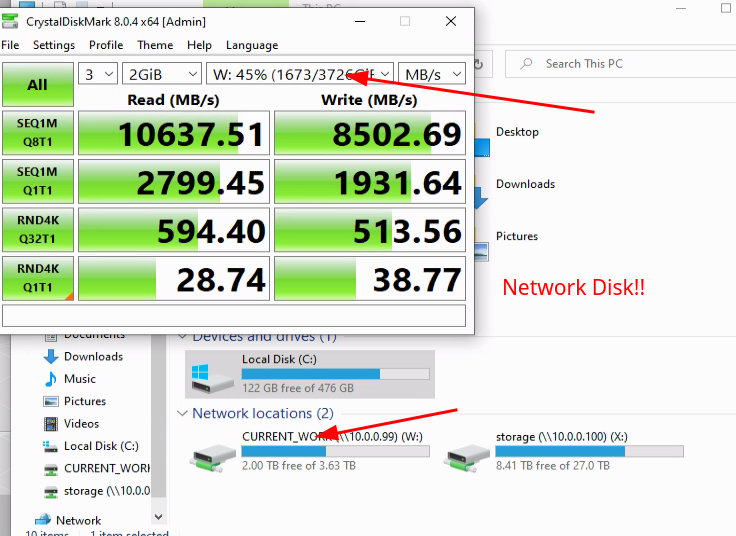
If you deployed 10 GbE and then found out that you were managing to saturate that bandwidth, then you’d have to pay for it all over again to move to something even faster.
But by deploying 100 Gbps (in my case) right off the bat, I can probably run it until newer generations of PCIe is no longer backwards compatible with PCIe 3.0 x16.
For storage services, I DOUBT that I will ever max out the bandwidth capacity.
But for HPC applications, I’ve gotten pretty darn close to it, which was why I deployed it in the first place.
(sidebar: it’s fun to scare IT directors and the likes when you tell them that the fastest networking layer that you have deployed in your home/in your basement is 100 Gbps IB. They have to scrape their jaws off the floor most of the time. That will never cease to amuse me.)
So…depending on which specific application you might be trying to dive into, I have found that, the HPC applications is actually easier (or some can be easier) to get RDMA working than for storage services.
Whilst I can’t disclose which applications I am using (as that’s under NDA), I can say that at least for one of the CFD applications, when I use it to test the network bandwidth (at least on my 100 Gbps IB), it can routely get about 80 Gbps out of it (10 GB/s).
So that’s pretty darn good.
On the FEA side of things, the measurement has not been as simple nor as straightforward to benchmark.
(The chiplet nature of the AMD Ryzen 9 5950X adds additional layers of complexity to the computer science theory in terms of what should I be able to achieve, both in terms of pure, computer science theory vs. what’s theorectically possible given the physical limitations of the hardware/architecture.)
The closest thing that I’ve been able to cook up in terms of a comparison between my old Xeon-based cluster and my new Ryzen based cluster is that the Ryzen is about 11% on average, faster in terms of time per FEA solution iteration. (My model has non linear geometry, non-linear materials, and a mix of linear and non-linear contacts, so it’s actually quite a difficult problem for FEA solvers to contend with.)
I would’ve expected a higher performance difference, but that does not appear to be the case in the actual benchmark tests that I am running with an internal case.