Context
I have a problem… almost every computer I own runs on gentoo.
I had some issues when I wanted to create HA virtualization cluster. It had to be libvirt run on gentoo (doh) and somewhat minimalistic. I picked ceph because it’s the only sensible storage solution for this scenario. I had some issues with clustering for libvirtd.
For some time I’ve used VirtualDomain from corosync/pacemaker, but It’s far from ideal.
- old project
- old python dependencies in crmsh
- pcsd is trash on gentoo
- bizarre resource script writing methods
- VirtualDomain resource is half baked, it’s ssh login methid is meh, doesn’t handle RBD images well…
Looking at VirtualDomain code scares me.
I decided to create whole new clustering solution for libvirt.

devember project
I want to write libvirt clustering program written in go.
I’ve been working on networking part of this project for some time, but I’m far from functional prototype. Maybe I’ll manage to finally write it if It’s a part of the contest.
Project is signed with my name and I’ll post the link to the repo publicly only if the project gets accepted into devember. (I can send it privately to the contest judge ofc.)
lab
3 gentoo nodes running ceph and libvirt
Architecture
- HA cluster resource manager (like corosync/pacmaker)
- tcp unencrypted traffic
-
- doesn’t scale well, but it’s not an issue for my setup
-
-
- network separation via vlan (outside of project scope)
- elections for master node
-
- predefined node hierarchy (nodes are not picked at random)
- one resource controller (libvirt)
-
- it’ll use interface in case I needed to add different ones in the future
core goals
- minimal dependencies (easier code maintenance)
- VM resource distribution and basic balance
-
- balance according to vCPU and MEM requirements
- VM migration
-
- Resource eviction from flagged node
- correct RBD image handling
-
- resource placement restrictions
- cluster emergency shutdown (manual or some UPS script)
side goals
- VM FS freezing and RBD snapshotting
- RBD image backup to normal filesystem
possible future ideas
(It’s out of scope for this devember.)
- gpu assignment to VMs (I own only one gpu lol)
- resource controller or separate system for networking
- resource controller for podman
I’m open to the feedback, but please keep in mind that this is just a hobby project.
I’m aware that there are better and more production ready system.
I’m writing my own as a learning exercise.
When does devember ends End of November or December?
2 Likes
December
You dont have to be “accepted” into Devember, just make it available on the forum (which is how I found it) - there is now an official event thread where you can list your project (if you have not done so already - not everyone is in there, its was belated after all). FYI you can get a list of all Devember2021 projects (incl. the belated event thread) by clicking on the #devember2021 tag …
This is a (mildly) huge project, I hope you suceed this year
Thanks.
I had an insanely busy December and couldn’t finish it on time. I’m still working on it, but some features may have to wait. I will have more time after I’m done with my undergrad degree.
My project grew to about ~3950 lines of codes (a about 4500 wc -l lines.
So far I have working:
- network abstraction communication module
- cluster logger module
- basic cluster resource management
-
- basic resource placement based on:
– hardware requirements of cluster resources
– health of cluster nodes
-
- ability to start and stop resources
- interface for resource controllers
-
- dummy implementation of resource controller
-
- untested libvirt controller
- cli client
-
-
- listening to cluster logs
-
What doesn’t work:
- placement algorithm doesn’t really balance resources. It remembers the last node which got assigned resource and tries to avoid placing next on on the same node.
- resource migration is not implemented.
- adding/removing/editing resources from cli
Rest of the goals I had for these project look relatively simple. RBD image operations can be implemented with simple scripts even without using direct connection to the
Screenshots and examples:
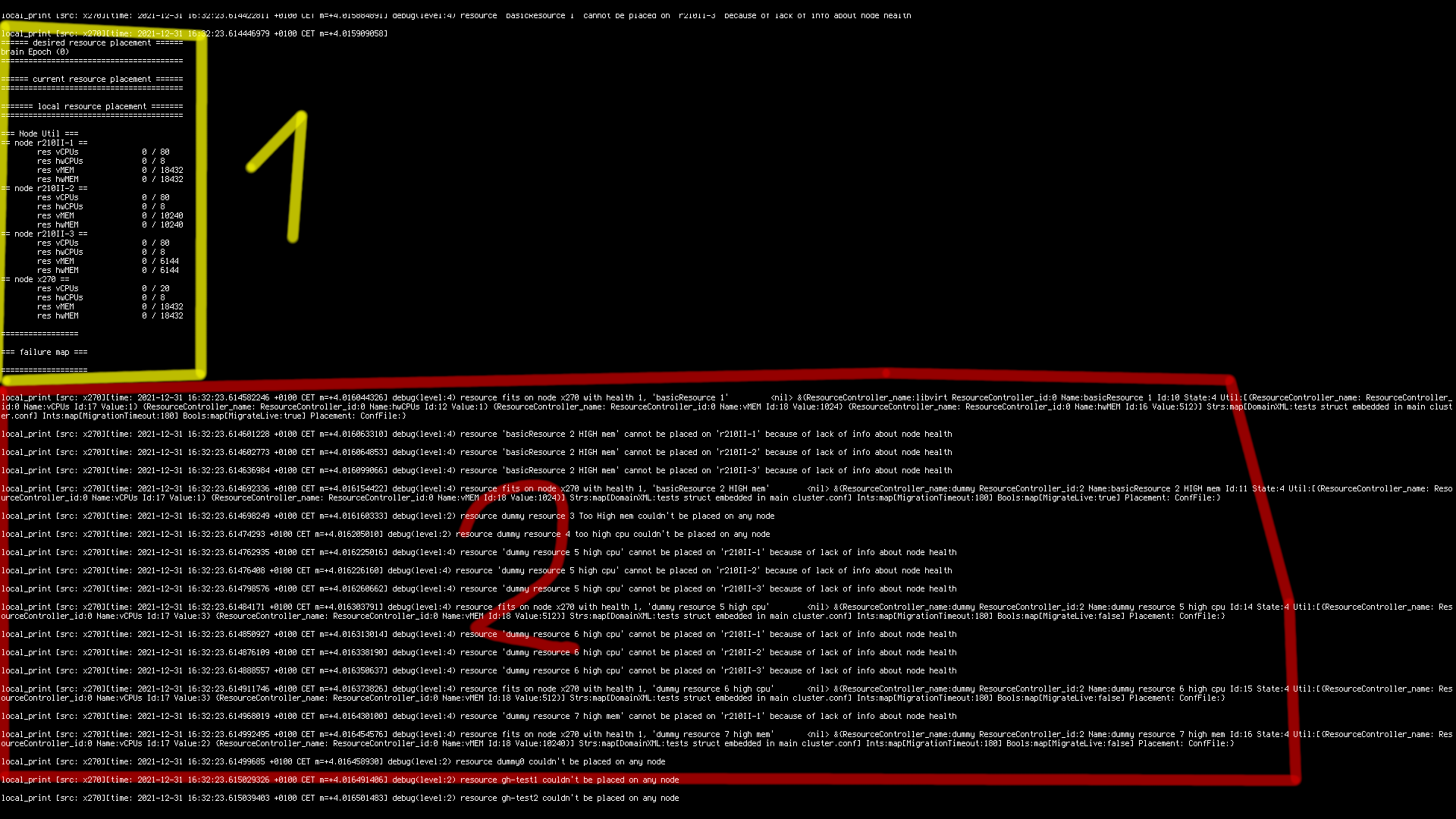
Resource placement info and balancer debug information.
On this screenshot first field is almost empty, this is the state before balancer starts placing resources.
-
General info about resource placement
– desired resource placement: placement decided by balancer
– current resource placement: resource state reported by nodes
– local placement: resources on the local nodes
– node util: info about usable “hardware” resources. This screenshot shows zero usage because cluster hasn’t assigned any. All values on the right are hard coded in the node config.
-
Debug info about resource placement
this section shows debug messages about placement algorithm trying to assign resources to nodes. Nodes r210II-1,r210II-2,r210II-3 are always rejected because they are not connected. (Screenshot local, single node debug mode)
Some resources with very high ram or cpu requirements are also rejected because they don’t fit on any available node.
-
Resource controller attempt to start to start resources. One placed libvirt resource fails to start because it doesn’t contain a real filepath to
-
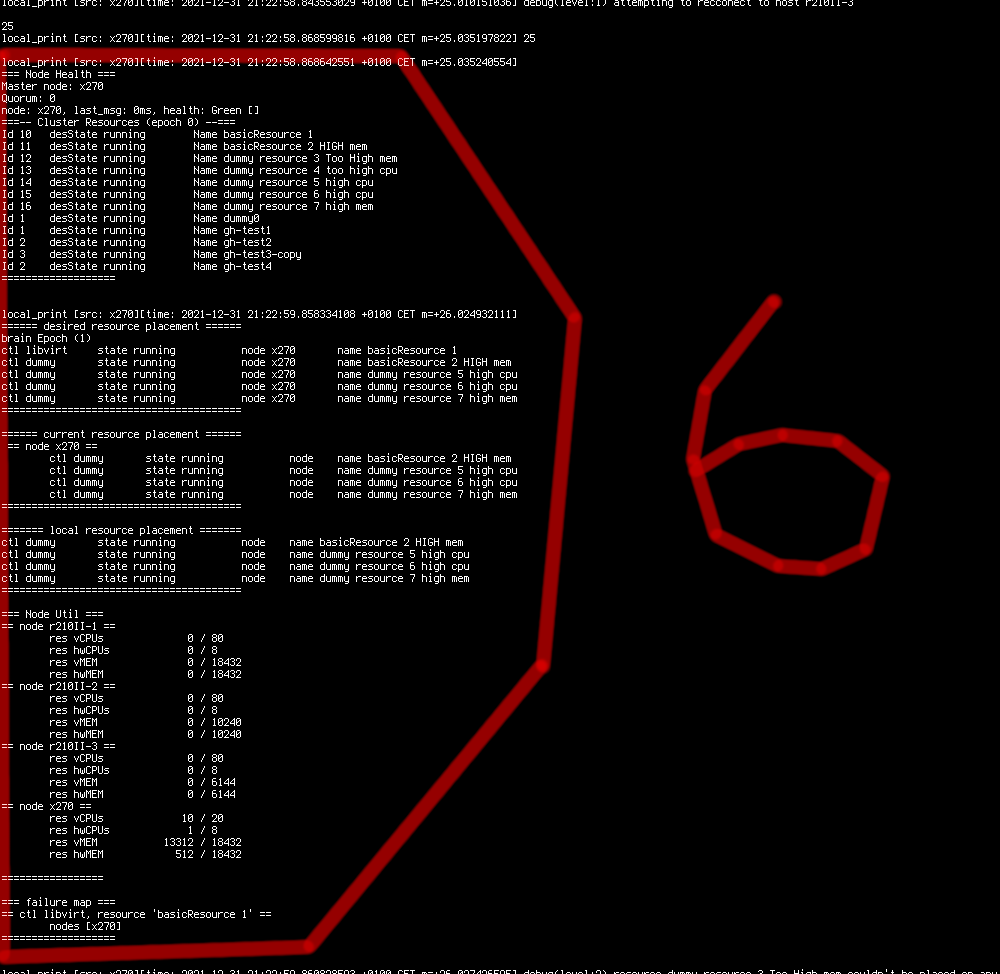
This info message from different module than message from point 1. Section node Health shows connected nodes, time of their last heartbeat message, node health. It also shows quorum value and current master node. (local debug mode, only one node)
-
Info about cluster trying to connect to other nodes.
- The same info screen shown all the info messages all previous info messages. Cluster state has been updated after resources started in section 3.
Desired state has been updated with resources placed.
Local resources has been updated from state reported by resource controller.
Current resource placement has been updated from local resources. Nodes send that into to the master node. In this case info was sent locally.
Resource utilization has been updated based on placed resources.
Failure map shows the list of failed resources. It also shows on which nodes resources failed. This allows cluster to avoid repeated placement broken resources. It remembers nodes, because problem may be local and specific to node tried.
Edit: Screenshots from single node configuration. My switch died and I’m currently testing without my real server.
2 Likes